




 分库分表是解决大数据量和高并发问题的有效手段。垂直分库根据业务拆分,水平分库依据策略分配,如range、hash。当数据量快速增长、查询效率下降时需考虑分库分表。但这也带来事务处理、关联查询、排序和分页等挑战,需要分布式事务和特定解决方案。
分库分表是解决大数据量和高并发问题的有效手段。垂直分库根据业务拆分,水平分库依据策略分配,如range、hash。当数据量快速增长、查询效率下降时需考虑分库分表。但这也带来事务处理、关联查询、排序和分页等挑战,需要分布式事务和特定解决方案。
分库分表越来越影响系统应用的高可用、高并发问题,下面和分库分表再相约,聊聊mysql环境的分库分表。
- what:什么是分库分表
- why:为什么需要分库分表
- how:如何进行分库分表
- when/where:什么时候/环境考虑分库分表
- problem:分库分表带来的问题
what
分库,就是将一个数据库分成多个数据库,部署到不同的机器。
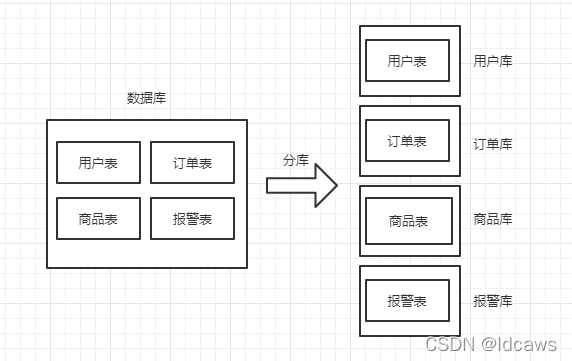
分表,就是将一个数据表分成多个数据表。
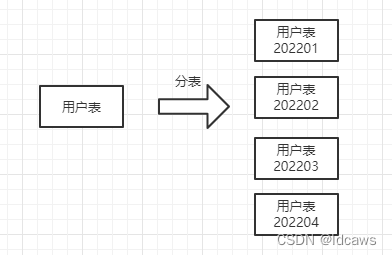
why
数据量越来越大,数据库会出现性能瓶颈。
分库,随着业务量剧增,单个数据库所在机器的磁盘容量可能会撑爆,分成多个数据库,部署到不同机器,解决单个机器的磁盘被撑爆的问题。在高并发的场景下,单个数据库是扛不住大量请求的并发连接的,分成多个数据库,部署到不同机器,分担单个数据库的并发请求压力。
分表,随着数据量增大,sql的查询会越来越慢。如果单表的数据量超过一千万条的话,查询是明显变慢的。mysql的索引一般是B+树结构,数据千万级别的话,B+树的高度会增高,B+树高度一般为1-3层,若超过3层,查询会变慢。
how
分库,可以分为垂直分库和水平分库。
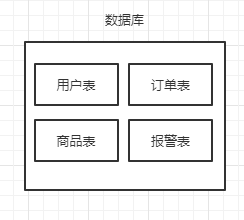
垂直分库,就是根据不同的业务进行拆分,比如将包含用户表、订单表的数据库拆分成用户库、订单库,部署在不同的机器。垂直分库将原来一个单数据库的压力分担到不同的数据库,可以很好应对高并发场景。
水平分库,就是根据不同的策略(如地址、奇偶)分到不同的数据库,每个数据库具有相同的表,水平分库可以有效的缓解单机单库的性能瓶颈和压力。
垂直分表,就是将表中的一些字段拆分到另一张表中。如果单表包含了几十列甚至上百列,每次都select *占用IO资源。垂直分表可以有效降低单机单表的IO资源。
水平分表,就是将表按照某种策略分到不同的表,每个表具有相同的字段,水平分表可以有效的降低单表的数据量。
具体的如何分库分表可以查看之前博客《Java中分库分表粗谈》。
分库分表的策略常用的有range范围、hash去模、range+hash混合。
range范围就是按照从0-1000万划分为一个表,1000-2000万划分为另一个表。也可以按照时间划分。
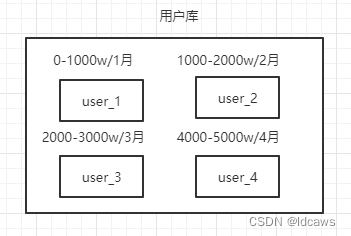
hash取模就是根据key进行去模拆分到不同的表。
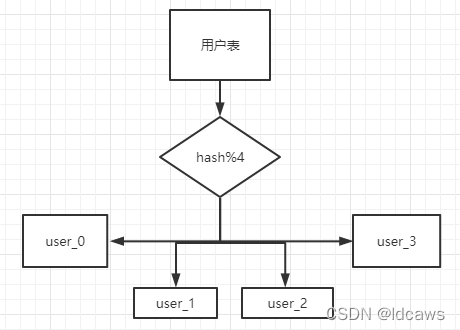
when/where
如果系统处于快速发展期,单机单库成为了性能瓶颈就需要考虑分库了。每天单表新增几十万,查询效率明显变慢时,就需要考虑分库分表了。一般B+树索引高度是2~3层最佳,如果数据量千万级别,可能高度就变4层了,数据量就会明显变慢了。mysql本身并没有对单表的最大记录数进行限制,这个数值取决于操作系统对单个文件的限制,单表的行数上限都是内存的限制。不过业界流传,一般500万数据或单表容量超过2GB就要考虑分表了。
problem
分库分表也会随之带来一些问题。
事务,分库分表后若是两个表在不同的数据库,那么事务失效,需要使用分布式事务。
关联查询,需要分开查询。
排序,需要在各自结果上在程序端进行合并。
分页,需要在各自结果上在程序端进行汇聚再分页。
分布式Id,数据库的主键需要使用分布式Id,如雪花算法生成的Id。
实现分库分表的中间件有很多,可自行选择,也可参考之前博客介绍的sharding-sphere。

















 754
754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









