







01
网络故障
01 交换机刚加电时网络无法通信
故障现象:
交换机刚刚开启的时候无法连接至其他网络,需要等待一段时间才可以。另外,需要使用一段时间之后,访问其他计算机的速度才快,如果有一段时间不使用网络,再访问的时候速度又会慢下来。
故障分析:
由于案例中的交换机是一台可网管交换机,为了避免网络中存在拓扑环,从而导致网络瘫痪,可网管交换机在默认情况下都启用生成树协议。
这样即使网络中存在环路,也会只保留一条路径,而自动切断其他链路。所以当交换机在加电启动的时候,各端口需要依次进入监听、学习和转发状态,这个过程大约需要3~5分钟时间。
如果需要迅速启动交换机,可以在直接连接到计算机的端口上启动“PortFast”,使得该端口立即并且永久转换至转发状态,这样设备可以立即连接到网络,避免端口由监听和学习状态向转发状态过渡而必须的等待时间。
解决方法:
如果需要在交换机加电之后迅速实现数据转发,可以禁用扩展树协议,或者将端口设置为PortFast模式。
不过需要注意的是,这两种方法虽然省略了端口检测过程,但是一旦网络设备之间产生拓扑环,将导致网络通信瘫痪。
02 “COL”指示灯长亮或不断闪烁,无法实现通信
故障现象:
局域网中计算机通过集线器访问服务器,但是某日发现所有客户端计算机无法与服务器进行连接,客户机之间Ping也时断时续。检查集线器发现“COL”指示灯长亮或不断闪烁。
故障分析:
“COL”指示灯用于指示网络中的碰撞和冲突情况。“COL”灯不停闪烁,表明冲突发生;
“COL”灯长亮则表示有大量冲突发生。导致冲突大量发生的原因可能是集线器故障,也可能是网卡故障。
一般情况下,网卡出现故障的可能性比较小,因此将重点放在对集线器的排除方面。
解决方法:
更换集线器,网络恢复正常。
03 升级至千兆网络之后,服务器连接时断时续
故障现象:
原先服务器采用10/100MbIT/s网卡,运行一切正常。但是安装了一款1000MbIT/s网卡,用其连接至中心交换机的1000Base-T端口之后,服务器与网络的连接时断时续,连接极不稳定,无法提供正常的网络服务。使用网线测试仪测试网络,发现双绞线链路的连通性没有问题。
故障分析:
在100Mbit/s时连接正常,只是在升级到1000Mbit/s时才发生故障,看来导致这种故障的原因可能是超五类布线问题。
虽然从理论上说超五类系统支持1000Mbit/s的传输速率,但是如果双绞线、配线架、网线和其他网络设备的品质不是很好,或者端接工艺有问题,就仍然无法实现1000Mbit/s带宽。
由于1000Base-T需要使用双绞线全部的4对线,每对线的有效传输速率为250Mbit/s,并完成全双工传输,因此1000Base-T对双绞线的信号衰弱减、回波、返回耗损、串音和抗电磁干扰等电气性能有了更高的要求。如果双绞线或者其他配件的性能不好,就会在线对间产生严重串扰,从而导致通信失败。
解决方法:
考虑到五类布线系统的性能有可能无法满足千兆网络系统,因此更换为六类布线产品之后故障解决。
04 尽管Link灯不停闪动,但网速却奇慢
故障现象:
服务器上网速度很慢,开始时打开网页非常缓慢,后来甚至连网页都无法打开,Ping网站也无法解析地址。
起初以为是DNS设置或者服务器故障,但是这些都正常运行。尝试Ping其他计算机,发现丢包率很高。而此时交换机的Link指示灯不停闪烁,数据的交换非常频繁,说明计算机在不停地发送和接受数据包。
关闭交换机之后再重新打开,故障现象得到缓解,但是一段时间之后又出现这种故障。
故障分析:
从故障现象来看,这是网络内的广播风暴。广播风暴的产生会有很多种原因,比如蠕虫病毒、交换机端口故障、网卡故障、链路冗余而没有启用生成树协议、网线线序错误或者受到干扰等。
在网络故障发生的时候查看交换机指示灯是一个很便捷的判断方法,可以直观查看网络连通性和网络流量。
解决方法:
就目前情况来看,蠕虫病毒是造成网络瘫痪的最主要原因。
及时为服务器更新系统补丁,并且安装网络版本的病毒查杀软件,及时为服务器升级病毒库,在服务器安装防病毒客户端程序之后,故障得以解决。
05 集线器和路由器无法共享上网
故障现象:
多台计算机采用宽带路由器和集线器方式,利用集线器扩展端口组网共享Internet。
连接完成后,直接连接至宽带路由器LAN口的3台机器能上网,而通过集线器连接的计算机却无法上网,路由器与集线器之间无论采用交叉线或平行线都不行,且集线器上与路由器LAN端口连接的灯不亮。
另外,集线器上的计算机无法Ping通路由器,也无法Ping通其他计算机。
故障分析:
-
集线器自身故障
故障现象是集线器上的计算机彼此之间无法Ping通,更无法Ping通路由器。该故障所影响的只能是连接至集线器上的所有计算机。
-
级联故障
例如路由器与集线器之间的级联跳线采用了不正确的线序,或者是跳线连通性故障,或者是采用了不正确的级联端口。故障现象是集线器上的计算机之间可以Ping通,但无法Ping通路由器。不过,直接连接至路由器LAN端口的计算机的Internet接入将不受影响。
