







文章目录
- 一、注册中心设计原理
- 二、 作业调度器初始化
- 三、作业方法的执行
- 3.1、源码
- 3.2、源码整体执行流程图:
- 3.3、模版方法解析--检查作业执行环境
- 3.4、模版方法解析--选举主节点,获取分片并包装到shardingContexts中返回
- 3.5、模版方法解析--beforeJobExecuted
- 3.6、模版方法解析--执行具体任务
- 3.7、模版方法解析--如果有一次错过执行
- 四、总结
一、注册中心设计原理
1、配置zk作为注册中心
@Configuration
public class JobRegistryCenterConfig {
@Value("${zookeeper.server.address}")
private String serverList;
//这里设置bean初始化就调用init方法
@Bean(initMethod = "init")
public ZookeeperRegistryCenter regCenter() {
String namespace = "elastic-job-dev";
//
return new ZookeeperRegistryCenter(new ZookeeperConfiguration(serverList, namespace));
}
}
2、看下这个ZookeeperRegistryCenter对象的主要成员变量和方法
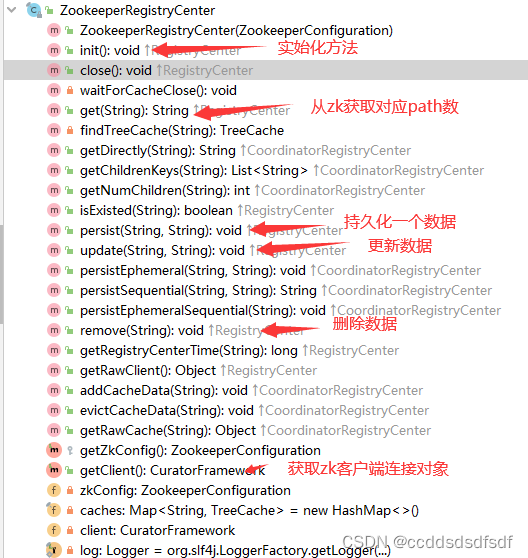
注册中心对象,主要实始化了操作zk的客户端,和一些操作zk数据的方法
caches对象:
Map<String, TreeCache>类型的caches对象,用来保存Zookeeper路径下节点数据的缓存对象,用来实现对Zookeeper节点的监听操作。
init方法:主要就是实始化了zk的操作客户端CuratorFramework对象。
后面elastic-job 使用JobNodeStorage类型来调用注册中心接口为我们开放的操作方法。
二、 作业调度器初始化
如果我们要注册一个Job到zk。那么通常使用下面代码
@Bean(name = "simpleTestJob", initMethod = "init")
protected JobScheduler simpleJobScheduler() {
return new SpringJobScheduler(this, super.regCenter,
getLiteJobConfiguration(TaskJobEnum.simpleTestJob, this.getClass()));
}
用@Bean的方法,创建一个SpringJobScheduler对象,然后再看调用它的init方法,看下这个类的集成关系
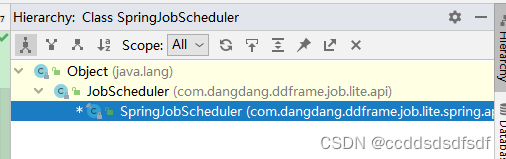
它的父类是:JobScheduler,调用了父类的Init方法:
/**
* 初始化作业.
*/
public void init() {
//更新作业配置
LiteJobConfiguration liteJobConfigFromRegCenter = schedulerFacade.updateJobConfiguration(liteJobConfig);
//设置分片总数
JobRegistry.getInstance().setCurrentShardingTotalCount(liteJobConfigFromRegCenter.getJobName(), liteJobConfigFromRegCenter.getTypeConfig().getCoreConfig().getShardingTotalCount());
//创建作业调度控制器
JobScheduleController jobScheduleController = new JobScheduleController(
createScheduler(), createJobDetail(liteJobConfigFromRegCenter.getTypeConfig().getJobClass()), liteJobConfigFromRegCenter.getJobName());
//创建作业调度控制器
JobRegistry.getInstance().registerJob(liteJobConfigFromRegCenter.getJobName(), jobScheduleController, regCenter);
//注册启动信息
schedulerFacade.registerStartUpInfo(!liteJobConfigFromRegCenter.isDisabled());
//注册启动信息
jobScheduleController.scheduleJob(liteJobConfigFromRegCenter.getTypeConfig().getCoreConfig().getCron());
}
1、更新作业配置
LiteJobConfiguration liteJobConfigFromRegCenter = schedulerFacade.updateJobConfiguration(liteJobConfig);
这个方法主要做了2件事:
1、持久化本地作业配置到zk
2、从zk获取最新作业配置
/**
* 更新作业配置.
*
* @param liteJobConfig 作业配置
* @return 更新后的作业配置
*/
public LiteJobConfiguration updateJobConfiguration(final LiteJobConfiguration liteJobConfig) {
configService.persist(liteJobConfig);
return configService.load(false);
}
1.1、持久化本地作业配置到zk
/**
* 持久化分布式作业配置信息.
