







梯度下降法中,有3中不同的策略。分别是:
- (full) batch gradient descent = 批梯度下降,是指所有数据一次性全部喂给模型,然后用梯度下降法更新参数。这种策略的问题就是一次迭代的时间太长了,难得等。(是否存在随机的问题,也就是数据是否会打乱喂给模型,我还不清楚)
- mini-batch gradient descent = 小批梯度下降,是指把训练数据分成很多了mini-batch(也就是很多个数据的集合),每次喂一个mini-batch给模型,然后用梯度下降法来更新参数。这种方法是BGD和SGD这两个方法的折中。这里面也有随机,(有两种方案,其一是先打乱所有数据,然后平均划分数据,按顺序取就是了。另一种方案是先平均划分数据,然后随机取一个mini-batch。以上是我的思考,Keras和Tensorflow中如何实现的不清楚,有知道的同学请指教一下)
- stochastic gradient descent = 随机梯度下降,每次随机选择一个数据,喂给模型,然后更新参数。这种策略的问题是每次数据太少了,模型学不到什么东西。
总结:平时我们说的随机梯度下降,就是SGD,随机是指随机选择一个数据喂给模型。
我在网上看到一篇博客文章:
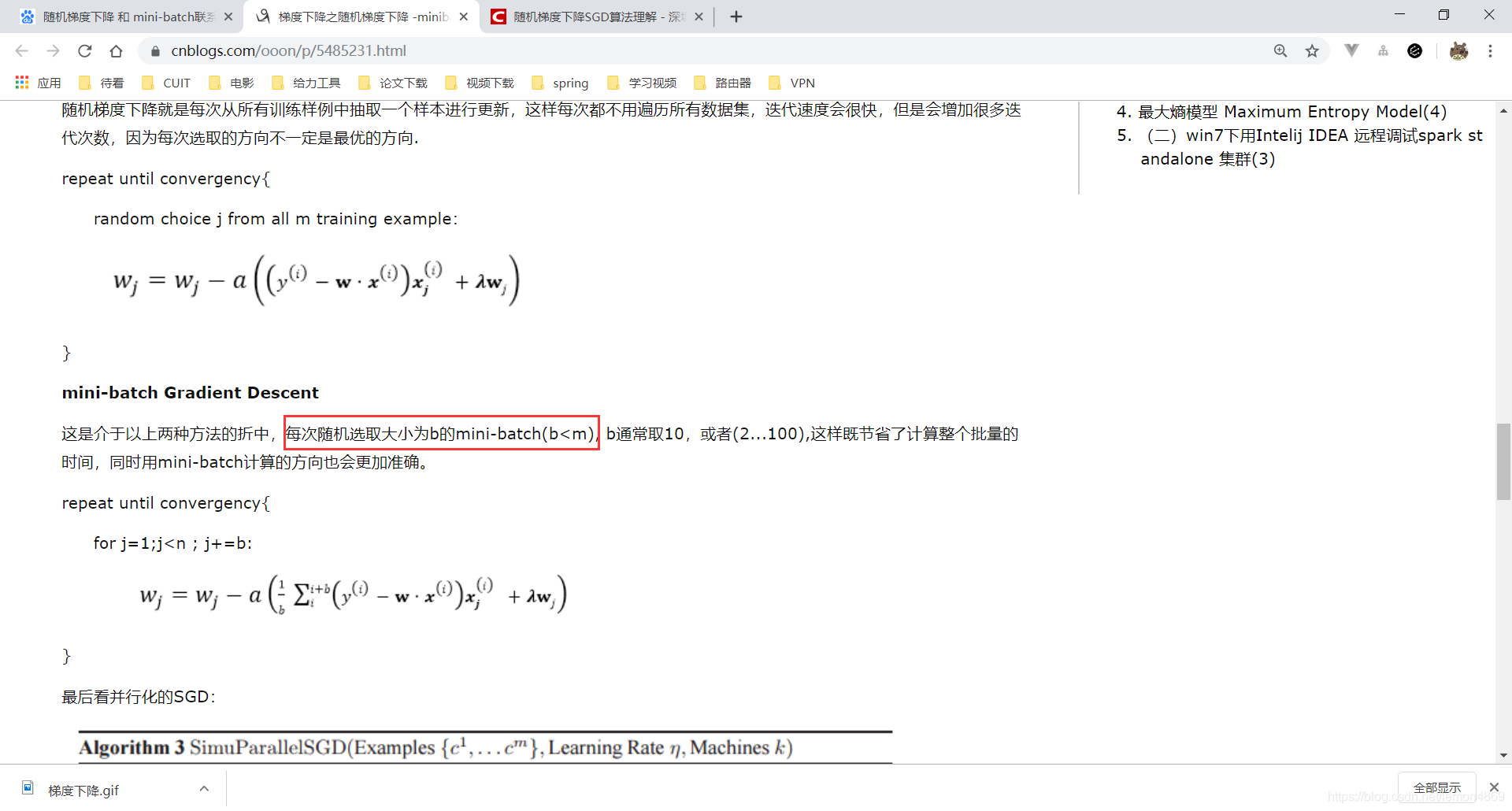
随机选取大小为b的mini-batch
这种说法明显是错的!不知道从哪里学习到的。???
