




 随着业务发展,数据库扩展成为必然。本文详细介绍了MySQL的分库分表策略,包括业务拆分、主从复制,以及分表、分库的实现方式,如根据用户ID进行分库分表,并探讨了不同路由策略的优缺点,同时指出分库分表后可能面临的挑战,如分布式事务和多表查询问题。
随着业务发展,数据库扩展成为必然。本文详细介绍了MySQL的分库分表策略,包括业务拆分、主从复制,以及分表、分库的实现方式,如根据用户ID进行分库分表,并探讨了不同路由策略的优缺点,同时指出分库分表后可能面临的挑战,如分布式事务和多表查询问题。
MySQL扩展具体的实现方式
随着业务规模的不断扩大,需要选择合适的方案去应对数据规模的增长,以应对逐渐增长的访问压力和数据量。
关于数据库的扩展主要包括:业务拆分、主从复制,数据库分库与分表。文章主要讲述数据库分库与分表
(1)业务拆分
业务起步初始,为了加快应用上线和快速迭代,很多应用都采用集中式的架构。随着业务系统的扩大,系统变得越来越复杂,越来越难以维护,开发效率变得越来越低,并且对资源的消耗也变得越来越大,通过硬件提高系统性能的方式带来的成本也越来越高。
因此,在选型初期,一个优良的架构设计是后期系统进行扩展的重要保障。
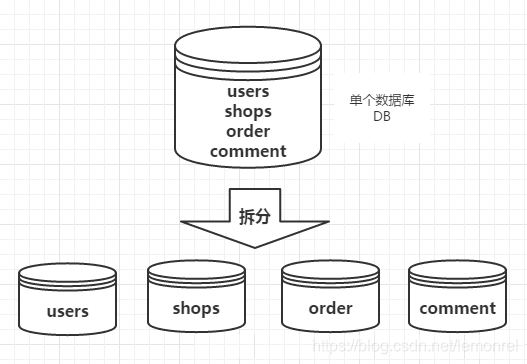
例如:电商平台,包含了用户、商品、评价、订单等几大模块,最简单的做法就是在一个数据库中分别创建users、shops、comment、order四张表。
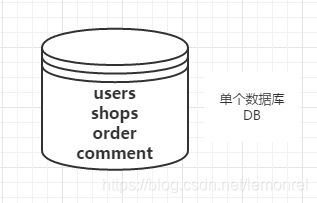
但是,随着业务规模的增大,访问量的增大,我们不得不对业务进行拆分。每一个模块都使用单独的数据库来进行存储,不同的业务访问不同的数据库,将原本对一个数据库的依赖拆分为对4个数据库的依赖,这样的话就变成了4个数据库同时承担压力,系统的吞吐量自然就提高了。
(2)主从复制
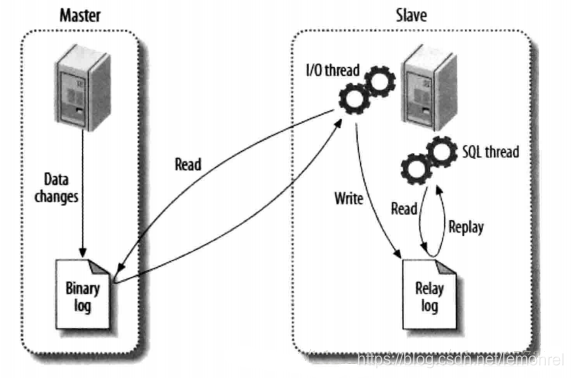
上图是网上的一张关于MySQL的Master和Slave之间数据同步的过程图。
主要讲述了MySQL主从复制的原理:数据复制的实际就是Slave从Master获取Binary log文件,然后再本地镜像的执行日志中记录的操作。由于主从复制的过程是异步的,因此Slave和Master之间的数据有可能存在延迟的现象,此时只能保证数据最终的一致性。
(3)数据库分库与分表
我们知道每台机器无论配置多么好它都有自身的物理上限,所以当我们应用已经能触及或远远超出单台机器的某个上限的时候,我们惟有寻找别的机器的帮助或者继续升级的我们的硬件,但常见的方案还是通过添加更多的机器来共同承担压力。
我们还得考虑当我们的业务逻辑不断增长,我们的机器能不能通过线性增长就能满足需求?因此,使用数据库的分库分表,能够立竿见影的提升系统的性能,关于为什么要使用数据库的分库分表的其他原因这里不再赘述,主要讲具体的实现策略。
分表实现策略
关键字:用户ID、表容量
对于大部分数据库的设计和业务的操作基本都与用户的ID相关,因此
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1798
1798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