*
* @param liteJobConfig 作业配置
*/
public void persist(final LiteJobConfiguration liteJobConfig) {
checkConflictJob(liteJobConfig);
//如果作业配置信息不存在,或本地覆盖=true,那么更新这个作业节点的信息为 本地配置信息。 否则不覆盖
if (!jobNodeStorage.isJobNodeExisted(ConfigurationNode.ROOT) || liteJobConfig.isOverwrite()) {
jobNodeStorage.replaceJobNode(ConfigurationNode.ROOT, LiteJobConfigurationGsonFactory.toJson(liteJobConfig));
}
}
可查看zk信息,作业配置就存在 jobName/config path下,如图:

节点job配置信息
{
"jobName":"testJob",
"jobClass":"com.smart.job.TestJob",
"jobType":"SIMPLE",
"cron":"0 */1 * * * ?",
"shardingTotalCount":5,
"shardingItemParameters":"0\u003dA,1\u003dB,2\u003dC,3\u003dD,4\u003dE",
"jobParameter":"",
"failover":false,
"misfire":true,
"description":"",
"jobProperties":{
"job_exception_handler":"com.dangdang.ddframe.job.executor.handler.impl.DefaultJobExceptionHandler",
"executor_service_handler":"com.dangdang.ddframe.job.executor.handler.impl.DefaultExecutorServiceHandler"
},
"monitorExecution":true,
"maxTimeDiffSeconds":-1,
"monitorPort":-1,
"jobShardingStrategyClass":"",
"reconcileIntervalMinutes":10,
"disabled":false,
"overwrite":false
}
1.2、从zk读取作业配置,这里fromCache=false
这里代码很简单,就是从zk的testJob/config 路径下读取这个节点的信息,返回。代码略…
1.3、总结为什么这样做
这样做主要是,如果我们通过zk控台 修改了配置,而且本地覆盖=false的话,那么就以zk上的作业配置信息为准。如果本地覆盖=true,那么就用本地配置覆盖zk上的配置。
那如果是覆盖模式,或者当从zk控台修改了这个作业配置信息时,如果通知其它客户端呢? 实际上通过节点监听即可。
2、设置分片总数
实际上就是将上步从zk上获取到的作业配置信息中的 分片总数,写到本地JobRegistry持有map对象中,key=jobName。
currentShardingTotalCountMap.put(jobName, currentShardingTotalCount);
实际上JobRegistry 有以下几个本地map
//作业调度控制器映射KEY为作业名,值为作业调度控制器
private Map<String, JobScheduleController> schedulerMap = new ConcurrentHashMap<>();
//作业协调注册中心映射,KEY为作业名,值为协调注册中心
private Map<String, CoordinatorRegistryCenter> regCenterMap = new ConcurrentHashMap<>();
//作业实例映射,KEY为作业名值为作业实例对象
private Map<String, JobInstance> jobInstanceMap = new ConcurrentHashMap<>();
//作业的运行状态,true为正在运行
private Map<String, Boolean> jobRunningMap = new ConcurrentHashMap<>();
//作业分片总数映射,KEY为作业名,值为分片总数
private Map<String, Integer> currentShardingTotalCountMap = new ConcurrentHashMap<>();
3、创建作业调度控制器
elastic-job使用Quartz为每个作业创建单机执行的调度器对象JobScheduleController
//创建作业调度控制器
JobScheduleController jobScheduleController = new JobScheduleController(
//对应scheduler对象
createScheduler(),
//对应jobDetail对象
createJobDetail(liteJobConfigFromRegCenter.getTypeConfig().getJobClass()),
//对应作业触发器标示对象
liteJobConfigFromRegCenter.getJobName());
这个对象实际上就是对Quartz框架Scheduler对象的管理。看下它的主要结构如下:
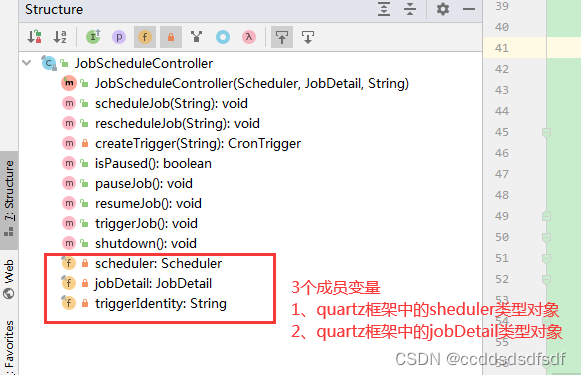
主要方法:
暂停作业,启动作业,触发作业,关闭作业等等。
scheduler:调度器,这个是来源org.quartz包下面的类型, Quartz Scheduler的主接口为调度器负责整个定时系统的调度内部提供了调度,启动,暂停,关闭恢复作业等方法,是我们使用Quartz操作作业的主接口。
jobDetail:作业详情接口,也就是作业的元数据接口,主要存储作业的标示,作业描述,作业执行类,作业自定义参数等方法。后期调度器可以通过作业元数据获取到作业信息进行执行作业。
triggerIdentity:作业触发器的唯一标示,后期可以使用这个标示来获取触发器对象进行判断作业执行状态,重新调度作业,本系统中使用作业名字来做为触发器的唯一标示。
Scheduler对象的创建是通过 createScheduler()方法
JobDetail对象的创建则是通过createJobDetail方法
对应作业触发器的标示则使用作业名字来进行标示
3.1、Scheduler 调度对象的创建