-
宽带路由器故障
如果是LAN端口故障,结果将与级联故障类似:如果是路由故障,结果将是网络内的计算机都无法接入Internet,无论连接至路由器的LAN端口,还是连接至路由器。
解决方法:
从故障现象上来看,连接至集线器的计算机既无法Ping通路由器,也无法Ping通其他计算机,初步断定应该是计算机至集线器之间的连接故障。
此时可以先更换一根网线试试,如果依然无法排除故障,则可以更换集线器解决。
06 IP地址冲突
故障现象:
计算机经常出现提示——“系统检测到IP地址xxx.xxx.xxx.xxx和网络硬件地址00 05 3B 0C 12 B7发生地址冲突。此系统的网络操作可能会突然中断”,然后就掉线一分钟左右又恢复网络连接。
故障分析:
这种系统提示是典型的IP地址冲突,也就是该计算机采用的IP地址与同一网络中另一台计算机的IP地址完全相同,从而导致通信失败。与该计算机发生冲突的网卡的Mac地址是“00 05 3B 0C 12 B7”。
通常情况下,IP地址冲突是由于网络管理员IP地址分配不当,或其他用户私自乱设置IP地址所造成的。
解决方法:
由于网卡的Mac地址具有唯一性,因此借助于MAC地址查找到与你发生冲突的计算机,并修改IP地址。
使用“IPCONFIG /ALL”命令,即可查看计算机的IP地址与MAC地址。最后使用“ARP –S IP地址 网卡物理地址”的命令,将此合法IP地址与你的网卡MAC地址进行绑定即可。@网络工程师俱乐部
02
系统故障
(此处以Linux系统为主)
01 linux系统无法启动
原因1:文件系统配置不当,比如/etc/fstab文件等配置错误或丢失,导致系统错误无法启动。一般是人为修改错误或者文件系统故障。
排查方法:
系统配置/etc/fstab错误或丢失而无法启动,当启动的时候,出现starting system logger后停止了;
解决方法:
想办法恢复/etc/fstab文件,利用linux rescue修复模式登录系统,从而获取挂载点和分区信息,重构/etc/fstab文件。
原因2:非法关机,导致root文件系统破坏,也就是linux根分区破坏,系统无法正常启动。
排查方法:
Linux下普遍采用的是ext3文件系统,ext3是一个具有日志记录功能的日志文件系统,可以进行简单的容错和恢复,但是在一个高负荷读写的ext3文件系统下,如果突然发生掉电,就很有可能发生文件系统内部结构不一致,导致文件系统破坏。
Linux在启动时,会自动去分析和检查系统分区,如果发现文件系统有简单的错误,会自动修复,如果文件系统破坏比较严重,系统无法完成修复时,系统就会自动进入单用户模式下或者出现一个交互界面,提示用户介入手动修复,现象类似下面所示:
checking root filesystem
/dev/sdb5 contains a file system with errors, check forced
/dev/sdb5:
Unattached inode 68338812
/dev/sdb5: UNEXPECTED INCONSISTENCY; RUN fsck MANUALLY
(i.e., without -a or -p options)
FAILED
/contains a file system with errors check forced
an eror occurred during the file system check
*dropping you to a shell;the system will reboot
when you leave the shell
Press enter for maintenance
(or type Control-D to continue):
give root password for maintenance
从这个错误可以看出,系统根分区文件系统出现了问题,系统在启动时无法自动修复,然后进入到了一个交互界面,提示用户进行系统修复。
这个问题发生的机率很高,引起这个问题的主要原因就是系统突然掉电,引起文件系统结构不一致。一般情况下解决此问题的办法是采用fsck命令,进行强制修复。
解决方法:
根据上面的错误提示,当按下“Control-D”组合键后系统自动重启,当输入root密码后进入系统修复模式,在修复模式下,可以执行fsck命令,具体操作过程如下:
[root@localhost /]#umount /dev/sdb5
[root@localhost /]#fsck .ext3 -y /dev/sdb5
e2fsck 1.39 (29-May-2006)
/ contains a file system with errors, check forced.
