 Hive分区操作详解
Hive分区操作详解





 本文介绍了Hive如何进行分区操作,包括创建分区、加载数据时添加分区、单独添加分区及删除分区。通过分区,可以有效地管理和提升查询效率。示例中展示了如何创建分区表、使用LOAD DATA指令添加数据到特定分区,以及如何通过ALTER TABLE命令单独添加和删除分区。强调了明确指定分区信息在查询中的重要性,以避免全表扫描导致的效率问题。
本文介绍了Hive如何进行分区操作,包括创建分区、加载数据时添加分区、单独添加分区及删除分区。通过分区,可以有效地管理和提升查询效率。示例中展示了如何创建分区表、使用LOAD DATA指令添加数据到特定分区,以及如何通过ALTER TABLE命令单独添加和删除分区。强调了明确指定分区信息在查询中的重要性,以避免全表扫描导致的效率问题。
1.创建分区
对表中的数据进行管理,并能提高查询效率,Hive的分区实际上就是表下创建子目录
创建表分区通过关键字PARTITIONED BY
CREATE TABLE IF NOT EXISTS tb1(
id int,
name string
)PARTITIONED BY (year int,month int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';


2.添加分区
2.1 加载数据时添加分区
load data local inpath '/home/omc/students.txt' into table tb1
PARTITION (year=2018,month=8);
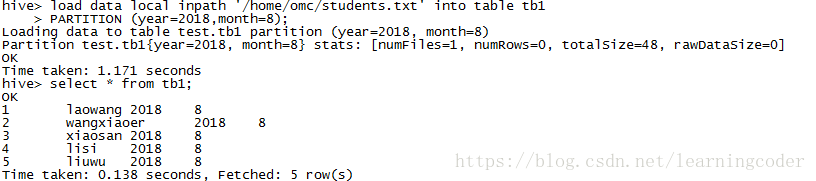

查询分区
show partitions tb1;

2.2 单独添加分区
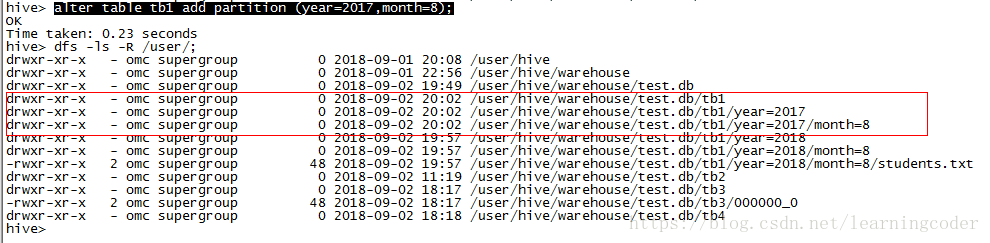
alter table tb1
add partition (year=2017,month=8);
虽然没有数据,但先把目录已经创建成功了
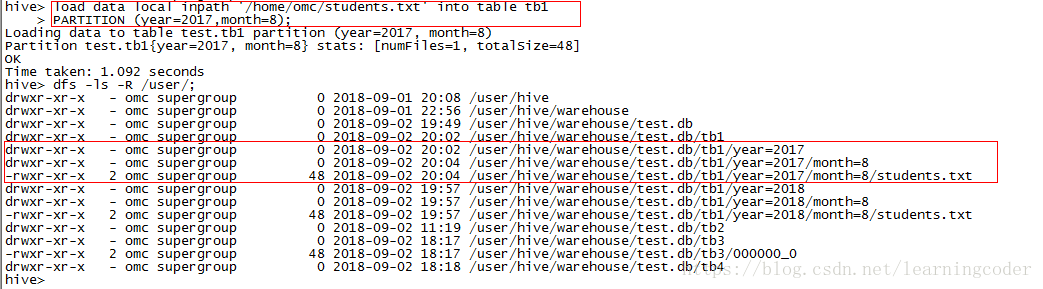
将同样的数据上传到year=2017/month=8目录下
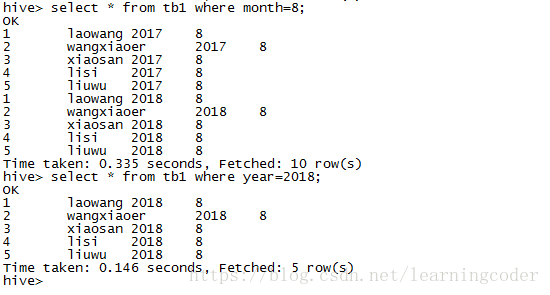
查询分区数据,不指定分区信息的话,会进行全表扫描,由于我们上传了两份一模一样的数据到两个分区,所以我们会查到重复记录

现实生产中,我们要指明分区信息来提高查询效率
select * from tb1 where month=8;
select * from tb1 where year=2018;
3.删除分区
alter table tb1
drop partition (year=2017);
hdfs上没有year=2017目录以及子目录
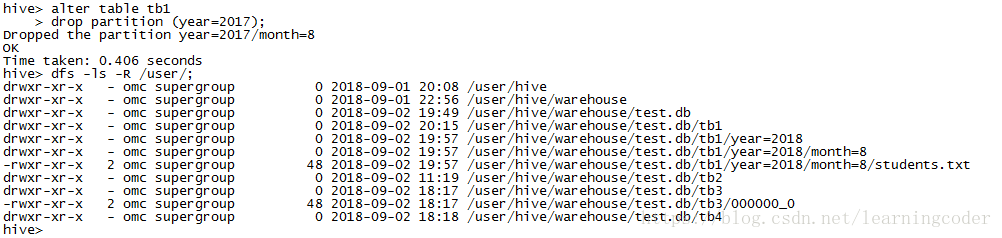
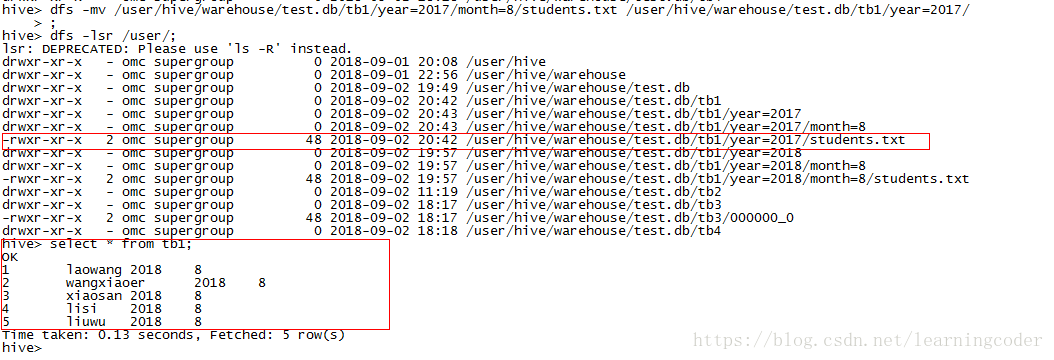
手工移动分区数据到其他目录下,结果无法查出。因为破坏了分区目录结构

















 4159
4159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