private Scheduler createScheduler() {
Scheduler result;
try {
StdSchedulerFactory factory = new StdSchedulerFactory();
factory.initialize(getBaseQuartzProperties());
//工厂创建调度器 这里调度器对象类型为StdScheduler
result = factory.getScheduler();
//添加触发监听器
result.getListenerManager().addTriggerListener(schedulerFacade.newJobTriggerListener());
} catch (final SchedulerException ex) {
throw new JobSystemException(ex);
}
return result;
}
//调度器工厂的基本属性初始化
private Properties getBaseQuartzProperties() {
Properties result = new Properties();
result.put("org.quartz.threadPool.class", org.quartz.simpl.SimpleThreadPool.class.getName());
result.put("org.quartz.threadPool.threadCount", "1");
result.put("org.quartz.scheduler.instanceName", liteJobConfig.getJobName());
result.put("org.quartz.jobStore.misfireThreshold", "1");
result.put("org.quartz.plugin.shutdownhook.class", JobShutdownHookPlugin.class.getName());
result.put("org.quartz.plugin.shutdownhook.cleanShutdown", Boolean.TRUE.toString());
return result;
}
3.2、JobDetail 作业信息对象的创建
private JobDetail createJobDetail(final String jobClass) {
JobDetail result = JobBuilder.newJob(LiteJob.class).withIdentity(liteJobConfig.getJobName()).build();
result.getJobDataMap().put(JOB_FACADE_DATA_MAP_KEY, jobFacade);
Optional<ElasticJob> elasticJobInstance = createElasticJobInstance();
if (elasticJobInstance.isPresent()) {
result.getJobDataMap().put(ELASTIC_JOB_DATA_MAP_KEY, elasticJobInstance.get());
} else if (!jobClass.equals(ScriptJob.class.getCanonicalName())) {
try {
result.getJobDataMap().put(ELASTIC_JOB_DATA_MAP_KEY, Class.forName(jobClass).newInstance());
} catch (final ReflectiveOperationException ex) {
throw new JobConfigurationException("Elastic-Job: Job class '%s' can not initialize.", jobClass);
}
}
return result;
}
-
其实这跟我们用quartz创建一个job是一样的。首先我定义的job需要实现quartz框架的Job接口。重写execute方法,当定时任务触发时,就会调用这个job的execute方法。
这里我们创建了LiteJob,为作业对象。 -
获取我们实际定义的elasticJob对象
//这个方法由子类完成,获取,获取我们实际定义的JobScheduler持有elasticJob对象。elasticJob对象就是我们自定义的Job对象,需要集成simpleJOb,flowJob或scriptJob
Optional<ElasticJob> elasticJobInstance = createElasticJobInstance();
向LiteJob作业传递定制化ElasticJob弹性作业对象。
- 向LiteJob作业对象传递jobFacade 对象
result.getJobDataMap().put(JOB_FACADE_DATA_MAP_KEY, jobFacade);
3.3、再来看看,如何由LiteJob对象,调用我们实际上创建的elasticJob3个类型的对象
先回顾下作业的创建代码:
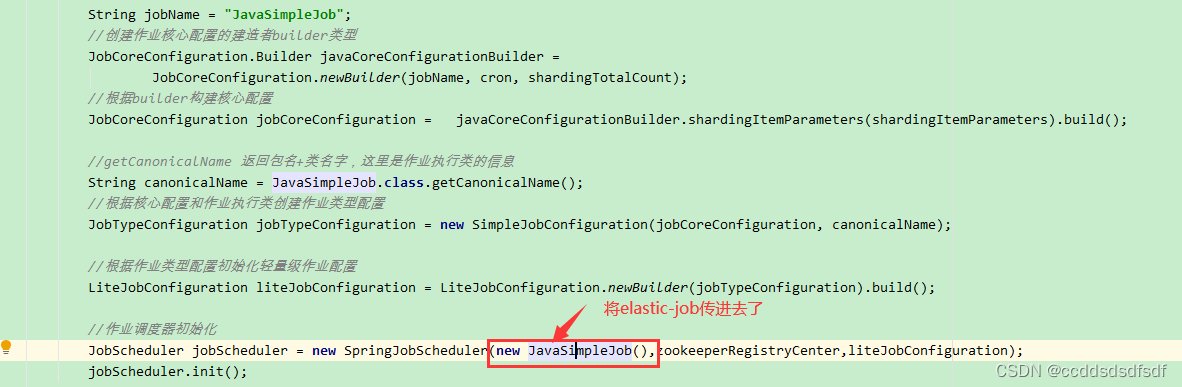
1、创建了SpringJobScheduler对象返回,这个对象继承了JobScheduler,持有ElasticJob对象,就我们自定义的job对象。
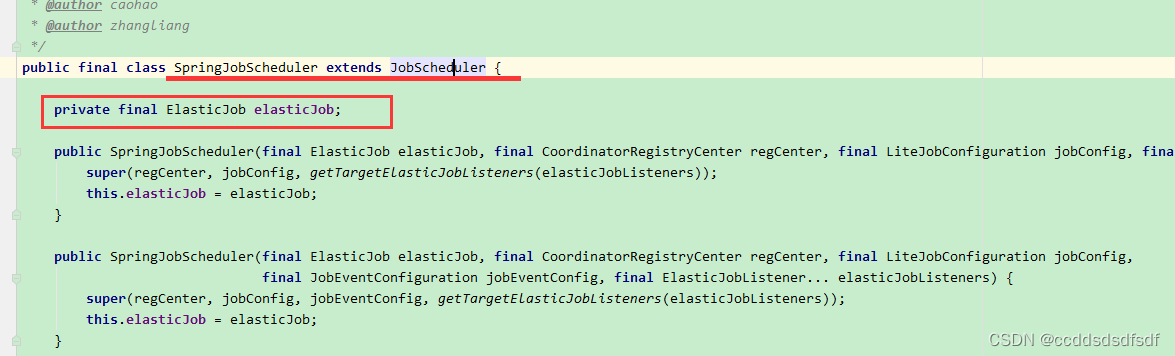
2、再调用它的JobScheduler init方法,初始化
init方法,会执行到 JobDetail createJobDetail(final String jobClass) ,
Optional<ElasticJob> elasticJobInstance = createElasticJobInstance();由子类实现。这里就是SpringJobScheduler返回了 ElasticJob对象,就返回了我们自定义的Job对象。
3、当quartz触发时,会调用LiteJob的execute方法
public void execute(final JobExecutionContext context) throws JobExecutionException {
JobExecutorFactory.getJobExecutor(elasticJob, jobFacade).execute();
}
- 获取jobExector,然后执行它的execute方法,注意参数的传入
/**
* 获取作业执行器.