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Inode 6833812 ref count is 2, should be 1. Fix? yes
Unattached inode 6833812
Connect to /lost+found? yes
Inode 6833812 ref count is 2, should be 1. Fix? yes
Pass 5: Checking group summary information
Block bitmap differences: -(519--529) -9273
Fix? yes…… ……
/: * FILE SYSTEM WAS MODIFIED **
/: 19/128520 files (15.8% non-contiguous), 46034/514048 blocks
需要注意的是,在执行fsck的时候,一定要先卸载要修复的分区,然后再执行修复操作!@网络工程师俱乐部
原因3:linux内核文件丢失或者崩溃,从而无法启动,也可能是因为内核升级错误或者内核存在bug。
这种情况一般linux系统启动会报错找不到内核文件,而内核文件存储在/boot分区,主要包括内核文件和初始化文件:
1、vmlinuz:内核镜像文件,包含内核代码和数据
显示error: file'/vmlinuz'not found
解决方案:
a. 使用可启动修复介质启动系统,并挂载系统磁盘的/boot分区;
b. 从安装介质或系统备份中提取vmlinuz内核文件,复制到/boot分区;
c. 更新引导配置(grub.cfg),将menuentry块中的linux行指向vmlinuz内核文件;
d. 重启系统,在引导菜单选择更新后的菜单项启动系统。
2、initrd/initramfs:初始化RAM磁盘,包含启动时需要的模块和驱动
显示error: file'/initrd.img'not found
解决方案:
a. 参考内核文件丢失的解决步骤a,挂载/boot分区和获取initrd.img文件;
b. 将initrd.img文件复制到/boot分区;
c. 更新grub.cfg,找到initrd相关行,将其指向新文件;
d. 重启系统,启动更新后的菜单项。
原因4:硬件故障,比如主板、电源、硬盘等出现问题,导致linux无法启动。
解决方法:一般来说由硬件造成的故障,只需更换硬件设备即可解决。
02 linux系统网络故障
排查1:检查网络硬件
检查网络故障,首先要排除网络硬件设备是否存在问题。比如网卡,网线,路由器,交换机等设备是否正常。
这些是网络正常运行的基本条件,如果发现某些设备出现故障,只需更换硬件即可解决问题。
排查2:检查网卡是否正常工作
1、检查网卡是否正常加载
可以通过 ifconfig 命令判断网卡是否正常加载。如果通过 ifconfig 可以显示网络接口的配置信息,表示系统找到网卡驱动程序,网卡加载正常;
解决方法:如果发现问题网卡,我们可以使用 ethtool 工具查看问题网卡的具体状态信息
(注意:Speed / Link deteced 等字段 )
2、检查网卡IP设置是否正确
接下来就要检查网卡的软件设定,比如IP是否配置,配置是否正确,确保IP的配置和局域网其它计算机配置没有冲突。
排查3:检查局域网内主机能否互连
检查网络之间的连通是否存在故障,可以先通过ping命令测试局域网主机之间的连通性,然后ping网关,检测主机到网关的通信是否正常。
排查4:检查系统路由表信息是否正确
检查系统路由表状态是处理网络故障的一种很重要的方法。很多时候都是 ip 地址没有配错,网卡也正常加载但是路由配置不正确,而导致网络问题的出现。@网络工程师俱乐部
因此需要检查系统的路由表设置是否正确,如果一个linux系统有两块网卡,同时两块网卡设置的IP不在一个网段,要特别注意系统路由表的设置。例如下面这个系统的网络接口信息:

从上面输出可知,本系统有两块网卡,分别配置不同网段的IP地址,假定eth0通过映射的方式对外提供ssh连接服务,而eth1仅供局域网主机之间共享数据使用。
现在的问题是,外界无法ssh远程登录到此系统,而网卡加载没有问题,网卡IP设置也没问题,接下来看看此系统的路由设置:
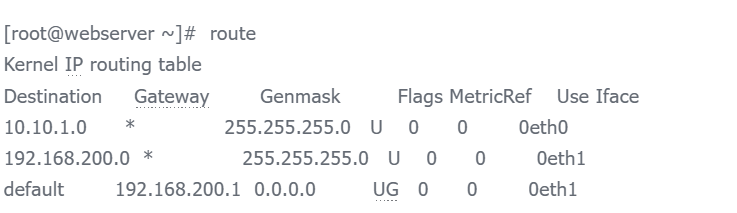
至此问题已经基本排查出来了:从route的输出可知,linux的缺省路由是192.168.200.1,而192.168.200段的IP仅仅供局域网主机之间共享数据使用,没有连接出去的访问权限,因而,外界无法连接到linux系统。
解决方法:
删除192段的缺省路由,然后增加10段的缺省路由即可:
[root@webserver ~]# route delete default
[root@webserver ~]#route add default gw 10.10.1.254
此时外界就可以通过ssh服务远程连接到linux系统了。
排查5:检查DNS解析
在Linux系统中,有两个文件用来指定系统到哪里寻找相关域名解析的库。分别是文件/etc/host.conf和/etc/nsswitch.conf。
/etc/host.conf文件指定系统如何解析主机名,Linux通过域名解析库来获得主机名对应的IP地址。
下面是RedHat Linux安装后缺省的/etc/host.conf内容:
order hosts,bind
其中,order指定主机名查询顺序,这里表示首先查找/etc/hosts文件对应的解析,如果没有找到对应的解析,接着就根据/etc/resolve.conf指定的域名服务器进行解析。
/etc/nsswitch.conf文件是由SUN公司开发的,用于管理系统中多个配置文件查询的顺序,由于nsswich.conf提供了更多的资源控制方式,nsswich.conf文件现在已经基本取代了hosts.conf,虽然LINUX系统中默认这两个文档都存在,但实际上起作用的是 nsswitch.conf文件。
nsswitch.conf文件每行的配置都以一个关键字开头,后跟冒号,紧接着是空白,然后是一系列方法的列表。例如这段信息:
hosts: files dns
表示系统首先查询主机库文件,如果没有找到对应的解析,接着会去DNS配置文件指定的DNS服务器进行解析。 @网络工程师俱乐部
清楚了linux下域名解析的原理和过程,我们就可以根据这两个文件的设定,确定解析的顺序,从而判断出域名解析可能出现的问题。
排查6:检查相关服务是否开启
在一个应用出现故障时,必须要检测服务本身。比如服务是否开启,配置是否正确等。
检查服务是否正确打开,分为两步,第一步是查看服务的端口是否打开:
例如,我们不能用root用户ssh登录到192.168.60.133这台linux服务器,首先检查sshd服务的22端口是否打开:
[root@localhost init.d]# telnet 192.168.60.133 22SSH-2.0-Open
SSH_4.3
这个输出表示192.168.60.133的22端口对外开放,或者可以说sshd服务是处于打开状态。如果没有任何输出,可能是服务没有启动,或者服务端口被屏蔽。也可以在服务器上通过netstat命令检查22端口是否打开:

可以看到,22端口在服务器上是打开的,同时,服务器上打开的还有3306、80端口。
接着进行第二步的检查,既然服务已经打开,可能是sshd服务配置的问题,检查sshd服务配置文件/etc/ssh/sshd_config是否正确,发现有下面一行信息:
PermitRootLogin no
由此可知是ssh服务端配置文件限制了root用户不能登录系统,如果需要root登录系统,只需更改为如下即可:
PermitRootLogin yes
到这里为止,我们通过对端口和服务配置文件的层层检查,最终找到了问题的根源。需要说明的是,这里的重点不是讲述如何让root登录linux系统,而是要通过这个例子学会处理类似问题的思路和方法。
排查7:检查访问权限是否打开