还有就是《深度学习入门:基于Python的理论与实现》一书中,P110:
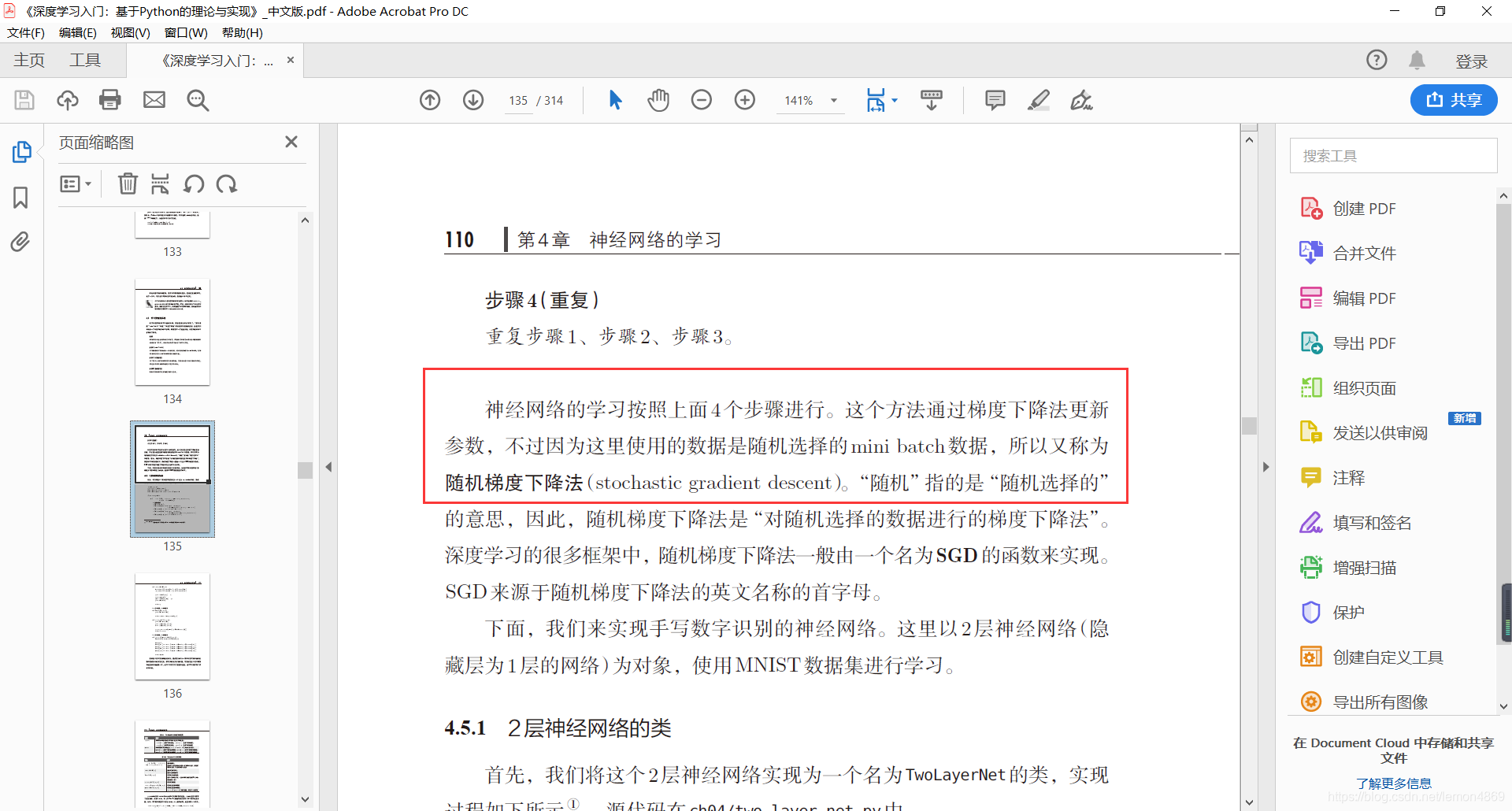
作者说随机梯度下降是以mini-batch为单位喂给模型,随机选择一个mini-batch。作者想要表示的应该是mini-batch gradient descent。所以,我觉得这里应该有问题,要么是作者默认SGD就是mini-batch gradient descent,要么是他搞错了。

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