*
* @param elasticJob 分布式弹性作业
* @param jobFacade 作业内部服务门面服务
* @return 作业执行器
*/
@SuppressWarnings("unchecked")
public static AbstractElasticJobExecutor getJobExecutor(final ElasticJob elasticJob, final JobFacade jobFacade) {
if (null == elasticJob) {
return new ScriptJobExecutor(jobFacade);
}
if (elasticJob instanceof SimpleJob) {
return new SimpleJobExecutor((SimpleJob) elasticJob, jobFacade);
}
if (elasticJob instanceof DataflowJob) {
return new DataflowJobExecutor((DataflowJob) elasticJob, jobFacade);
}
throw new JobConfigurationException("Cannot support job type '%s'", elasticJob.getClass().getCanonicalName());
}
根据作业类型返回不同类的执行器,这里返回SimpleJobExecutor。
调用它的execute方法,这里子类没有execute方法,而调用了父类的AbstractElasticJobExecutor的execute方法。看下AbstractElasticJobExecutor的类关系:
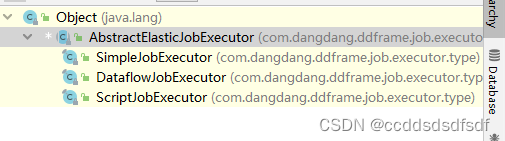
是这3个执行器的公共父类,很明显这里肯定用了模板模式。
4、AbstractElasticJobExecutor#execute方法
主要代码省略。。。后面再讲, 最后会调用子类方法:
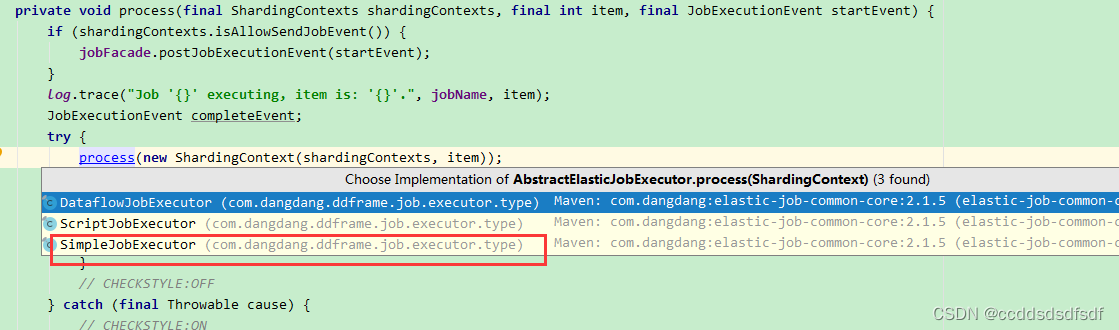
然后,查看SimpleJobExecutor#process方法,最后就调用到我们自定义的job对象的execute方法。
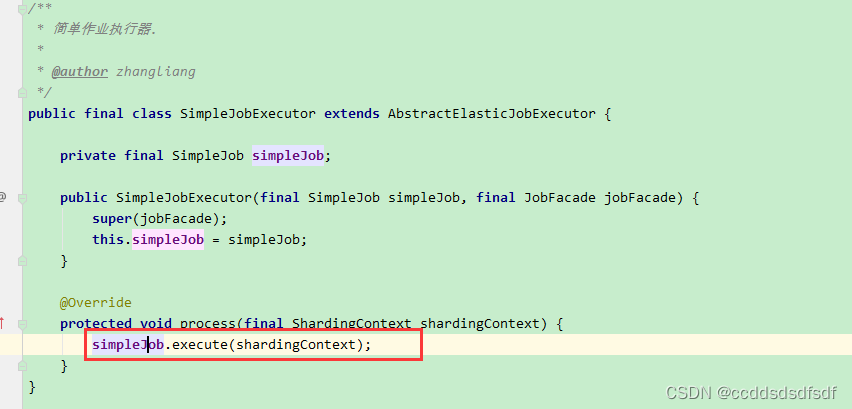
5、总结
系统初始化每个作业的时候都会为当前作业创建独立的Quartz调度器对象来执行各自的作业,互不影响,进行作业线程隔离,并且执行当前作业的线程只有一个。
4、添加作业调度控制器
在上面创建完作业调度器后,然后再添加作业调度控制器
5、注册作业启动信息
schedulerFacade.registerStartUpInfo(!liteJobConfigFromRegCenter.isDisabled());
/**
* 注册作业启动信息.
*
* @param enabled 作业是否启用
*/
public void registerStartUpInfo(final boolean enabled) {
listenerManager.startAllListeners();
leaderService.electLeader();
serverService.persistOnline(enabled);
instanceService.persistOnline();
shardingService.setReshardingFlag();
monitorService.listen();
if (!reconcileService.isRunning()) {
reconcileService.startAsync();
}
}
注册的作业启动信息主要有:
1、开启所有监听器
2、选举主节点
3、持久化作业服务器上线信息
4、持久化作业运行实例上线相关信息
5、设置需要重新分片的标记
6、初始化作业监听服务
5.1、开启监听
监听器主要是用来:订阅调度作业写入到zk节点状态的变更,其中包含了主节点,分片信息,作业运行信息,触发信息等节点状态的监听,在分布式场景下如果有其他机器下的作业对节点变更或者针对作业进行了操作,当前进行订阅的进程节点可以及时感知到并及时做出合理的操作。
/**
* 开启所有监听器.
*/
public void startAllListeners() {
//主节点选举监听管理器
electionListenerManager.start();
//分片监听管理器
shardingListenerManager.start();
//失效转移监听管理器
failoverListenerManager.start();
//幂等性监听管理器
monitorExecutionListenerManager.start();
//运行实例关闭监听管理器
shutdownListenerManager.start();
//作业触发监听管理器
triggerListenerManager.start();
//重调度监听管理器
rescheduleListenerManager.start();
//保证分布式任务全部开始和结束状态监听管理器
guaranteeListenerManager.start();
//注册连接状态监听器
jobNodeStorage.addConnectionStateListener(regCenterConnectionStateListener);
}
5.2、主节点选举—为每个Job都选了个主节点
主节点的作用:当我们设置了一个作业的分片数,那就是说有几台机器会执行这个任务,那主节点就是用来按一定的分配置规则 来分配置,哪些实例会执行这些作业。
quartz是本地触发的,每台实例到点就会执行, 但执行前会判断 当前机器是否 分配置了 分片信息,如果有分片信息 才执行,否返回。
例如:部署4台 服务,但只设置了一个分片,那么主节点只会分配一台机器 有分片信息。那么最终执行任务的机器就只有一台。
又如:部署了1台服务,但设置了2个分片,那么主节点会分配这台机器有2个分片信息。那么这个机器会执行2次这个任务(当然是多线程执行)
注意这里是为每个Job都选了一个主节点,而不是 所有任务都是一个主节点
如何在多个节点中选主节点
当多个进行同步进行先主时,先获取分 带顺序的分布锁,只序号最小的节点才会获取锁,有执行的权力,然后判断如果 没有主节点(判断leader/ealection/instance无值),那么就 执行选主,成功后 将选的主节点ip写到这个路径下,然后释放锁。 后面获取到锁的进程,先判断是否有 主节点,发现已经存在 就不执行选主操作。
//选主 源码如下
leaderService.electLeader();
/**
* 选举主节点.