1、检查系统防火墙 iptables的状态
当某些服务不能访问时,一定要检查是否被linux本机防火墙iptables屏蔽了,可以通过iptables -L指令查看iptables的配置策略。
例如我们不能访问某台linux服务器提供的www服务,通过检查,系统网络、域名解析都正常,并且服务也正常启动,然后检查了服务器的iptables策略配置,信息如下:

从上面的输出可知,这个linux服务器仅仅设置了预设策略,而致命的是将INPUT链和OUTPUT链都设置为DROP,也就是所有外部数据不能进入服务器,服务器数据也不能出去,这样的设置相当于没有网络。为了能访问这台服务器提供的www服务,增加两条策略即可:

这样一来,internet上的其他人就能访问我们的www服务了。
2、检查 SELinux 是否打开
SELinux是个系统级的安全防护工具,可以最大限度的保障Linux系统的安全。但是selinux有时也会给linux下软件 的运行带来一些问题,这些问题大部分是对selinux不了解造成的。
为了迅速定位问题,最简单的方法是先关闭selinux,然后测试软件运行是否正常,这不是个好方法,但是对于判断问题往往是很有用的。@网络工程师俱乐部
selinux是个很好的安全访问控制软件,可是如果你还不能熟练运用selinux访问控制策略的话,还是建议将它暂时关闭,等到对linux有了更深入的认识后,再开启selinux不失为一个明智的策略。
03 MBR扇区故障
故障现象:
1、找不到引导程序,启动中断
2、无法加载操作系统,开机后黑屏
故障原因:
1、病毒、木马等造成的破坏
2、错误的分区操作,磁盘读写错误操作
解决方法:
1、备份MBR扇区数据
a.在关机状态下添加一块新硬盘:虚拟机-->硬盘-->添加-->选择硬盘-->下一步
b.启动主机进入Linux系统,并对新硬盘进行分区
查看硬盘分区情况:fdisk -l -->对新硬盘进行分区:fdisk/dev/sdb
c.建立新硬盘的文件系统(即格式化文件系统)
查看sdb磁盘的列表信息-->对磁盘进行格式化
d.挂载硬盘
创建挂载点-->挂载分区
e.备份MBR扇区数据
2、模拟MBR扇区被破坏的故障
重启计算机,当出现“Operating system not found”的提示信息,表示无法找到可用的操作系统,此时硬盘已经损坏,如果没有光盘引导,则系统一直处于如下状态,因此无法启动主机。@网络工程师俱乐部
3、进入急救模式来修复MBR扇区故障
a.先关闭计算机-->虚拟机-->电源-->打开电源时进入固件(F)-->选择Boot-->将光盘放在第一位
b.选择进入急救模式[Rescue installed system]
c.[choose a language]选择English-->确认
d.[Keyboard type]选择us-->确认
e.[Unsupported Hardware Detected]选择OK
f.[Satup Networking]选择No
g.[Rescue]选择Skip
h.选择Shell Start shell-->选择Ok
i.查看/dev/sdb硬盘和/dev/sda硬盘,能看到sdb1分区,看不到sda设备,因为sda设备的MBR被破坏
j.将之前拷贝的文件重新写回来
4、重启计算机,发现可以正常启动计算机,说明修复了MBR扇区故障。
04 GRUB引导故障
故障现象:
系统引导停滞,显示“grub>”提示符
故障原因:
有时Linux启动后会直接进入GRUB命令行界面(只有“grub>”提示符),此时很多用户就选择了重新安装GRUB甚至重新安装系统。
其实一般而言此故障的原因最常见的有两个:
一是GRUB配置文件中选项设置错误;
二是GRUB配置文件丢失。
若是第一种情况,则一般显示error: you need to load the kernel first: 引导配置错误,内核文件没有被正确加载,提示先加载内核。
解决方案:
a. 启动系统修复介质,备份/boot分区文件;
