







 本文深入探讨了Java中的HashMap、HashSet和TreeMap三种数据结构。HashMap提供快速的查找性能,但非同步;HashSet基于HashMap实现,不允许重复元素;TreeMap则按顺序存储元素,适用于有序访问。文章详细分析了HashMap的内部实现,包括容量、负载因子、扩容和树化策略,并解释了如何防止哈希碰撞攻击。同时,也介绍了HashSet如何通过哈希码和equals方法确保数据唯一性。
本文深入探讨了Java中的HashMap、HashSet和TreeMap三种数据结构。HashMap提供快速的查找性能,但非同步;HashSet基于HashMap实现,不允许重复元素;TreeMap则按顺序存储元素,适用于有序访问。文章详细分析了HashMap的内部实现,包括容量、负载因子、扩容和树化策略,并解释了如何防止哈希碰撞攻击。同时,也介绍了HashSet如何通过哈希码和equals方法确保数据唯一性。
- Hashtable 是早期 Java 类库提供的一个哈希表实现,本身是同步的,不支持 null 键和值,由于同步导致的性能开销,所以已经很少被推荐使用。
- HashMap 是应用更加广泛的哈希表实现,行为上大致上与 HashTable 一致,主要区别在于 HashMap 不是同步的,支持 null 键和值等。通常情况下,HashMap 进行 put 或者 get 操作,可以达到常数时间的性能。
- TreeMap 则是基于红黑树的一种提供顺序访问的 Map,和 HashMap 不同,它的 get、put、remove 之类操作都是 O(log(n))的时间复杂度,具体顺序可以由指定的 Comparator 来决定,或者根据键的自然顺序来判断。
- LinkedHashMap 通常提供的是遍历顺序符合插入顺序,它的实现是通过为条目(键值对)维护一个双向链表。注意,通过特定构造函数,我们可以创建反映访问顺序的实例,所谓的 put、get、compute 等,都算作“访问”
大部分使用 Map 的场景,通常就是放入、访问或者删除,而对顺序没有特别要求,HashMap 在这种情况下基本是最好的选择。HashMap 的性能表现非常依赖于哈希码的有效性,请务必掌握 hashCode 和 equals 的一些基本约定,比如:
- equals 相等,hashCode 一定要相等。
- 重写了 hashCode 也要重写 equals。
- hashCode 需要保持一致性,状态改变返回的哈希值仍然要一致。
- equals 的对称、反射、传递等特性。
HashMap 代码分析
可以看作是数组(Node<K,V>[] table)和链表结合组成的复合结构,数组被分为一个个桶(bucket),通过哈希值决定了键值对在这个数组的寻址;哈希值相同的键值对,则以链表形式存储。这里需要注意的是,如果链表大小超过阈值(TREEIFY_THRESHOLD, 8),图中的链表就会被改造为树形结构。
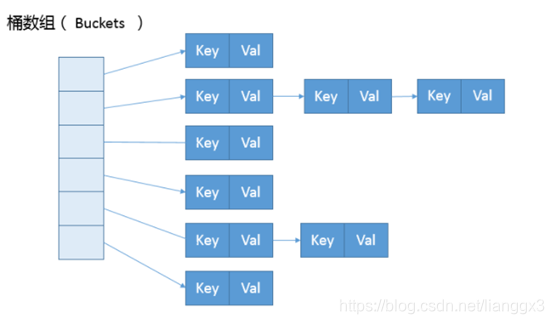
看看hashMap的构造函数
public HashMap(int initialCapacity, float loadFactor){
// ...
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
只是设置了字段,没有申请内存。再看实际塞入值的putValue函数。
final V putVal(int hash, K key, V value, boolean onlyIfAbent,
boolean evit) {
Node<K,V>[] tab; Node<K,V> p; int , i;
if ((tab = table) == null || (n = tab.length) = 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == ull)
tab[i] = newNode(hash, key, value, nll);
else {
// ...
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for first
treeifyBin(tab, hash);
// ...
}
}
- 如果表格是 null,resize 方法会负责初始化它,这从 tab = resize() 可以看出。
- resize 方法兼顾两个职责,创建初始存储表格,或者在容量不满足需求的时候,进行扩容(resize)。
- 在放置新的键值对的过程中,如果发生下面条件,就会发生扩容。
- 具体键值对在哈希表中的位置(数组 index)取决于下面的位运算:i = (n - 1) & hash
看看resize逻辑
final Node<K,V>[] resize() {
// ...
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACIY &&
oldCap >= DEFAULT_INITIAL_CAPAITY)
newThr = oldThr << 1; // double there
// ...
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else {
// zero initial threshold signifies using defaultsfults
newCap = DEFAULT_INITIAL_CAPAITY;
newThr = (int)(DEFAULT_LOAD_ATOR* DEFAULT_INITIAL_CAPACITY;
}
if (newThr ==0) {
float ft = (float)newCap * loadFator;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);
}
threshold = neThr;
Node<K,V>[] newTab = (Node<K,V>[])new Node[newap];
table = n;
// 移动到新的数组结构 e 数组结构
}
不考虑极端情况(容量理论最大极限由 MAXIMUM_CAPACITY 指定,数值为 1<<30,也就是 2 的 30 次方),我们可以归纳为:
- 门限值等于(负载因子)x(容量),如果构建 HashMap 的时候没有指定它们,那么就是依据相应的默认常量值。
- 门限通常是以倍数进行调整 (newThr = oldThr << 1),我前面提到,根据 putVal 中的逻辑,当元素个数超过门限大小时,则调整 Map 大小。
- 扩容后,需要将老的数组中的元素重新放置到新的数组,这是扩容的一个主要开销来源。
容量、负载因子和树化
容量和负载系数决定了可用的桶的数量,空桶太多会浪费空间,如果使用的太满则会严重影响操作的性能。极端情况下,假设只有一个桶,那么它就退化成了链表,完全不能提供所谓常数时间存的性能。
预先设置的容量需要满足,大于“预估元素数量 / 负载因子”,同时它是 2 的幂数
树化:
本质上这是个安全问题。因为在元素放置过程中,如果一个对象哈希冲突,都被放置到同一个桶里,则会形成一个链表,会严重影响存取的性能。构造哈希冲突的数据,恶意代码就可以利用这些数据大量与服务器端交互,导致服务器端 CPU 大量占用,这就构成了哈希碰撞拒绝服务攻击
问题
说一下Hashset的实现原理?
Hashset是基于Hashsetp实现的,Hashset的值俘放于hashMap的key上,
hashMap的value统一为present,Hashset的实现比较简单.Hashset的操作其本上都是直接调用底层hashMap的相关方法来完成,Hashset不允许重复的值.
Hashset如何检查重复?Hashset是如何保证数据不可重复的
1、向Hashset中add元索时,判断元索是否存在的依据,不仅要比较Hash值,同时还要结台equals方法比较。
2、Hashset中的add()方法会使用HashMap的put方法
3。HashMap的key是唯一的,由源码可以看出Hashset添加进去的值就是作为HashMap的key,并且在HashMap中如果K/V相同时,会用新的V遭盖掉旧的V,然后返回旧的V。所以不会重复(先比较hashcode再比较equaIs).

















 315
315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