*/
public void electLeader() {
log.debug("Elect a new leader now.");
//这里参传入是:leader/election/latch, 传入一个回调方法
jobNodeStorage.executeInLeader(LeaderNode.LATCH, new LeaderElectionExecutionCallback());
log.debug("Leader election completed.");
}
/**
* 在主节点执行操作.
*
* @param latchNode 分布式锁使用的作业节点名称
* @param callback 执行操作的回调
*/
public void executeInLeader(final String latchNode, final LeaderExecutionCallback callback) {
//根据客户端对象和监听路径来创建主节点选举对象
try (LeaderLatch latch = new LeaderLatch(getClient(), jobNodePath.getFullPath(latchNode))) {
//调用start方法开始选举获取锁
latch.start();
//调用start方法开始选举获取锁
latch.await();
//获取到锁成功后开始执行回调方法,这里执行对象是参数传递过来的
callback.execute();
//CHECKSTYLE:OFF
} catch (final Exception ex) {
//CHECKSTYLE:ON
handleException(ex);
}
}
//选主节点成功后,回调
class LeaderElectionExecutionCallback implements LeaderExecutionCallback {
@Override
public void execute() {
//主节点:leader/election/instance
if (!hasLeader()) {
//主节点为leader/election/instance 值为作业的实例信息
jobNodeStorage.fillEphemeralJobNode(LeaderNode.INSTANCE, JobRegistry.getInstance().getJobInstance(jobName).getJobInstanceId());
}
}
}
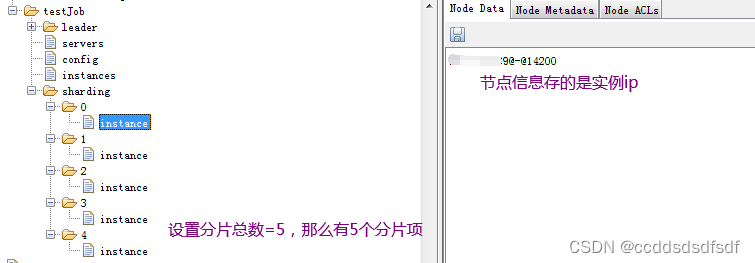
主节点创建成功后,节点信息如下:
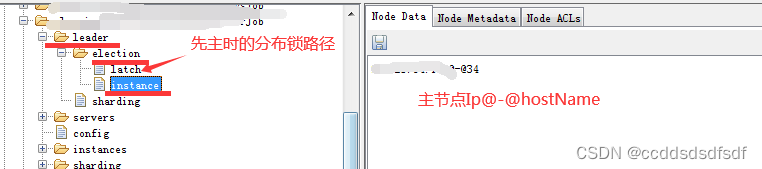
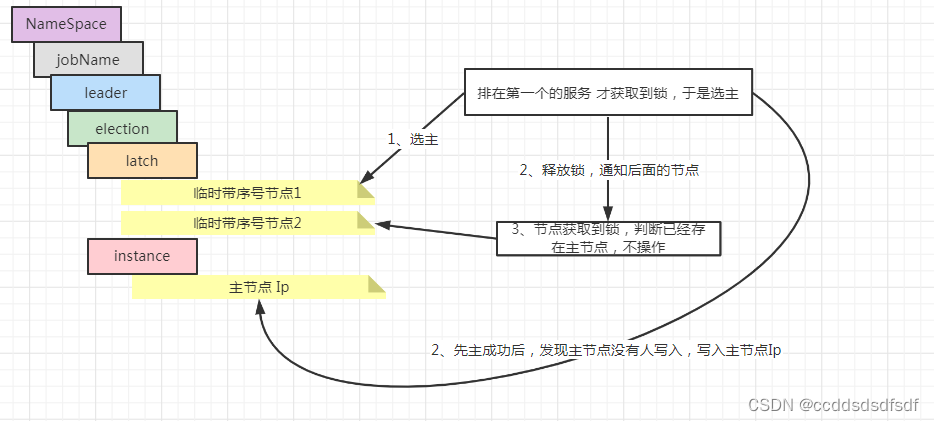
5.3、持久化作业服务器上线信息&&持久化作业运行实例上线相关信息
持久化作业服务器上线信息
主要将作业信息 持久化到 jobName/servers/ip 路径上。这里持久化是持久节点

持久化作业运行实例上线相关信息
注意这个方法 持久化是临时节点
public void persistOnline() {
jobNodeStorage.fillEphemeralJobNode(instanceNode.getLocalInstanceNode(), "");
}
路径为:instances/jobInstanceId
jobInstanceId为:jobInstanceId = IpUtils.getIp() + DELIMITER + ManagementFactory.getRuntimeMXBean().getName().split("@")[0];

services和intance 路径信息区别
持久的servers子节点用来存储作业实例信息的状态比如禁用还是启用。
临时的instances节点可以用来标示哪个机器的作业进程在运行,在线的进程与Zookeeper保持连接临时节点存在,下线的进程则临时节点被自动移除。
5.4、设置需要重新分片的标记
主节点什么时候分配置分片呢? 需要一个标志何时需要分片标记。就是在作业启动的时候 业设置的。
真正执行分片的逻辑是在作业到了触发时间执行作业时才做的。
三、作业方法的执行
3.1、源码
作业的触发实际是通过quartz定时来调用,当到达配置的时间点后,那么就会调用LibJob的execute方法。现在来看下,模版方法AbstractElasticJobExecutor#execute具体实现。
/**
* 执行作业.
