




 本文详细介绍了Flink流处理中的状态管理,包括无状态和有状态计算,强调了有状态计算的重要性。Flink提供KeyedState和OperatorState两种状态类型,并支持多种状态数据结构。此外,文章阐述了Flink如何通过 checkpoint 实现有状态计算的一致性,保证至少一次和精确一次的语义,并讨论了状态后端的选择和配置。最后,提到了重启策略和保存点(Savepoint)的概念,以及如何在作业恢复时使用它们。
本文详细介绍了Flink流处理中的状态管理,包括无状态和有状态计算,强调了有状态计算的重要性。Flink提供KeyedState和OperatorState两种状态类型,并支持多种状态数据结构。此外,文章阐述了Flink如何通过 checkpoint 实现有状态计算的一致性,保证至少一次和精确一次的语义,并讨论了状态后端的选择和配置。最后,提到了重启策略和保存点(Savepoint)的概念,以及如何在作业恢复时使用它们。
1.简介
流式计算分为无状态和有状态两种情况。无状态的计算观察每个独立事件,并根据最后一个事件输出结果。例如,流处理应用程序从传感器接收温度读数,并在温度超过90 度时发出警告。有状态的计算则会基于多个事件输出结果。以下是一些例子。
- 所有类型的窗口。例如,计算过去一小时的平均温度,就是有状态的计算。
- 所有用于复杂事件处理的状态机。例如,若在一分钟内收到两个相差20 度以上的温度读数,则发出警告,这是有状态的计算。
- 流与流之间的所有关联操作,以及流与静态表或动态表之间的关联操作,都是有状态的计算。
下图展示了无状态流处理和有状态流处理的主要区别。无状态流处理分别接收每条数据记录(图中的黑条),然后根据最新输入的数据生成输出数据(白条)。有状态流处理会维护状态(根据每条输入记录进行更新),并基于最新输入的记录和当前的状态值生成输出记录(灰条)。
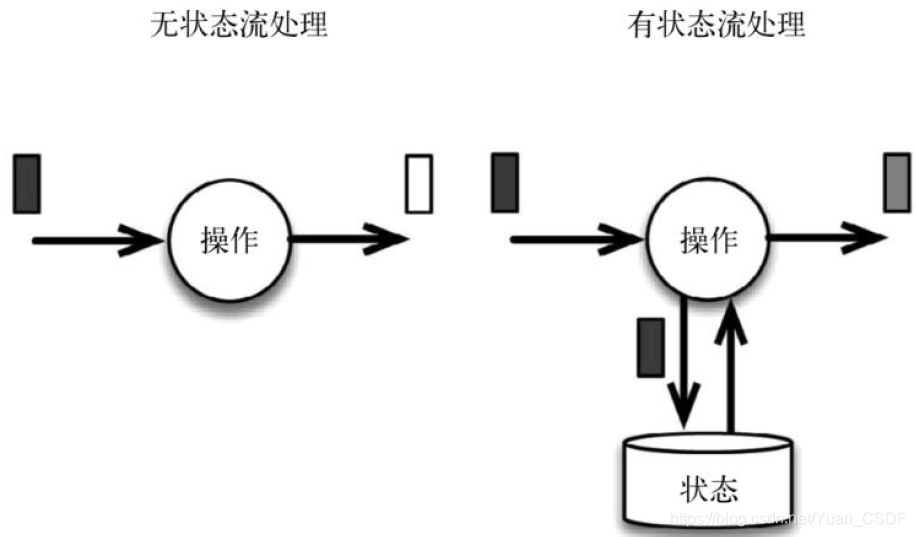
上图中输入数据由黑条表示。无状态流处理每次只转换一条输入记录,并且仅根据最新的输入记录输出结果(白条)。有状态流处理维护所有已处理记录的状态值,并根据每条新输入的记录更新状态,因此输出记录(灰条)反映的是综合考虑多个事件之后的结果。
尽管无状态的计算很重要,但是流处理对有状态的计算更感兴趣。事实上,正确地实现有状态的计算比实现无状态的计算难得多。旧的流处理系统并不支持有状态的计算,而新一代的流处理系统则将状态及其正确性视为重中之重。
2.有状态的算子和应用程序
Flink内置的很多算子,数据源source,数据存储sink都是有状态的,流中的数据都是buffer records,会保存一定的元素或者元数据。例如: ProcessWindowFunction会缓存输入流的数据,ProcessFunction 会保存设置的定时器信息等等。
state:flink中有状态函数和运算符在各个元素(element)/事件(event)的处理过程中存储的数据(注意:状态数据可以修改和查询,可以自己维护,根据自己的业务场景,保存历史数据或者中间结果到状态(state)中);
Flink中有两种基本类型的State:Keyed State,Operator State。
- 算子状态(operator state):始终与特定算子相关联。作用范围限定为算子任务,由同一并行任务所处理的所有数据都可以访问到相同的状态
- 键控状态(keyed state):根据输入数据流中定义的键(key)来维护和访问状态后端(State Backends)
他们两种都可以以两种形式存在:原始状态(raw state)和托管状态(managed state).
