






ZooKeeper 是一个开源的分布式应用程序协调服务器,其为分布式系统提供一致性服务。其一致性是通过基于 Paxos 算法的 ZAB 协议完成的。其主要功能包括:配置维护、分布式同步、集群管理、分布式事务等。
我现在有一个秒杀服务,并发量太大单机系统承受不住,那我加几台服务器也 一样 提供秒杀服务,这个时候就是 Cluster 集群 。
但是,我现在换一种方式,我将一个秒杀服务 拆分成多个子服务 ,比如创建订单服务,增加积分服务,扣优惠券服务等等,然后我将这些子服务都部署在不同的服务器上 ,这个时候就是 Distributed 分布式 。

一致性问题
设计一个分布式系统必定会遇到一个问题—— 因为分区容忍性(partition tolerance)的存在,就必定要求我们需要在系统可用性(availability)和数据一致性(consistency)中做出权衡 。这就是著名的 CAP 定理。
理解起来其实很简单,比如说把一个班级作为整个系统,而学生是系统中的一个个独立的子系统。这个时候班里的小红小明偷偷谈恋爱被班里的大嘴巴小花发现了,小花欣喜若狂告诉了周围的人,然后小红小明谈恋爱的消息在班级里传播起来了。当在消息的传播(散布)过程中,你抓到一个同学问他们的情况,如果回答你不知道,那么说明整个班级系统出现了数据不一致的问题(因为小花已经知道这个消息了)。而如果他直接不回答你,因为整个班级有消息在进行传播(为了保证一致性,需要所有人都知道才可提供服务),这个时候就出现了系统的可用性问题。
而上述前者就是 Eureka 的处理方式,它保证了AP(可用性),后者就是我们今天所要讲的 ZooKeeper 的处理方式,它保证了CP(数据一致性)。
一致性协议和算法
2PC(两阶段提交),3PC(三阶段提交),Paxos算法等等。
2PC(两阶段提交)
现在很多数据库都是采用的两阶段提交协议来完成 分布式事务 的处理。
在两阶段提交中,主要涉及到两个角色,分别是协调者和参与者。
第一阶段:当要执行一个分布式事务的时候,事务发起者首先向协调者发起事务请求,然后协调者会给所有参与者发送 prepare 请求(其中包括事务内容)告诉参与者你们需要执行事务了,如果能执行我发的事务内容那么就先执行但不提交,执行后请给我回复。然后参与者收到 prepare 消息后,他们会开始执行事务(但不提交),并将 Undo 和 Redo 信息记入事务日志中,之后参与者就向协调者反馈是否准备好了。
第二阶段:第二阶段主要是协调者根据参与者反馈的情况来决定接下来是否可以进行事务的提交操作,即提交事务或者回滚事务。
比如这个时候 所有的参与者 都返回了准备好了的消息,这个时候就进行事务的提交,协调者此时会给所有的参与者发送 Commit 请求 ,当参与者收到 Commit 请求的时候会执行前面执行的事务的 提交操作 ,提交完毕之后将给协调者发送提交成功的响应。
而如果在第一阶段并不是所有参与者都返回了准备好了的消息,那么此时协调者将会给所有参与者发送 回滚事务的 rollback 请求,参与者收到之后将会 回滚它在第一阶段所做的事务处理 ,然后再将处理情况返回给协调者,最终协调者收到响应后便给事务发起者返回处理失败的结果。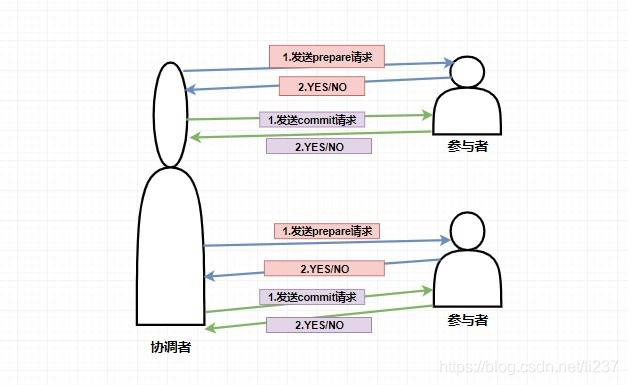
事实上它只解决了各个事务的原子性问题,随之也带来了很多的问题。
- 单点故障问题,如果协调者挂了那么整个系统都处于不可用的状态了。
- 阻塞问题,即当协调者发送 prepare请求,参与者收到之后如果能处理那么它将会进行事务的处理但并不提交,这个时候会一直占用着资源不释放,如果此时协调者挂了,那么这些资源都不会再释放了,这会极大影响性能。
- 数据不一致问题,比如当第二阶段,协调者只发送了一部分的 commit请求就挂了,那么也就意味着,收到消息的参与者会进行事务的提交,而后面没收到的则不会进行事务提交,那么这时候就会产生数据不一致性问题。
3PC(三阶段提交)
- CanCommit阶段:协调者向所有参与者发送 CanCommit 请求,参与者收到请求后会根据自身情况查看是否能执行事务,如果可以则返回 YES 响应并进入预备状态,否则返回 NO 。
- PreCommit阶段:协调者根据参与者返回的响应来决定是否可以进行下面的 PreCommit 操作。如果上面参与者返回的都是 YES,那么协调者将向所有参与者发送 PreCommit 预提交请求,参与者收到预提交请求后,会进行事务的执行操作,并将 Undo 和Redo 信息写入事务日志中 ,最后如果参与者顺利执行了事务则给协调者返回成功的响应。如果在第一阶段协调者收到了 任何一个 NO的信息,或者 在一定时间内并没有收到全部的参与者的响应,那么就会中断事务,它会向所有参与者发送中断请求(abort),参与者收到中断请求之后会立即中断事务,或者在一定时间内没有收到协调者的请求,它也会中断事务。
