







 文章讲述了在生产环境中,Spark历史服务器sparkhistoryserver因SparkStreaming任务导致网络流量过高问题。作者建议升级到Spark3、启用日志滚动或调整更新间隔以减少性能开销。
文章讲述了在生产环境中,Spark历史服务器sparkhistoryserver因SparkStreaming任务导致网络流量过高问题。作者建议升级到Spark3、启用日志滚动或调整更新间隔以减少性能开销。
生产环境遇到一台机器网络流量占用高告警
由于监控只有机器总的网络流量,没有具体进程的
于是只能登陆服务器,安装nethogs:yum install nethogs
然后执行nethogs命令查看进程流量

观察到主要是spark history server这个进程占用流量高(最高达到800M/s)
但是我们spark任务其实不是很多,且大多是离线,占用这么高有点不太正常
查看spark history server日志:
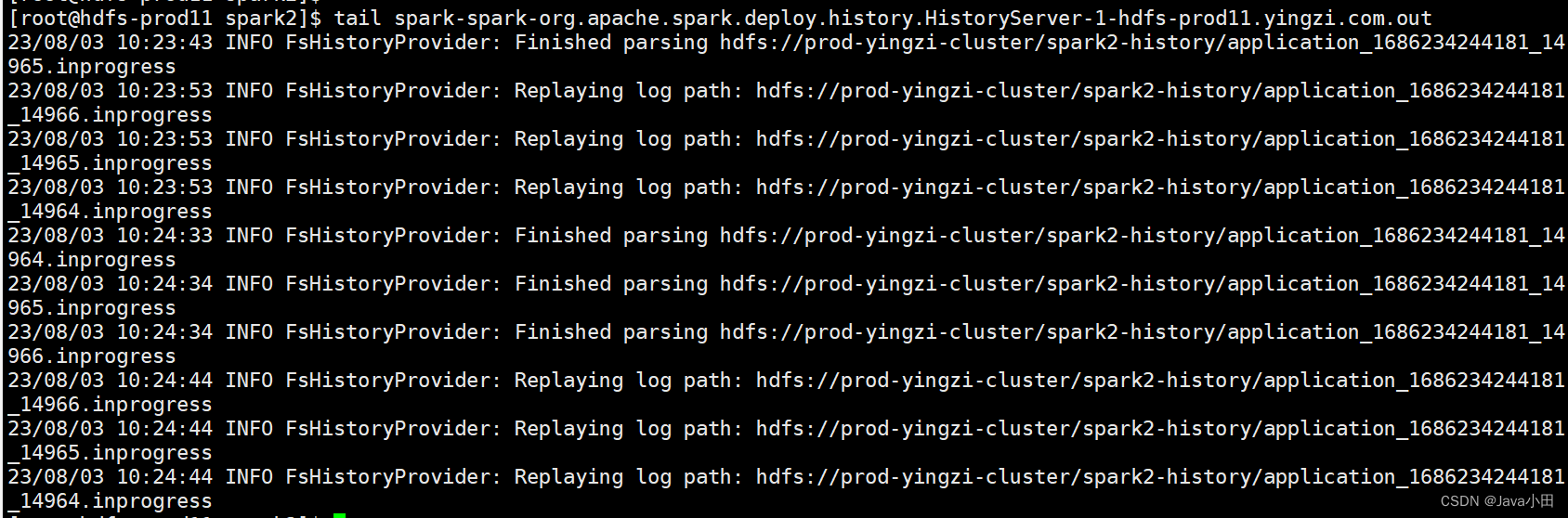
发现每间隔10-30秒就会读取spark2-history目录下的文件,且每次读取的都是相同的几个文件
抽取几个文件查看:

大小基本都在9G以上
spark版本使用的是2.3.1
结合日志打印和代码,发现spark history server会定期(spark.history.fs.update.interval配置,默认10s)执行checkForLogs逻辑,检查目录下的文件是否有变动,对有变动的文件进行解析及事件回放
代码入口在FsHistoryProvider.startPolling()方法中
这里由于是spark streaming任务,且spark2不支持history文件滚动生成,文件大小会一直往上增长,每次全量读取文件,会带来比较严重的性能开销。
这里建议最好升级到spark3并开启日志滚动输出,见我之前的文章:https://blog.youkuaiyun.com/li281037846/article/details/129302902
要是不方便升级,那就最好定期对spark streaming任务进行重启,避免日志文件一直增长
还有就是把spark.history.fs.update.interval配置的值调大一点(牺牲history的实时性),降低读取日志文件的频率


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