b. 检查/boot/grub2/grub.cfg文件,找到menuentry块中linux和initrd行,确保它们正确指向vmlinuz和initrd.img文件;
c. 重启系统,进入BIOS将引导选项设置为启动磁盘,保存后重启;
d. 启动grescue grub>提示符,运行:
set prefix= (root) ′ /boot/grub2 ′configfile(prefix)/grub.cfg
boot
命令以修复并重新加载grub配置,然后启动系统。
若是第二种情况,GRUB rescue> : 当GRUB引导加载程序文件丢失或磁盘无法访问时,会结束在rescue提示符。
解决方案:
a. 启动系统安装或修复介质,备份数据并检查文件系统。使用fsck修复或使用娱乐用光盘工具修复磁盘问题;@网络工程师俱乐部
b. 引导进入安装系统,运行grub2-install /dev/sda将GRUB重新安装至系统磁盘MBR;
c. 修改BIOS启动选项为从系统磁盘启动。重启系统,现GRUB菜单应可正常显示,启动系统;
d. 如果仍无法启动,可能需要重新安装系统或更换硬件。
05 忘记linux root密码
很多人经常会忘记Linux系统的root密码,而着急选择重新安装系统,这里为大家整理了两个更加直接的解决方法:
1、进入急救模式重设root用户密码
进入急救模式,加载系统镜像,切换到系统根环境进行重置root密码:
a.打开电源时进入固件,将开机启动项boot中的CD-ROM调到第一项;
b.进入急救模式:
sh-4.2# chroot /mnt/sysimage
#重设root用户密码
bash-4.2# passwd root
bash-4.2# exit //退出镜像回到系统
sh-4.2# reboot //重启系统(注意重启后要进入固件将Hard-drive调至第一项)
c.重启进入登入界面后输入刚才设置的密码即可;
2、进入单用户模式进行修改root密码:
以Redhat linux为基准,操作步骤如下:
a.重启系统,待linux系统启动到grub引导菜单时,找到当前系统引导选项(可以按方向键展开隐藏的菜单,单处理器只有一个引导项,多处理器有3个或3个以上引导项,一般默认选项就是系统当前引导选项);
b.通过方向键将光标放到当前系统引导项上,然后按键盘字母“e”,进入编辑状态。
c.然后通过上下键,选中带有kernel指令的一行,继续按键盘字母“e”,编辑该行,在行末尾加个空格,然后添加single,类似与这样:kernel /vmlinuz-2.6.18-8.el5 ro root=LABEL=/ rhgb quiet single
d.修改完成,按回车键,返回到刚才的界面。
e.最后按键盘“b”,系统开始引导。这样系统就启动到了单用户模式下,这里的单用户和windows下的安全模式类似,在单用户模式下,只是启动最基本的系统,网络以及应用服务均不启动。@网络工程师俱乐部
单用户模式启动完毕,系统会自动进入到命令行状态下,类似与“sh-3.1#”,然后直接执行passwd,回车,系统会提示输入新的root密码两次,最后会看到修改密码成功的提示,这样就完成了root密码的修改。
如果需要正常启动系统,现在只需输入“init 3”,就进入了多用户模式。用root用户重新登录系统,看看设置的新密码是否生效。
06 Read-only file system 错误解决
故障现象:
涉及到修改/保存条目等需要写磁盘操作的命令都无法使用(如tar、cp、mv、rm、chmod、chown、wget下载等指令),总是提示Read-only file system,也就是说系统是只读的,什么也写不了。
故障原因:
1.文件系统损坏;
2.磁盘问题,磁盘又坏道;
3.fstab文件配置错误,如分区格式错误错误(将ntfs写成了fat)、配置指令拼写错误等。
排查网站程序,看报错信息和服务日志错误,以及系统日志,来定位问题所在。
解决方法:
①如果能够确认数据和系统的文件没有被损坏,修复fstab文件配置后只要重新R/W加载或reboot就能够恢复正常。