*/
public final void execute() {
try {
//1、检查作业执行环境
jobFacade.checkJobExecutionEnvironment();
} catch (final JobExecutionEnvironmentException cause) {
jobExceptionHandler.handleException(jobName, cause);
}
//2、选举主节点,获取分片
ShardingContexts shardingContexts = jobFacade.getShardingContexts();
if (shardingContexts.isAllowSendJobEvent()) {
jobFacade.postJobStatusTraceEvent(shardingContexts.getTaskId(), State.TASK_STAGING, String.format("Job '%s' execute begin.", jobName));
}
//3、错过执行作业重新触发处理
if (jobFacade.misfireIfRunning(shardingContexts.getShardingItemParameters().keySet())) {
if (shardingContexts.isAllowSendJobEvent()) {
jobFacade.postJobStatusTraceEvent(shardingContexts.getTaskId(), State.TASK_FINISHED, String.format( "Previous job '%s' - shardingItems '%s' is still running, misfired job will start after previous job completed.", jobName, shardingContexts.getShardingItemParameters().keySet()));
}
return;
}
try {
//4、执行前信息处理
jobFacade.beforeJobExecuted(shardingContexts);
//CHECKSTYLE:OFF
} catch (final Throwable cause) {
//CHECKSTYLE:ON
jobExceptionHandler.handleException(jobName, cause);
}
//5、执行作业
execute(shardingContexts, JobExecutionEvent.ExecutionSource.NORMAL_TRIGGER);
//6、错过作业重新触发
while (jobFacade.isExecuteMisfired(shardingContexts.getShardingItemParameters().keySet())) {
jobFacade.clearMisfire(shardingContexts.getShardingItemParameters().keySet());
execute(shardingContexts, JobExecutionEvent.ExecutionSource.MISFIRE);
}
//7、失效转移处理
jobFacade.failoverIfNecessary();
try {
//8、执行后处理
jobFacade.afterJobExecuted(shardingContexts);
//CHECKSTYLE:OFF
} catch (final Throwable cause) {
//CHECKSTYLE:ON
jobExceptionHandler.handleException(jobName, cause);
}
}
3.2、源码整体执行流程图:
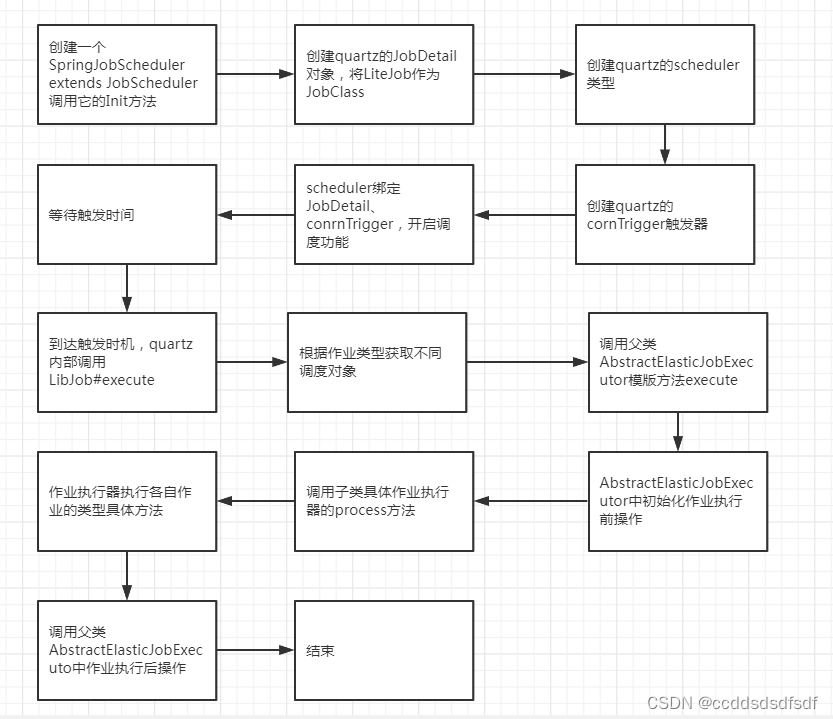
3.3、模版方法解析–检查作业执行环境
检查执行环境,实际就是:检查本机与注册中心的时间误差秒数是否在允许范围.
调度程序关键就是在指定时间触发调度作业,如果存在机器的时间不准的情况,就会导致调度作业不能按理想的时间触发,如何保证服务器的时间准确性,这里通过计算调度作业进程所在机器与Zookeeper进程所在机器之间的时间差来验证服务器时间的准确性。
默认是-1:不校验。源码省略。。。
3.4、模版方法解析–选举主节点,获取分片并包装到shardingContexts中返回
ShardingContexts shardingContexts = jobFacade.getShardingContexts();
1、为什么要选主节点,前面已经说过,主节点2个作用:
1、第一个是通过选主节点来进行分片,来执行作业
2、第二个地方是选主节点来执行失效转移的作业
2、什么是分片
分片(Sharding)将一个数据分成两个或多个较小的块,称为逻辑分片(logical shards)。通过分片可以一个大作业拆分成子问题。
比如:
有一个任务需要处理200条数据,现有2台服务器 都部署了这个任务,那么我们可将这200条数据拆分,每台服务器处理100条,这个可以提高并行速度。 让Id是奇数是数据交给job1,id是偶数的数据交给Job2。 数据拆分需要依靠自己。
查数据的时可以 id%shardingItem。 不同服务的shardingItem不同,服务A=0,服务B=1。那么当不同服务去执行这个sql时就可以得到不同的数据。
又如:
仍旧是2台机器,想要将任务拆分成10份,则可以将分片总数设置为10 ,则作业遍历数据的可以是这样的:每片分到的分片项应为ID%10,如果只有两台服务器A,B,而服务器A被分配到分片项0,1,2,3,4 服务器B被分配到分片项5,6,7,8,9,直接的结果就是服务器A遍历与0,1,2,3,4相关的数据;服务器B遍历ID与5,6,7,8,9相关的数据。
3、代码解析
@Override
public ShardingContexts getShardingContexts() {
//获取这个job的配置信息,判断是否开启了失效转移
boolean isFailover = configService.load(true).isFailover();
if (isFailover) {
//如果开启了失效转移,获取需要本作业服务器的执行的 失效转移分片项集合
//由哪些分片执行这些失效的作业,也是由主节点选的。
List<Integer> failoverShardingItems = failoverService.getLocalFailoverItems();
if (!failoverShardingItems.isEmpty()) {
return executionContextService.getJobShardingContext(failoverShardingItems);
}
}
如果当前需要分片则选举一个作业主主节点,作业主节点来执行分片的逻辑,将分片项按分片算法拆分给当前在线的进程实例
