







 本文介绍了pandas库中用于数据融合的两个关键方法——merge和join。join操作基于行索引进行,要求列名不重复,返回结果包含df1的所有行,df2的列如果不存在则用NaN填充。而merge则更接近关系型数据库的操作,通过列索引进行关联。此外,还提到了pandas的分组功能。
本文介绍了pandas库中用于数据融合的两个关键方法——merge和join。join操作基于行索引进行,要求列名不重复,返回结果包含df1的所有行,df2的列如果不存在则用NaN填充。而merge则更接近关系型数据库的操作,通过列索引进行关联。此外,还提到了pandas的分组功能。
df1

df2
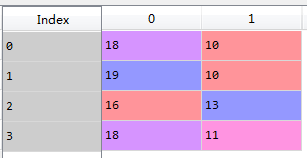
join是按照行索引来关联操作,列名不能相同
df1.join(df2) #返回df1的行数,df1和df2的所有列名 值没有的话用NaN
merge是按照列索引来关联操作,和关系型数据库很相近
1. df1.merge(df2,on=0) #等价于df1.0=df2.0
0 1_x 2 3 4 1_y
0 18 15 19 15 12 10
1 18 15 19 15 12 11
2 16 13 11 15 18 13
SELECT * FROM df1
JOIN df2 ON df1.[0]=df2.[0]
2. df1.merge(df2,left_on=3,right_on=0) #默认是inner
0_x 1_x 2 3 4 0_y 1_y
0 11 18 12 18 14 18 10
1 11 18 12 18 14 18 11
SELECT * FROM df1
JOIN df2 ON df1.[3]=df2.[0]
3. df1.merge(df2,left_on=3,right_on=0,how="outer")
0_x 1_x 2 3 4 0_y 1_y
0 18.0 15.0 19.0 15 12.0 NaN NaN
1 16.0 13.0 11.0 15 18.0 NaN NaN
2 10.0 16.0 15.0 14 16.0 NaN NaN
3 11.0 18.0 12.0 18 14.0 18.0 10.0
4 11.0 18.0 12.0 18 14.0 18.0 11.0
5 NaN NaN NaN 19 NaN 19.0 10.0
6 NaN NaN NaN 16 NaN 16.0 13.0
SELECT * FROM df1
FULL OUTER JOIN df2 on df1.[3]=df2.[0]
4. df1.merge(df2,left_on=3,right_on=0,how="left")
0_x 1_x 2 3 4 0_y 1_y
0 18 15 19 15 12 NaN NaN
1 10 16 15 14 16 NaN NaN
2 11 18 12 18 14 18.0 10.0
3 11 18 12 18 14 18.0 11.0
4 16 13 11 15 18 NaN NaN
SELECT * FROM df1
LEFT JOIN df2 on df1.[3]=df2.[0]
5. df1.merge(df2,left_on=3,right_on=0,how="right")
0_x 1_x 2 3 4 0_y 1_y
0 11.0 18.0 12.0 18 14.0 18 10
1 11.0 18.0 12.0 18 14.0 18 11
2 NaN NaN NaN 19 NaN 19 10
3 NaN NaN NaN 16 NaN 16 13
SELECT * FROM df1
RIGHT JOIN df2 on df1.[3]=df2.[0]
分组 group
grouped=df2.groupby([0]) #pandas.core.groupby.generic.DataFrameGroupBy
遍历分组
for i,j in grouped:
print(type(i),type(j))
print("$"*50)
print(i)
print("-"*50)
print(j)
print("*"*50
c=grouped.count()
select [0],count([1]),count([2])
from df2
group by [0]

















 552
552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









