






北京大学前段时间又公开了两份技术报告《DeepSeek内部研讨系列:DeepSeek与新媒体运营》+生成未必理解:基于扩散模型能否实现视觉世界模型》!
篇幅有限,扫码添加好友
免费领取完整版
《DeepSeek内部研讨系列:DeepSeek与新媒体运营》
《生成未必理解:基于扩散模型能否实现视觉世界模型》
👇👇👇

具体如下:
《DeepSeek内部研讨系列:DeepSeek与新媒体运营》


此技术报告聚焦DeepSeek与新媒体运营,介绍了DeepSeek公司及模型的发展历程,对比不同规模模型性能,阐述大模型能力及应用场景,分享提示词工程技巧。同时,详细探讨AI在新媒体运营全链路的应用策略、落地案例,如内容生产、用户运营等场景,分析其带来的挑战,包括隐私风险、内容质量等问题,并提出应对策略,强调新媒体运营人员需提升AI相关能力,以适应行业变革。


《生成未必理解:基于扩散模型能否实现视觉世界模型》

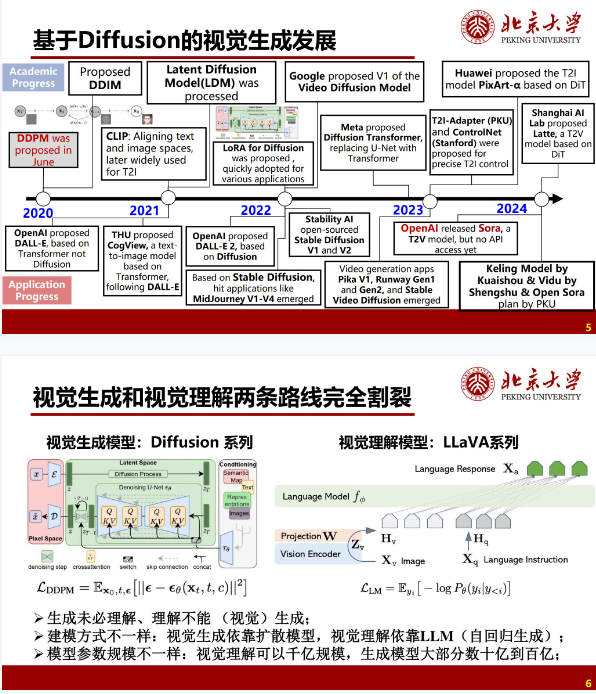
此技术报告聚焦于基于扩散模型实现视觉世界模型的探讨。当前视觉生成与理解路线相互割裂,生成依靠扩散模型,理解依赖 LLM 。文中回顾 Diffusion 视觉生成发展历程,指出世界模型统一是必然趋势,并介绍多模态统一的相关工作。以 Open - Sora Plan 为例,其在视频生成方面成果显著,同时探索视觉世界模型新方向。此外,深入探讨生成和理解统一原生框架的实现路径、争议点,强调自回归 Transformer 在大一统中的关键作用。

篇幅有限,扫码添加好友
免费领取完整版
《DeepSeek内部研讨系列:DeepSeek与新媒体运营》
《生成未必理解:基于扩散模型能否实现视觉世界模型》
👇👇👇


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









