




VIS除了用于细节特征提取还做了什么?
- 用于初步融合图像,这里的融合我理解为在图像级别的融合,而不是在特征级别。backbone部分知识学习到了一个IR的权重图M1,VIS保留程度就是1-M1。
马JY组有篇基于分解的文章是得到融合图像之后再一次分解成高频和低频做了约束。这里的细节特征提取分支就是对融合图像提取高频成分做约束,思想差不多。
本文不同于一般的IVIF融合框架(即分别提取源图像特征然后融合重建),本文的出发点就是把红外的显著信息和可见光的背景信息融合。
因此在encoder-decoder部分,只传入IR图像,用来生成一个M1权重图,用来初步融合图像。有两个分支用来监督中间encoder-decoder(backbone)。
VIS图像只用来提取细节特征(高频成分),因为IR中也有一些细节成分,所以细节特征提取分支的输入是IR和VIS,分别使用高斯模糊核提取了低频成分,然后源图像分别减去低频成分就得到了想要的高频成分(细节信息),然后基于最大值选择得到Dmax。
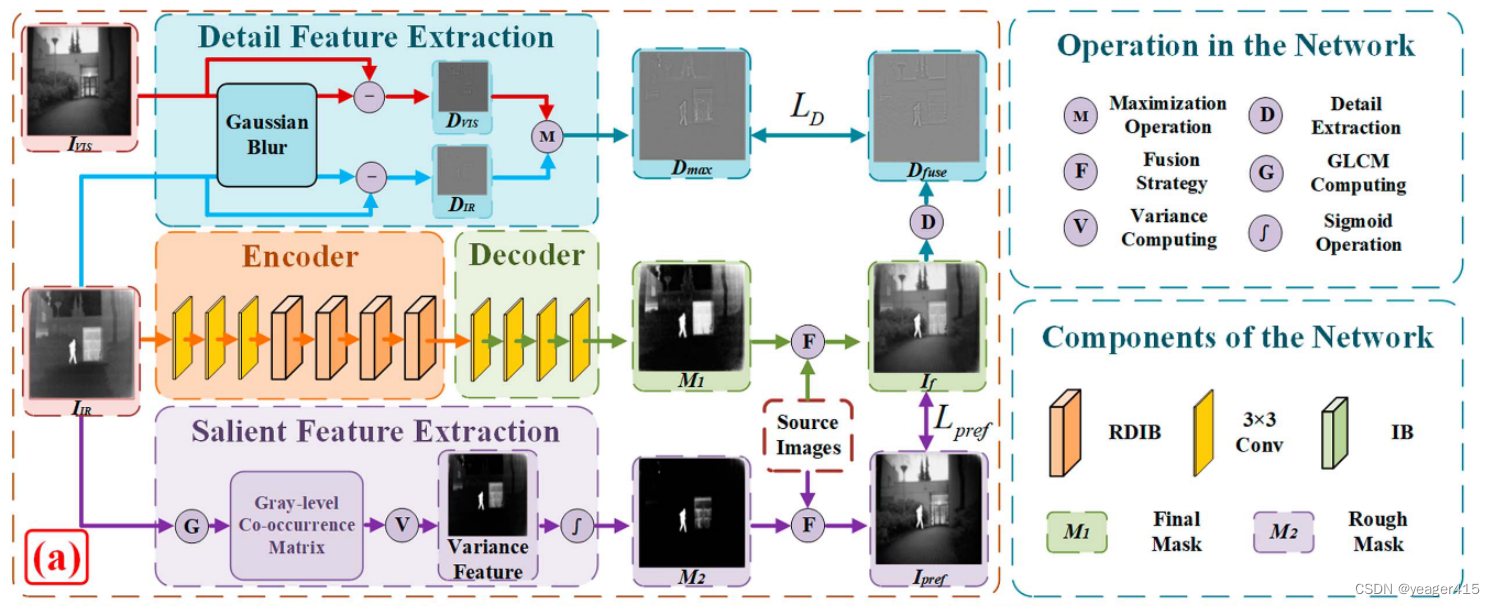
encoder提取红外特征,而decoder用来生成一个mask图M1。
另一个分支就是显著特征提取分支,*一些工作也使用一个额外的显著特征注入分支,为了突出IR中的显著目标。*不同的是,本文在这里提取显著特征之后经过sigmoid得到一个类似与M1的权重图M2,先初步生成一个融合图像,Ipref与基于M1生成的图像做监督。这里使用了灰度共生矩阵算法提取显著成分。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2914
2914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









