







1.删除重复元素
# 自动生成dataframe的函数
def make_df(index,cols):
df = pd.DataFrame({col:[col + str(i) for i in index]for col in cols})
df.index = index
return df
df = make_df([1,2,3,4],list('ABCD'))
df.iloc[0]=df.iloc[1]
df
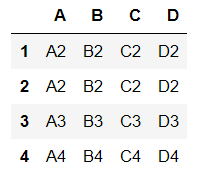
- 使用duplicated()函数检测重复的行,返回元素为布尔类型的Series对象,每个元素对应一行,如果该行不是第一次出现,则元素为True
df.duplicated(keep='first') - 通过是否是重复元素可以筛选出重复元素的一行
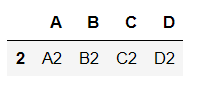
df[df.duplicated(keep='first')] - 可以利用逻辑运算对条件取反,从而过滤重复元素
# 逻辑运算.
# np.logical_and/or/not/xor异或.
cond = df.duplicated(keep='first')
df[np.logical_not(cond)] # 或者 df[~cond]

- 使用drop_duplicates()函数删除重复的行
df.drop_duplicates()

- 如果一行中只有某三列相同时,可以设置subset
df.iloc[0,3]='D3'
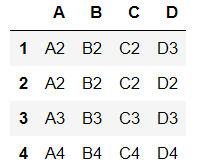
df.drop_duplicates(subset=['A','B','C'])
2.映射
映射的含义:创建一个映射关系列表,把values元素和一个特定的标签或者字符串绑定
需要使用字典:
map = { 'label1':'value1', 'label2':'value2', ... }
包含三种操作:
- replace()函数:替换元素
- 最重要:map()函数:新建一列
- rename()函数:替换索引
1) replace()函数: 替换元素
- 使用replace()函数,对values进行替换操作
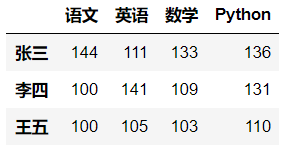
index=['张三','李四','王五']
columns=['语文','英语','数学','Python']
data = np.random.randint(80,150,size=(3,4))
df = pd.DataFrame(data=data,columns=columns,index=index)
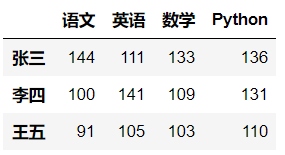
- 调用replace()
df.replace({91:100})
- replace还可以用来替换NaN
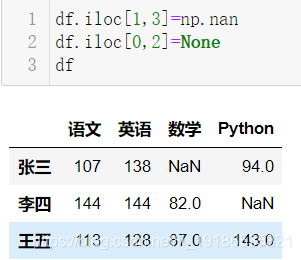
df=df.replace({np.nan:120})
2) map()函数: 新建一列
- 使用map()函数,由已有的列生成一个新列,适合处理某一单独的列。
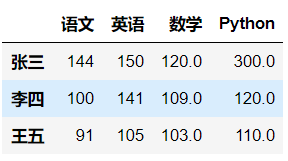
- 新增一列
# map 最常见的用法,用来根据已有的数据新建一列数据
# 匹配不上不None
mapping={120:123,109:90,103:110}
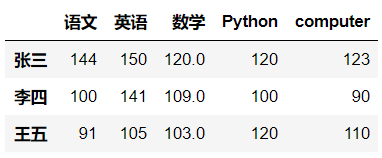
df['computer']=df['数学'].map(mapping)
df
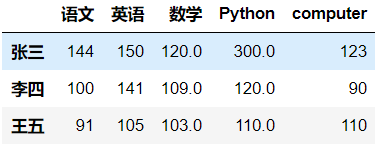
- 修改一列
mapping={300:120,120:100,110:120}
df['Python'] = df['Python'].map(mapping)
df
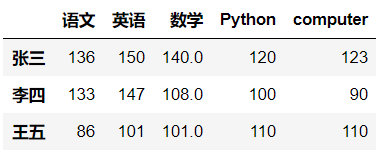
- map()函数中可以使用lambda函数
df['数学'] = df['数学'].map(lambda score:score+20)
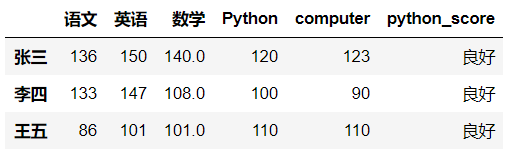
- 使用函数
def score(x):
if x > 120:
return '优秀'
elif x >= 80:
return '良好'
else:
return '及格'
df['python_score'] = df['Python'].map(score)
3) rename()函数: 替换索引
-
替换索引
df=df.rename(index={'张三':'Mr zhang','李四':'Mr li'})
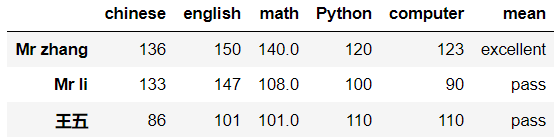
-
替换列名
df=df.rename(columns={'语文':'chinese','数学':'math','英语':'english'})
3.异常值检测和过滤
常用方法:
使用describe()函数查看每一列的描述性统计量
使用std()函数可以求得DataFrame对象每一列的标准差
根据每一列的标准差,对DataFrame元素进行过滤。
借助any()函数, 测试是否有True,有一个或以上返回True,反之返回False
对每一列应用筛选条件,去除标准差太大的数据
删除特定索引df.drop(labels,inplace = True)
如: 新建一个形状为10000*3的标准正态分布的DataFrame(np.random.randn),去除掉所有满足以下情况的行:其中任一元素绝对值大于3倍标准差.
df = pd.DataFrame(data=np.random.randn(10000,3))
cond = df.abs()>(df.std()*3)
df[~cond]
4.抽样
- 使用.take()函数排序
- 可以借助np.random.permutation()函数随机排序
- 当DataFrame规模足够大时,直接使用np.random.randint()函数,就配合take()函数实现随机抽样(有放回)
df.take(np.random.randint(0,3,size=3)) - 不放回抽样
df.take(np.random.permutation([0,1,2]))
- 当DataFrame规模足够大时,直接使用np.random.randint()函数,就配合take()函数实现随机抽样(有放回)
5.数据聚合
数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值。
数据分类处理:
- 分组:先把数据分为几组
- 用函数处理:为不同组的数据应用不同的函数以转换数据
- 合并:把不同组得到的结果合并起来
数据分类处理的核心:
groupby()函数

















 1928
1928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









