




一、状态一致性
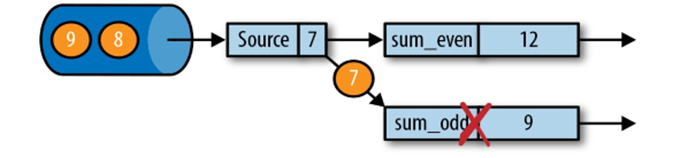
1)有状态的流处理,内部每个算子任务都可以有自己的状态;
2)对于流处理器内部来说,所谓的状态一致性,其实就是我们所说的计算结果要保证准确;
3)一条数据不应该丢失,也不应该重复计算;
4)在遇到故障时可以恢复状态,恢复以后进行重新计算,结果应该也是完全正确的;
1、状态一致性分类
(1)AT-MOST-ONCE(最多一次)
》》当任务故障时,最简单的做法就是什么也不干,既不恢复丢失的状态,也不重播丢失的数据,At-most-once语义的含义是最多处理一次事件。
(2)AT-LEAST-ONCE(至少一次)
》》在大多数的真实应用场景中,我们希望不丢失事件,这种类型的保障称为at-least-once,意思是所有的事件都得到了处理,而一些事件还可能被处理多次;
(3)EXACTLY-ONCE(精确一次)
》》恰好处理一次是最严格的保证,也是最难实现的。恰好处理一次语义不仅仅意味着没有事件丢失,还意味着针对每一个数据,内部状态仅仅更新一次。
二、一致性检查点(checkpoint)
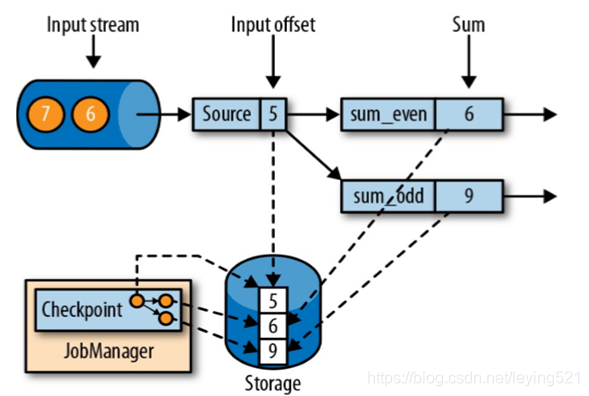
1)Flink使用了一种轻量级快照机制——检查点(checkpoint)来保证exactly-once语义;
2)有状态流应用的一致检查点,其实就是:所有任务的状态,在某个时间点的一份拷贝(一份快照)。而这个时间点,应该是所有任务都恰好处理完一个相同的输入数据的时候;
3)应用状态的一致检查点,是Flink故障恢复机制的核心;
三、端到端(end-to-end)状态一致性
1)目前我们看到的一致性保证都是由流处理器实现的,也就是说都是在Flink流处理器内部保证的;而在真实应用中,流处理应用除了流处理器以外还包含了数据源(例如:Kafka)和输出到持久化系统;
2)端到端的一致性保证,意味着结果的正确性贯穿了整个流处理应用的始终;每一个组件都保证了它自己的一致性;
3)整个端到端的一致性级别取决于所有组件中一致性最弱的组件;
四、端到端的精确一次(exactly-once)保证
1)内部保证——checkpoint;
2)source端——可重设数据的读取位置
3)sink端——从故障恢复时,数据不会重复写入外部系统
》》幂等写入
》》事务写入
1、幂等写入(Idempotent Writes)
1)所谓幂等操作,是说一个操作,可以重复执行很多次,但只导致一次结果更改,也就是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 812
812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









