




下面尝试一下Kafka 的生产者客户端和消费者客户端的实现。
1、客户端简介
生产者就是负责向Kafka发送消息的应用程序,消费者就是拉取Kafka消息的应用程序。
在Kafka的历史版本中,主要的客户端如下:
- 基于Scala语言编写的客户端,称为旧客户端,已废弃;
- 基于Java语言编写的客户端(从Kafka0.9.x开始),称为新客户端,它弥补了就客户端中存在的诸多设计缺陷;
pom依赖
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.13</artifactId>
<version>2.6.1</version>
</dependency>
2、Java生产者客户端
public class KafkaProducerTest {
public static final String bootStrap = "localhost:9092";
public static final String topic = "topic_1";
public static void main(String[] args) {
// 1、配置客户端参数
Properties properties = new Properties();
// 指定生产者客户端连接Kafka集群所需的broker地址列表,具体的内容格式为host1:port1,host2:port2
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootStrap);
// key序列化,转换成字节数组以满足broker端接收的消息形式
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// value序列化,转换成字节数组以满足broker端接收的消息形式
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 配置重试次数,10次之后抛异常,可以在回调中处理
properties.put(ProducerConfig.RETRIES_CONFIG, 10);
// 配置客户端id
properties.put(ProducerConfig.CLIENT_ID_CONFIG, "producer.client.id.1");
// 2、构造KafkaProducer客户端实例
KafkaProducer kafkaProducer = new KafkaProducer(properties);
// 3、构建待发送消息
ProducerRecord<String, String> record = new ProducerRecord(topic, "hello world");
// 4、发送消息,分为3种模式,发后即忘、同步(sync)、异步(async)
// 发后即忘,只管往Kafka中发送消息而并不关心消息是否正确到达
// kafkaProducer.send(record);
// 同步,堵塞等待Kafka的响应,直到消息发送成功
try {
kafkaProducer.send(record).get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
// // 异步
// kafkaProducer.send(record, new CallBackTest(record.topic(), record.key(), record.value()));
}
public static class CallBackTest implements Callback {
private String topic;
private String key;
private String value;
public CallBackTest(String topic, String key, String value) {
this.topic = topic;
this.key = key;
this.value = value;
}
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception != null) {
exception.printStackTrace();
} else {
System.out.println("send message to topic success, topic:" + metadata.topic() + ",partition:" + metadata.partition() + ",offset:" + metadata.offset());
}
}
}
}
生产者客户端实现需要以下几步:
- 配置生产者客户端参数;
- 构造KafkaProducer客户端实例;
- 构建待发送消息;
- 发送消息,分为3种方式:发后即忘,同步,异步;
3、Java消费者客户端
public class KafkaConsumerTest {
public static final String bootStrap = "localhost:9092";
public static final String topic = "topic_1";
public static final String groupId = "group.123";
public static void main(String[] args) {
// 1、配置客户端参数
Properties properties = new Properties();
// 指定消费者客户端连接Kafka集群所需的broker地址列表,具体的内容格式为host1:port1,host2:port2
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootStrap);
// key序列化,转换成字节数组以满足broker端接收的消息形式
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// value序列化,转换成字节数组以满足broker端接收的消息形式
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 配置消费组id
properties.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
// 配置客户端id
properties.put(ConsumerConfig.CLIENT_ID_CONFIG, "consumer.client.id.1");
// 2、构造KafkaConsumer客户端实例
KafkaConsumer kafkaConsumer = new KafkaConsumer(properties);
// 3、订阅主题
kafkaConsumer.subscribe(Pattern.compile("topic_1"));
// 4、消费消息
try {
while (true) {
ConsumerRecords<String, String> records = kafkaConsumer.poll(100);
for (ConsumerRecord<String, String> item : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", item.offset(), item.key(), item.value());
}
}
} finally {
kafkaConsumer.close();
}
}
}
消费者客户端实现需要以下几步:
- 配置消费者客户端参数;
- 构造KafkaConsumer客户端实例;
- 订阅相应主题;
- 拉取消息然后消费,最好提交消费位移数据;
4、测试
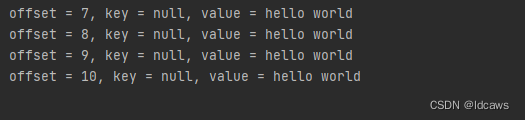
先启动消费者,再启动生产者,结果如下
若有错误之后,欢迎留言指正,感谢~

















 5987
5987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









