







 多元线性回归建立多个特征与响应之间的线性关系,用于预测和理解特征影响。评估涉及线性相关性、方差齐性、正态分布假设及避免多重共线性。选择合适变量的方法包括向前选择、向后选择和向前向后法。虚拟变量陷阱要注意避免,通过创建m-1个虚拟变量处理类别特征。初步分析表明变量剔除可能影响结果。
多元线性回归建立多个特征与响应之间的线性关系,用于预测和理解特征影响。评估涉及线性相关性、方差齐性、正态分布假设及避免多重共线性。选择合适变量的方法包括向前选择、向后选择和向前向后法。虚拟变量陷阱要注意避免,通过创建m-1个虚拟变量处理类别特征。初步分析表明变量剔除可能影响结果。
多元线性回归尝试通过一个线性方程来适配观测数据,这个线性方程是在两个及以上的特征和响应之间构建的一个关系。
多元线性回归的实现步骤和简单线性回归很相似,在评价部分有所不同。
可以用来找出预测结果上哪个特征影响力最大,以及变量之间是如何互相关联的。
回归分析的假设前提:
1. 特征值和预测值应该是线性相关的
2. 保持误差项的方差齐性: 即误差项的分散(方差)必须等同
3. 多元正态分布: 假定残差符合正态分布
4. 缺少多重共线性: 假设数据有极少甚至没有多重共线性。当特征不是相互独立时,会引发多重共线性
注意:
过多的变量可能会降低模型的精确度,尤其是如果存在一些对结果无关的变量,或者存在对其他变量造成很大影响的变量时。
可以通过一些方法选择合适的变量:
1. 向前选择法(逐次加使RSS【残差平方和】最小的自变量)
2. 向后选择法 (逐次扔掉p值【一种在原假设为真的前提下出现观察样本以及更极端情况的概率】最大的变量)
3. 向前向后法: 结合向前选择和向后选择法,先使用向前或向后,再使用另外一种方法筛选一遍,直至最后无论怎么筛选模型变量都不再发生变化
虚拟变量陷阱:
虚拟变量是指两个及以上变量之间高度相关的情形。简而言之,就是存在一个能够被其他变量预测出的变量。
eg: 一个特征值为男,女。不加判断定义虚拟变量时会存在连个虚拟变量。但实际情况是可以用是否是女性来定义男性。
可以通过类别变量-1 来剔除重复。假设一个特征值有m 个类别,可以定义m-1个虚拟变量,减掉的可作为参照值
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = pd.read_csv(r'd:\Users\lulib\Desktop\data.txt',sep='\t')
X = data.iloc[:,:-1].values
Y = data.iloc[:,-1].values
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder = LabelEncoder()
X[: , -1] = labelencoder.fit_transform(X[ : , -1])
onehotencoder = OneHotEncoder(categorical_features = [3]) ## 设置需要虚拟转换的维度索引
X = X[: , 1:] ## 剔除虚拟维度陷阱
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split( X,Y,test_size = 0.2, random_state = 0)
from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor = regressor.fit(X_train,Y_train)
Y_pred = regressor.predict(X_test)
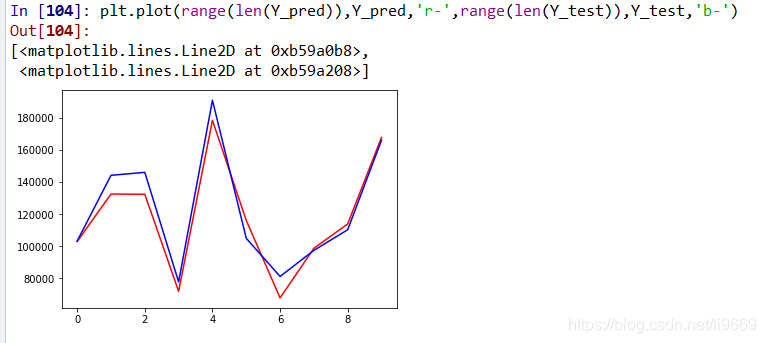
plt.plot(range(len(Y_pred)),Y_pred,'r-',range(len(Y_test)),Y_test,'b-')可以看到结果并不似很好,初步认为是和变量是否有剔除有关


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









