



场景:
在很多时候我们读取 Excel 文件后,得到的 df 中,时间日期列有很多浮点数,原因是在 Excel 中,时间会被当成序列数储存,如果设置的格式不当,或者在 Excel 清除了格式,时间就换变为序列数,例如:
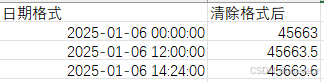
在 pandas 读取这样的 Excel 后,并不能直接转换为 datetime,我们可以应用一下代码,对数据进行格式化:
def convert_to_datetime(value):
try:
# 检测传入的是否为数字
if pd.api.types.is_number(value):
# 处理 Excel 序列号中的特殊日期
if value < 60:
return pd.to_datetime(value - 1, origin='1900-01-01', unit='D')
else:
# 考虑到1900年2月29日这个不存在的日期在excel会正确显示,所以让1900-2-29显示为1900-02-28
# 即当数字为60时,实际的时间是1900-2-28,当数字为59时,日期也为1900-2-28
return pd.to_datetime(value - 1, origin='1899-12-31', unit='D')
else:
# 尝试直接转换为 datetime
return pd.to_datetime(value)
except (ValueError, OverflowError):
# 当非序列数时应返回原来的内容
return value这里给代码做出解释,Excel 在计算日期时,会将日期转化为序列数,1900-01-01 记为 1,1900-01-02 记为 2,以此类推;
但是为了兼容之前版本的软件和其他软件,Excel 会错误的认定 1900 年为闰年,即 1900-02-29 是有效日期,Excel 关于 1900 年闰年解释,但在 pandas 和其他软件中,没有 1900-02-29,所以我在转换代码中检测当,序列数小于 60 时,第一天为 1900-01-01,;当序列数大于等于 60 时,开始日期则为 1899-12-31,在转换时就可以转为正确的日期。
应用示例:
import pandas as pd
def convert_to_datetime(value):
try:
# 检测传入的是否为数字
if pd.api.types.is_number(value):
# 处理 Excel 序列号中的特殊日期
if value < 60:
return pd.to_datetime(value - 1, origin='1900-01-01', unit='D')
else:
# 考虑到1900年2月29日这个不存在的日期在excel会正确显示,所以让1900-2-29显示为1900-02-28
# 即当数字为60时,实际的时间是1900-2-28,当数字为59时,日期也为1900-2-28
return pd.to_datetime(value - 1, origin='1899-12-31', unit='D')
else:
# 尝试直接转换为 datetime
return pd.to_datetime(value)
except (ValueError, OverflowError):
# 当非序列数时应返回原来的内容
return value
# 示例数据列表
example_values = [
44562.75, # 这是一个Excel浮点数表示的日期,对应于2022-01-01 18:00
"2023-04-05", # 这是一个字符串形式的日期
60, # Excel中的特殊日期,应该返回1900-02-28
59, # 同样,这应该返回1900-02-28
"not a date", # 非日期格式的字符串
1, # Excel序列号1对应于1900-01-01
]
# 将示例数据转换为日期
converted_dates = [convert_to_datetime(val) for val in example_values]
for original, converted in zip(example_values, converted_dates):
print(f"Original: {original}, Converted to datetime: {converted}")
















 766
766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









