 CUDA编译及核函数调用错误解决示例
CUDA编译及核函数调用错误解决示例





今天开始整cuda编程处理图像,好久没玩cuda,又从小白开始。情况不妙,第一个工程坑不少,记录一下如下2个重要的错误:
(1)来自 CUDA 12.1.targets 的MSB3721错误
错误 命令““C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\bin\nvcc.exe” -XXXXX-C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\include" -I"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\include" -G --keep-dir x64\Debug -maxrregcount=0 --machine 64 --compile ”已退出,返回代码为 255。XXXXXX\CUDA 12.1.targets。
总之就是除了报这个错误,还有一长串别的都是跟sm_相关的错误,检查代码计算没有问题,就是编译一直一长串。。。
那么按照如下操作看看:
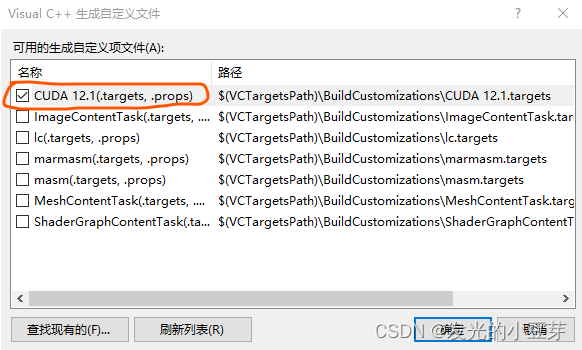
1)检查工程配置属性
鼠标落在解决方案上->右键->生成依赖项->生成自定义,查看确保已经选中如下:
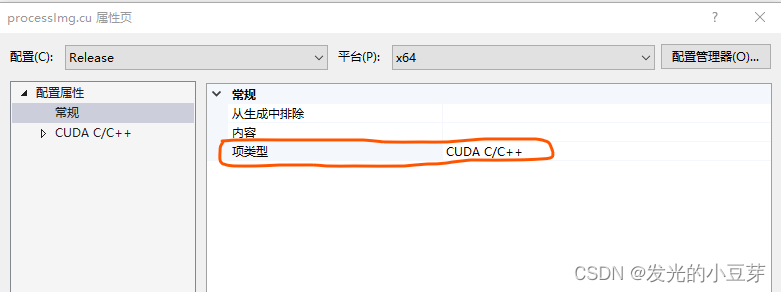
2)查看.cu文件的属性
鼠标落点.cu文件,右键->属性,查看项类型为如下:
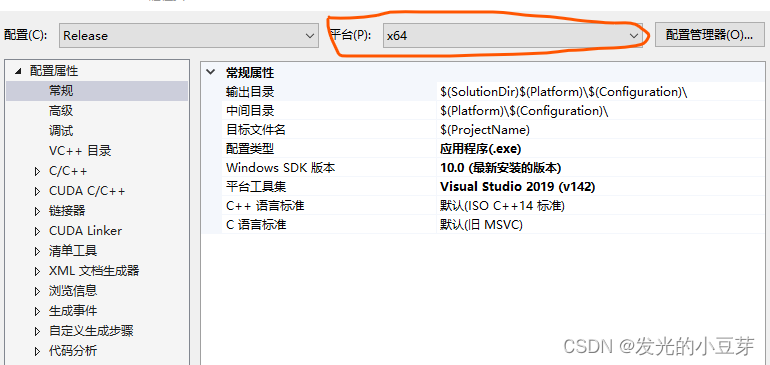
3)检查编译器,确保为X64(此处非常容易忽略)
查看状态栏:

查看解决方案->属性:
(2)提示调用语法错误‘<’
这个问题比较烦神,搜罗一圈都说cpp中不能直接调用核函数<<<,>>>,需要extern "c"去修饰,但是也不太明白怎么个修饰安置法。那么我再仔细理一下:
先上代码:
.cpp 文件如下:
#include "processImg.cuh"
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <iostream>
int main()
{
int N = 1 << 20;
int nBytes = N * sizeof(float);
// 申请host内存
float* x, * y, * z;
x = (float*)malloc(nBytes);
y = (float*)malloc(nByte 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2587
2587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