- DoCommit阶段:这个阶段其实和 2PC 的第二阶段差不多,如果协调者收到了所有参与者在 PreCommit 阶段的 YES 响应,那么协调者将会给所有参与者发送 DoCommit 请求,参与者收到 DoCommit 请求后则会进行事务的提交工作,完成后则会给协调者返回响应,协调者收到所有参与者返回的事务提交成功的响应之后则完成事务。若协调者在 PreCommit 阶段 收到了任何一个 NO 或者在一定时间内没有收到所有参与者的响应 ,那么就会进行中断请求的发送,参与者收到中断请求后则会 通过上面记录的回滚日志 来进行事务的回滚操作,并向协调者反馈回滚状况,协调者收到参与者返回的消息后,中断事务。
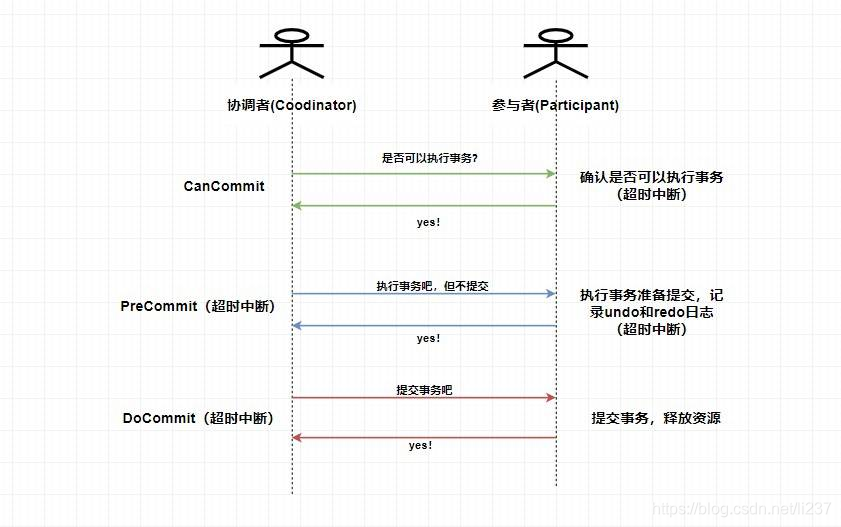
协调者在指定时间内为。未收到全部的确认消息则进行事务中断的处理,这样能 减少同步阻塞的时间
3PC 通过一系列的超时机制很好的缓解了阻塞问题,但是最重要的一致性并没有得到根本的解决,比如在 PreCommit 阶段,当一个参与者收到了请求之后其他参与者和协调者挂了或者出现了网络分区,这个时候收到消息的参与者都会进行事务提交,这就会出现数据不一致性问题。
Paxos 算法
在 Paxos 中主要有三个角色,分别为 Proposer提案者、Acceptor表决者、Learner学习者。Paxos 算法和 2PC 一样,也有两个阶段,分别为 Prepare 和 accept 阶段。
1.prepare 阶段
-
Proposer提案者:负责提出 proposal,每个提案者在提出提案时都会首先获取到一个 具有全局唯一性的、递增的提案编号N,即在整个集群中是唯一的编号N,然后将该编号赋予其要提出的提案,在第一阶段是只将提案编号发送给所有的表决者。
-
Acceptor表决者:每个表决者在 accept 某提案后,会将该提案编号N记录在本地,这样每个表决者中保存的已经被 accept 的提案中会存在一个编号最大的提案,其编号假设为 maxN。每个表决者仅会 accept 编号大于自己本地 maxN 的提案,在批准提案时表决者会将以前接受过的最大编号的提案作为响应反馈给 Proposer 。
2.accept 阶段
-
当一个提案被 Proposer 提出后,如果 Proposer 收到了超过半数的 Acceptor 的批准(Proposer本身同意),那么此时 Proposer 会给所有的 Acceptor 发送真正的提案(你可以理解为第一阶段为试探),这个时候Proposer 就会发送提案的内容和提案编号。
-
表决者收到提案请求后会再次比较本身已经批准过的最大提案编号和该提案编号,如果该提案编号 大于等于 已经批准过的最大提案编号,那么就 accept 该提案(此时执行提案内容但不提交),随后将情况返回给 Proposer 。如果不满足则不回应或者返回 NO 。
-
当 Proposer 收到超过半数的 accept ,那么它这个时候会向所有的 acceptor 发送提案的提交请求。需要注意的是,因为上述仅仅是超过半数的 acceptor 批准执行了该提案内容,其他没有批准的并没有执行该提案内容,所以这个时候需要向未批准的 acceptor 发送提案内容和提案编号并让它无条件执行和提交,而对于前面已经批准过该提案的 acceptor 来说 仅仅需要发送该提案的编号 ,让acceptor 执行提交就行了。
-
而如果 Proposer 如果没有收到超过半数的 accept 那么它将会将 递增 该 Proposal 的编号,然后 重新进入Prepare 阶段
paxos 算法的死循环问题
- 比如说,此时提案者 P1 提出一个方案 M1,完成了 Prepare 阶段的工作,这个时候 acceptor 则批准了 M1,但是此时提案者 P2 同时也提出了一个方案 M2,它也完成了 Prepare 阶段的工作。然后 P1 的方案已经不能在第二阶段被批准了(因为 acceptor 已经批准了比 M1 更大的 M2),所以 P1 自增方案变为 M3 重新进入 Prepare 阶段,然后 acceptor ,又批准了新的 M3 方案,它又不能批准 M2 了,这个时候 M2 又自增进入 Prepare 阶段。。。
就这样无休无止的永远提案下去,这就是 paxos 算法的死循环问题。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