托管状态:由Flink框架管理的状态,如ValueState, ListState, MapState等,我们通常使用的就是这种。
原始状态:由用户自行管理状态具体的数据结构,框架在做checkpoint的时候,使用byte[]来读写状态内容,对其内部数据结构一无所知。
通常在DataStream上的状态推荐使用托管的状态,当实现一个用户自定义的operator时,会使用到原始状态。但是我们工作中一般不常用,所以我们不考虑他。
2.1算子状态
算子状态的作用范围限定为算子任务。这意味着由同一并行任务所处理的所有数据都可以访问到相同的状态,状态对于同一任务而言是共享的。算子状态不能由相同或不同算子的另一个任务访问。
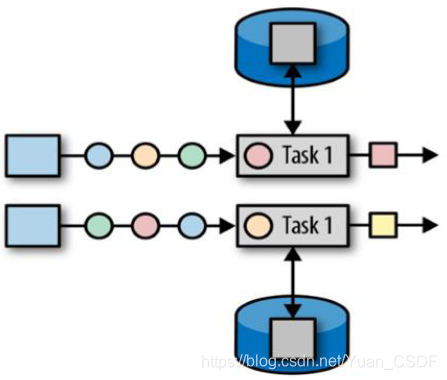
Flink 为算子状态提供三种基本数据结构:
- 列表状态(List state)
- 将状态表示为一组数据的列表。
- 联合列表状态(Union list state)
- 也将状态表示为数据的列表。它与常规列表状态的区别在于,在发生故障时,或者从保存点(savepoint)启动应用程序时如何恢复。
- 广播状态(Broadcast state)
- 如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态。
2.2键控状态
键控状态是根据输入数据流中定义的键(key)来维护和访问的。Flink 为每个键值维护一个状态实例,并将具有相同键的所有数据,都分区到同一个算子任务中,这个任务会维护和处理这个key 对应的状态。当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的key。因此,具有相同key 的所有数据都会访问相同的状态。Keyed State 很类似于一个分布式的key-value map 数据结构,只能用于KeyedStream(keyBy 算子处理之后)。

Flink的Keyed State支持以下数据类型:
- ValueState[T]保存单个的值,值的类型为T。
- get 操作: ValueState.value()
- set 操作: ValueState.update(value: T)
- ListState[T]保存一个列表,列表里的元素的数据类型为T。基本操作如下:
- ListState.add(value: T)
- ListState.addAll(values: java.util.List[T])
- ListState.get()返回Iterable[T]
- ListState.update(values: java.util.List[T])
- MapState[K, V]保存Key-Value 对。
- MapState.get(key: K)
- MapState.put(key: K, value: V)
- MapState.contains(key: K)
- MapState.remove(key: K)
- ReducingState[T]
- AggregatingState[I, O]
- FoldingState
示例:
// Keyed state测试:必须定义在Ri 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 813
813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