shardingService.shardingIfNecessary();
//获取当前机器被分配到的分片项,移除无效分片。
List<Integer> shardingItems = shardingService.getLocalShardingItems();
if (isFailover) {
shardingItems.removeAll(failoverService.getLocalTakeOffItems());
}
移除被设置为不可见状态的分片项
shardingItems.removeAll(executionService.getDisabledItems(shardingItems));
//将分片项封装到上下文对象中
return executionContextService.getJobShardingContext(shardingItems);
}
4、分片具体代码-- shardingService.shardingIfNecessary();
public void shardingIfNecessary() {
//先获取当前可用实例
List<JobInstance> availableJobInstances = instanceService.getAvailableJobInstances();
//判断分片状态
if (!isNeedSharding() || availableJobInstances.isEmpty()) {
return;
}
//非主节点if判断结果为true,自旋等待主节点分片完毕,主节点进行分片,如果主节点不存在则先抢占主节点
if (!leaderService.isLeaderUntilBlock()) {
blockUntilShardingCompleted();
return;
}
//主节点:等待上次执行的作业执行完毕。 executionService.hasRunningItems() 如何有一个while,直到执行完后 退出,继续执行下面代码
waitingOtherJobCompleted();
//主节点:拉取作业最新分片配置信息
LiteJobConfiguration liteJobConfig = configService.load(false);
//获取分片总数
int shardingTotalCount = liteJobConfig.getTypeConfig().getCoreConfig().getShardingTotalCount();
log.debug("Job '{}' sharding begin.", jobName);
//主节点:分片开始,先设置一个临时节点,表示主节点正在执行分片操作
jobNodeStorage.fillEphemeralJobNode(ShardingNode.PROCESSING, "");
//主节点:重置分片节点信息清理历史数据
resetShardingInfo(shardingTotalCount);
//获取分片策略算法
JobShardingStrategy jobShardingStrategy = JobShardingStrategyFactory.getStrategy(liteJobConfig.getJobShardingStrategyClass());
//主节点:使用Zookeeper事务进行分片,将分片操作 包含到一个事务中,这个操作还包括:生成分片,将分片写入jobName/sharding/{item}/instance 路径下,删除sharding/necessary,processing 路径
jobNodeStorage.executeInTransaction(new PersistShardingInfoTransactionExecutionCallback(jobShardingStrategy.sharding(availableJobInstances, jobName, shardingTotalCount)));
log.debug("Job '{}' sharding complete.", jobName);
}

4.1、如果正在选举主节点,那么等到主节点选举完成
4.2、分片的提前是等待所有正在运行的Job执行完成,以保证幂等
//主节点:等待上次执行的作业执行完毕。
//有一个while,直到执行完后 退出,继续执行下面代码
waitingOtherJobCompleted();
5、是否需要分片,状态是以分片标示节(leader/sharding/necessary)存在来决定的,哪些地方写了这个节点数据?
是否需要分片,状态是以分片标示节(leader/sharding/necessary)存在来决定的,看下哪些地方设置了需要分片分片节点:
-
ShardingListenerManager监听器管理器中分片总数和服务器状态变化的时候则会创建需节点重新分片。
-
诊断服务中当前分片中存在未上线的实例时候写入重新分片标记。
-
初始化作业注册启动信息registerStartUpInfo的时候如果分片节点不存在情况下则会写入重新分片标记。
6、PersistShardingInfoTransactionExecutionCallback回调方法
当分片策略执行分片后,这个传参数入PersistShardingInfoTransactionExecutionCallback方法中,看看这个方法逻辑
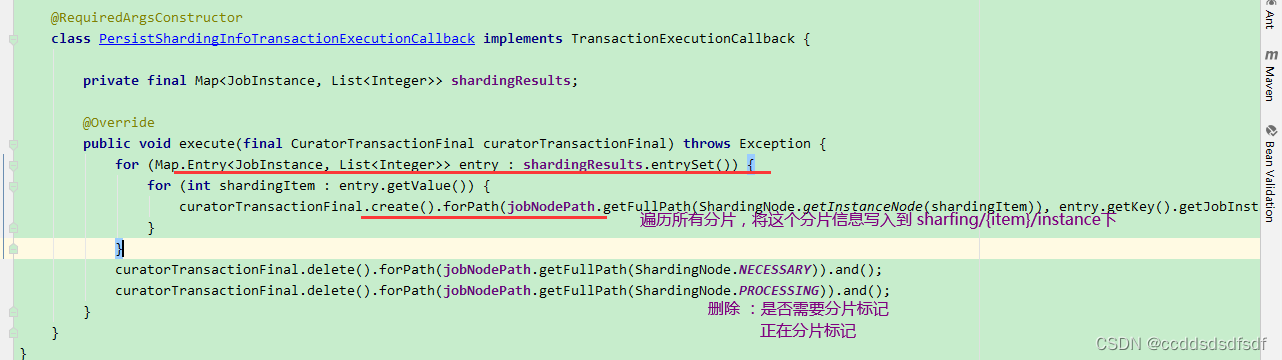
7、3种分片策略
1、AverageAllocationJobShardingStrategy平均分配分片算法
全路径:
com.dangdang.ddframe.job.lite.api.strategy.impl.AverageAllocationJobShardingStrategy
策略说明:
基于平均分配算法的分片策略,也是默认的分片策略。
如果分片不能整除,则不能整除的多余分片将依次追加到序号小的服务器。如:
如果有3台服务器,分成9片,则每台服务器分到的分片是:
服务器1=[0,1,2], 服务器2=[3,4,5], 服务器3=[6,7,8]
如果有3台服务器,分成8片,则每台服务器分到的分片是:
服务器1=[0,1,6], 服务器2=[2,3,7], 服务器3=[4,5]
如果有3台服务器,分成10片,则每台服务器分到的分片是:
服务器1=[0,1,2,9], 服务器2=[3,4,5], 服务器3=[6,7,8]
2、OdevitySortByNameJobShardingStrategy 作业名的哈希值奇偶数决定IP升降序算法
3、RotateServerByNameJobShardingStrategy 作业名的哈希值对服务器列表进行轮转的分片策略
3.5、模版方法解析–beforeJobExecuted
执行所有elasticJobListeners 监听方法
3.6、模版方法解析–执行具体任务
1、正在执行map中添加这个job
2、遍历所有分片,写入正在运行分片信息,写入zk sharding/{Shardingitem}/running,
