




 本文详细介绍了如何使用Docker分别安装Clickhouse和MongoDB,并提供了大数据插入脚本进行性能测试。结果显示,Clickhouse在批量插入数据和大数据查询上表现出更高的效率,同时数据压缩更优,占用空间小。对于精准和模糊查询,Clickhouse在数据量较大时耗时更短。
本文详细介绍了如何使用Docker分别安装Clickhouse和MongoDB,并提供了大数据插入脚本进行性能测试。结果显示,Clickhouse在批量插入数据和大数据查询上表现出更高的效率,同时数据压缩更优,占用空间小。对于精准和模糊查询,Clickhouse在数据量较大时耗时更短。
一、硬件设施
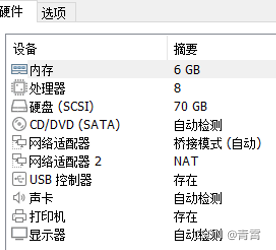
二、安装数据库
2.1、docker安装clickhouse
1、拉取镜像
docker pull yandex/clickhouse-server
2、启动服务(临时启动,获取配置文件)
docker run --rm -d --name=clickhouse-server \
--ulimit nofile=262144:262144 \
-p 8123:8123 -p 9009:9009 -p 9000:9000 \
yandex/clickhouse-server:latest
3、复制容器中的配置文件到宿主机
提前创建好文件夹,mkdir -p /home/clickhouse/conf/
docker cp clickhouse-server:/etc/clickhouse-server/config.xml /home/clickhouse/conf/config.xml
docker cp clickhouse-server:/etc/clickhouse-server/users.xml /home/clickhouse/conf/users.xml
4、停止第2步启动的ck容器(clickhouse-server)
5、修改密码 第3步的配置文件
vi /home/clickhouse/conf/users.xml,在password标签中加上密码,可以使用加密密码
6、重启启动
docker run -d --name=clickhouse-server \
-p 8123:8123 -p 9009:9009 -p 9000:9000 \
--ulimit nofile=262144:262144 \
-v /home/clickhouse/data:/var/lib/clickhouse:rw \
-v /home/clickhouse/conf/config.xml:/etc/clickhouse-server/config.xml \
-v /home/clickhouse/conf/users.xml:/etc/clickhouse-server/users.xml \
-v /home/clickhouse/log:/var/log/clickhouse-server:rw \
yandex/clickhouse-server:latest
7、进入ck容器
docker exec -it 82 clickhouse-client --user=default --password=your_password
select version() # 查看版本2.2、docker安装mongodb
配置文件:/home/mongo/configdb/mongod.conf
storage:
dbPath: /data/db
journal:
enabled: true
engine: wiredTiger
security:
authorization: enabled
net:
port: 27017
bindIp: 192.168.xx.xx
容器启动:
docker run -d \
-p 27017:27017 \
--name mongo \
-v /home/mongo/db:/data/db \
-v /home/mongo/configdb:/data/configdb \
-v /etc/localtime:/etc/localtime \
mongo -f /data/configdb/mongod.conf三、大数据插入脚本
import json, time
import pymongo,traceback
from clickhouse_driver import Client
import uuid
import random
# 装饰器统计运行耗时
def coast_time(func):
def fun(*args, **kwargs):
t = time.perf_counter()
result = func(*args, **kwargs)
print(f'func {func.__name__} coast time:{time.perf_counter() - t:.8f} s')
return result
return fun
class MyEncoder(json.JSONEncoder):
"""
func:
解决Object of type 'bytes' is not JSON serializable
"""
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 783
783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









