







提取登陆URL
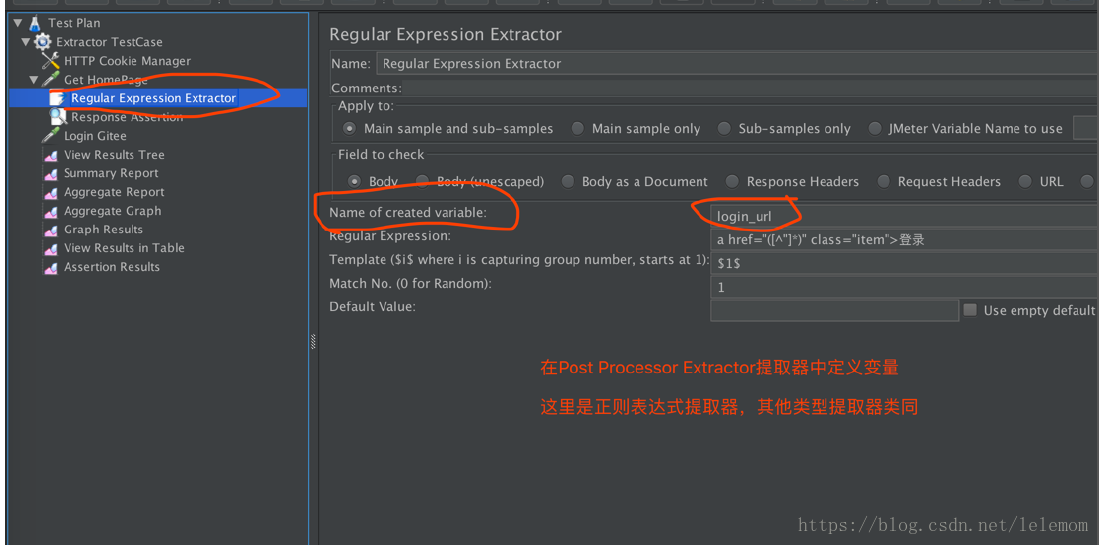
20. 在Regular expression_r Extractor会看到Template的值是$1$,这个值是什么意思呢?
$1$是指取第一个()里面的值。如果Regular expression_r的数值有多个,用这种方法可以避免不必要的麻烦。
21. Regular expression_r中的(.*)是什么意思?
那是一个正则表达式(regular expression_r)。’.’等同于sql语言中的’?’,表示可有可无。’*’表示0个或多个。’()’表示需要取值。(.*)表达任意长度的字符串。
22. 在读取Regular expression_r时要注意什么?
一定要保证所取数值的绝对唯一性。
23. 怎样才能判断什么样的情况需要添加Regular expression_r Extractor?
检查Http Request中的Send Parameters,如果有某个参数是其前一个page中所没有给出的,就要到原文件中查找,并添加Regular expression_r Extractor到其前一page的http request中。
作者:Annie丁小妞
链接:https://www.jianshu.com/p/69e68974e949
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
-------转载https://www.cnblogs.com/tina19882010/articles/7909189.html
1)提取单个字符串
假设试人员期望匹配Web页面的如下部分:name="file" value="readme.txt">并提取readme.txt。
一个符合要求的正则表达式:name="file" value="(.+?)"> 。
上面用到的特殊字符包括如下几个:
( 和 ):封装了待返回的匹配字符串。
.:匹配任何字符。
+:一次或多次。
?:不要太贪婪,在找到第一个匹配项后停止。
如果没有?,在找到第一个">后,会继续寻找,直到最后一个">,这么做很可能不是测试人员期望的。
尽管上面的表达式可以达到目的,但是使用如下表达式更有效率:name="file" value="([^"]+)">,其中[^"]+意味着匹配任何东西(除了")。在这种情况下,匹配引擎在找到第一个右侧"后,就会停止搜索。而上面例子中的匹配引擎会去寻找">。
2)提取多个字符串
假设测试人员期望匹配Web页面的如下部分:name="file" value="readme.txt">,并提取file.name和readme.txt。
一个符合要求的正则表达式:name="([^"]+)" value="([^"]+)"
这会创建两个组合,并可用于JMeter正则表达式模板,形如11和22。
例如,
引用名称:MYREF
正则表达式:name="(.+?)" value="(.+?)"。
模板:1122。
不要用/ /封装正则表达式。
如下变量的值将会被设定。
MYREF: file.namereadme.txt。
MYREF_g0: name="file.name" value="readme.txt"。
MYREF_g1: file.name。
MYREF_g2: readme.txt。
这些变量后续可以在JMeter测试计划中引用,形如MYREF、MYREF、{MYREF_g1}等。
3.关键字
正则表达式使用特定字符作为关键字,这些字符对正则表达式引擎有特殊意义。在字符串中使用这些字符必须进行转义(使用反斜杠"\"),目的是将它们当成原始字符,而非正则表达式的关键字。下面是关键字和它们的含义:
( ):组合。
[ ]:字符集合。
{ }:重复。
+ ?:重复。
.:任意匹配字符。
\:转义字符。
| -:选择符。
^ $:字符串或行的起始和结尾。
注意,ORO不支持\Q和\E关键字。
4.修改器(Modifier)
理论上修改器可以被放置在正则表达式的任何地方,并被放置的位置开始向后生效。(ORO存在一个BUG,修改器不能放在正则表达式的末尾。尽管修改器在这里不生效)。
单行(?s)和多行(?m)修改器通常都被放在正则表达式的开头。
忽略(?i)修改器可以被用来仅仅影响正则表达式的某一部分,例如:
Match ExAct case or (?i)ArBiTrARY(?-i) case
由于单行和多行修改器的设置不同,范本匹配的表现也略有不同。请注意,单行和多行操作符之间没有任何关联;它们可以被单独指定。
1)单行模式
单行模式只影响关键字符"."。默认情况下,"."可以匹配任何字符(除了换行)。在单行模式下,"."还匹配换行。
2)多行模式
多行模式只影响关键字符"^"和""。默认情况下,"′′和""。默认情况下,""和""仅仅匹配字符串的开始和结尾。而在多行模式下,"^"和"$"匹配每一行的开始和结尾。
下面是转载https://blog.youkuaiyun.com/linapursue/article/details/79084586
jmeter自带后置处理器:正则表达式提取器,可以用来提取接口响应里的信息,给予后续接口传参用。
例如要提取响应结果里的token字段及sex字段(响应内容为:

"token":"83EEAA887F1D2F1AA1CDA9E197810992","sex":0,"userName":"12548650"),提取器如下设置,
正则表达式提取器,页面参数说明:
Apply to:应用范围(一般就选择默认的Main sample only),就算有重定向,一般也是提取最终那个请求的接口。
要检查的响应字段:样本数据源。
主体: 接口响应主体内容,一般要提取普通http响应结果的数据,都勾选这个。
信息头:响应头的所有内容。
Request Headers:请求头的所有内容。
url:是对sample的url进行匹配,也就是查看结果树里请求内容的第一行url,不包含data里的请求参数(即只能匹配 protocol(协议)+host+path+querystring,如:https://www.baidu.com/index.php?tn=monline_3_dg)。
响应代码:http响应代码,如101,200,302,404,501等。
响应信息:http响应代码对应的响应信息,例如:OK, Found(HTTP/1.1 200 Ok;HTTP/1.1 302 Found)。
引用名称:其他地方引用时的变量名称,名称只能是一个,引用方法:${token}。
正则表达式:一般简单的通用语法就是:左边界(.*?)右边界
(.*)表达任意长度的字符串。左右边界就是为了能准确定位到想匹配的内容。
(.*?) 是替换了想要提取的内容,里面的'?'为非贪婪匹配,(非贪婪模式就是说在遇到第一个右边界后就停止匹 配,这样就可以精确拿到想要的内容)。建议均使用非贪婪匹配,除非特殊情况。
提取单个字符串
假设想要从web页 name=”file” value=”readme.txt”> 进行匹配,从中提取”readme.txt” ,一个适当的表达式是:
name=”file” value=”(.+?)”>
上面特殊的字符是:
()闭合的括号将匹配的部分当成一个整体返回
. 匹配任何字符
+ 匹配一次或者多次(至少一次)
? 非贪婪的,匹配到一个就终止匹配(即匹配0次或者1次)
模板:对应正则表达式提取器类型,样式为:$n$。
若模板为:$0$,则为整个表达式匹配到的内容,就是包括小括号内跟小括号外的内容,即 ("token":"83EEAA887F1D2F1AA1CDA9E197810992","sex":0,"userName")。
若模板为:$1$,则对应正则表达式中的第一个(.*?)所匹配的内容,即(83EEAA887F1D2F1AA1CDA9E197810992) ,
若模板为:$2$,则对应正则表达式中的第二个(.*?)所匹配的内容,即(0),
若模板为$1$$2$,则把2个(.*?)所匹配的内容拼接起来,即(83EEAA887F1D2F1AA1CDA9E1978109920)。
模板是可以自由组合的,后续案例中再介绍。
匹配数字:正则表达式匹配数据的最终结果可以看做一个数组,匹配数字即可看做是数组的第几个元素。当为 0 时,随机返回匹配的数据。当为 1 时,表示返回匹配结果数组的第一个元素。当为负数(-1,-2,-100都可以)时,表示返回全部元素,并且同时会返回一个元素总数的变量token_matchNr,在引用时:通过${token_1}的方式来取第1个匹配的内容,${token_2}来取第2个匹配的内容。
缺省值:匹配失败时的默认值。通常用于后续的逻辑判断,建议使用一些特殊含义的,比如0,NULL,ERROR等。
正则测试:
可以直接在察看结果树里选择Regexp正则测试模式来测试正则是否写的正确。

正则结果查看:
如何查看提取到了想要的内容呢,这里就需要提到另外一个后置处理器:Debug PostProcessor
该元件就为调试所用,一般用于查看变量值,添加方法同正则表达式提取器。


















 136
136

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