3、如果分片项只有一个,执行这个job子类具体job方法,返回
4、如果有多个item,遍历所有Item, 提交到一个线程执行 job子类具体方法,用countDown.await 等待所有Job执行完。后面再进行 JOb执行完操作。
5、注册作业完成信息,设置map中jobRunning=false。删除上面设置的runnting节点
3.7、模版方法解析–如果有一次错过执行
先清除这个 错过标记,然后执行这个任务
四、总结
那么现在回答下面几个问题:
1、4台job服务,只设置一个分片,如何保证只有一台服务执行。
- 首先4台服务,会选 一个主节点,先设置需要分片标记
- 当quartz触发的任务时间到时,每台服务都会执行我们自定义的job,执行前会选 判断是否需要分片,如果需要分片,那么由主节点完成分片,其它节点任务等待 直到分片完成。
- 每台节点获取 分片信息
- 如果本台节点获取到分片信息 那么执行,没有获取到分片的节点不执行,(分片节点下会存 实例Ip,通过对比节点实例 Ip和本地实例Ip 来判断 本地是否有可执行的分片)
2、1台job服务,设置4个分片,如何保证这个任务执行4次,如何保证数据幂等
- 每台机器的shardingitem不同,可以通过id%shardingcount == sharingitem 的方式, 得到本个分片节点 可执行的数据。所以每台分片 都会执行不同的数据,保证的数据幂等。
2.1、设置4个片,通过取模的方式使每台服务器执行的数据不同,4台服务执行情况
一个任务 在获取数据的时候 通过 取模方式 来使每个分片得到的数据不同。如果数据分布并不均匀,
比如 item=0的分片获取到10条, 需要执行10s
Item=1的分版获取到20条,需要执行20s
item=2的分片获取到30条,需要执行30s
item=3的分片获取到40条,需要执行40s
如果这个任务每10条执行一次。
那么item=0的分片服务,执行时刻为:
0,10,20,30 都是正常的
time=1的分片服务,执行时刻为:
14:11:10 第一次正常执行
14:11:40 虽然每10执行一次,但我需要20s才执行完,所以40才执行
14:12:00 到60s的时候 上次任务执行完,错过了一次执行时刻,所以立马执行一次 补偿
14:12:30 这次我又正常执行
14:12:50 错过一次 上次50执行完后,又立刻补偿一次
14:13:20 这次又是正常执行
14:13:40 补偿一次
14:14:10 正常
所以 ,每个分片任务执行情况,会按那个分片执行时长 决定。
2.2、如果修改分片总数会怎样
如果有4台服务器,比如 刚开始设置了4个分片, 那么每台服务器正好分配一个分片。如果此时认为 执行时间太长,想改成6个分片,会怎么样?
A: 0、4
B: 1、5
C: 2
D: 3
那么会等待所有分片任务执行完后,才开始重新分片。
还是每隔10s执行一次任务。此时 item=0的只需10s执行完,而Itme=4的需要20s执行完。
在一台服务器上的分片 总是同时执行,如果0,4 会同时执行,而延时 按执行时间长的任务计算。
item=0,4的任务都延迟了100s
[2022-11-16 15:38:20.046] INFO sleepTime:100秒,shardingItem:4,总分片数:6
[2022-11-16 15:38:20.046] INFO sleepTime:20秒,shardingItem:0,总分片数:6
[2022-11-16 15:40:10.013] INFO sleepTime:100秒,shardingItem:4,总分片数:6
[2022-11-16 15:40:10.013] INFO sleepTime:20秒,shardingItem:0,总分片数:6
[2022-11-16 15:41:50.055] INFO sleepTime:20秒,shardingItem:0,总分片数:6
[2022-11-16 15:41:50.055] INFO sleepTime:100秒,shardingItem:4,总分片数:6
[2022-11-16 15:54:00.017]sleepTime:40秒,shardingItem:1,总分片数:6
[2022-11-16 15:54:00.018]sleepTime:120秒,shardingItem:5,总分片数:6
[2022-11-16 15:56:00.038]sleepTime:120秒,shardingItem:5,总分片数:6
[2022-11-16 15:56:00.038]sleepTime:40秒,shardingItem:1,总分片数:6
[2022-11-16 15:58:10.010]sleepTime:120秒,shardingItem:5,总分片数:6
[2022-11-16 15:58:10.010]sleepTime:40秒,shardingItem:1,总分片数:6
[2022-11-16 15:56:50.009] sleepTime:60秒,shardingItem:2,总分片数:6
[2022-11-16 15:57:50.031] sleepTime:60秒,shardingItem:2,总分片数:6
[2022-11-16 15:59:00.010] sleepTime:60秒,shardingItem:2,总分片数:6
[2022-11-16 16:00:00.101] sleepTime:60秒,shardingItem:2,总分片数:6
3、什么是任务错过机制
- 一个任务执行太长,到达下一个触发时间点时 还未执行完,那么就是任务错过机制。 任务错过会写入 zk节点信息。 当任务执行完成后 ,发现有错过节点信息,那么获取 错过的节点信息 再执行一次。
4、如果分片后, 在节点执行过程中 有节点崩溃会怎么样?
数据会重新分片,如果任务未执行完成,然后执行分片动作,数据是否会被不同的任务同时处理呢?
答案是不会,因为当节点宕机后是否需要重新分片事件监听器会监听到Job实例代表的节点删除,设置重新分片,在任务被调度执行具体处理逻辑之前,需要重新分片,重新分片的前提又是要所有的分片的任务全部执行完毕,这也依赖是否开启幂等控制(monitorExecution)。
如果开启,ElasticJob能感知正在执行处理的分片,重新分片需要等待当前所有任务全部运行完毕后才会触发,故不会存在不同节点处理相同数据的问题。
5、如果一个任务JOB的调度频率为每10s一次,在某个时间,该job执行耗时用了33s(平时只需执行5s),按照正常调度,应该后续会触发3次调度,那该job后执行完,会连续执行3次调度吗?
答案:在33s这次任务执行完成后,如果后面的任务执行在10s内执行完毕的话,只会触发一次,不会补偿3次,因为Ela-sticJob记录任务错失执行,只是创建了misfire节点,并不会记录错失的次数。

















 1186
1186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