以读写方式重新挂载文件系统
mount -o rw,remount /system
②如果是文件系统有问题,那就需要在umount状态下执行fsck命令来检查文件系统并修复文件系统中的错误。
nohup fsck -y /dev/VolGroup00/LogVol00 > /dev/shm/fscklog & # 检查好后重启 reboot
③如果是磁盘硬件损坏,最好的方法就是直接换一个新硬盘。如果觉得旧硬盘扔了可惜,还可以将它低格之后,再重新安装系统,系统重新安装后,磁盘会重新分区。@网络工程师俱乐部
④如果仅仅是想将数据备份出来而且机器又在身边的话,你可以用live-cd从光盘启动系统,然后直接备份。当然此时你也可以修改硬盘中的配置文件,如/etc/fstab。
03
硬件故障
01 设备本身的散热故障
无论是服务器、交换机、还是路由器,运行时间长了,都会出现散热问题,会不会报故障(或者说多长时间后报故障)、给网络效率造成多大的影响,一定程度上取决于机房的环境。
其中灰尘就是散热问题的最大来源,好在这类故障处理起来很容易,收到告警信息后,更换散热器能解决90%的问题。
除此之外,不能排除有一部分设备,是主板上的针脚不再给散热风扇供电的原因,这就需要想办法给风扇供电。
02 电源模块故障
电源完全损坏,不再供电的时候,如果没有冗余配置,这时候设备肯定已经被动关机了,直接替换新的电源即可,但有的时候,电源的故障并不是那么明显。
案例:某服务器频繁死机,每次重启后,能正常运转一天两天,一时找不出原因,有次正好在机房维护,听到该服务器有蜂鸣声,此时服务器还没有死机,查询日志无异常便重启,进入BIOS查看,发现电源有高压报警——12V输出,达到了16V!
因为有冗余电源,直接把故障电源拔下来,服务器就恢复了正常。
03 主板老化或者元器件损坏
这类故障不是很明显,但会直接导致设备不稳定或宕机。@网络工程师俱乐部
案例:
有台服务器年代久远,不稳定,三天两头要重启,有时也报高温故障,于是决定拆下来彻底清理一遍,到客户的生产车间,用风枪吹干净,感觉主板像新的一样,但是服务器点不亮了;
仔细查看才发现CPU周围有几个电容鼓包了,甚至有爆浆,换上好的电容之后,问题也就解决了。同样的的方法,也可以修好交换机主板、电脑主板、显卡等等。
但是大多数时候,设备一旦出现元器件损坏,就未必能修好。就算修好,也不再建议当成主要设备来使用了,作为备用件是不错的选择。
04 硬盘或者内存等主要配件故障
硬盘故障最为麻烦,例如,RAID1或者RAID5是服务器中常见的配置,这种情况下,损坏一块硬盘还好,一般不会有什么损失,换个新的也就解决了;
比较麻烦的是阵列中多块硬盘损坏的情况,如果数据非常重要,一定需要交给专业公司处理,盲目地操作只会增加数据恢复的难度。
04
软件故障
01 更新的补丁导致系统或者应用软件崩溃
案例:微软Win10频频翻车,多个补丁都引发了较大数量的蓝屏故障,其实重启后,卸载补丁也就没事了。但是当年赛门铁克误杀门,崩溃的电脑和服务器,真是不计其数。
正确的做法是:补丁要先给测试机更新,两三天后,没什么问题,再大面积部署,即便如此,还是要定期做好系统的状态备份,万一有事儿,还能快速恢复。
02 病毒及恶意程序的破坏
尽管部署了企业级的硬件防火墙、专业级的安全软件,对于病毒及恶意程序,也不能掉以轻心。
病毒和恶意程序破坏,往往是不可修复的,常见的病毒或者恶意程序,我们能用防火墙成功隔离或者安全软件成功查杀。@网络工程师俱乐部
但是每隔一段时间,总会有个超级病毒,能穿过各种安全设备和软件,对我们的系统造成破坏,致使我们蒙受巨大的损失:
比如疯狂的勒索病毒,很多公司的服务器都中招了,有的迫于数据的重要性,只能给黑客付钱,还必须是比特币!也有的付了钱,都没能拿回所有的数据。
所以重要的数据文件,冷备份很有必要!即准备一台电脑或者服务器,只在定期备份的时候开机,备份完毕立即关机,确保数据安全。
03 同时安装多个功能类似的安全软件
有些IT盲目自信,服务器上不安装任何安全软件,也有些IT人员在服务器(或者电脑)上安装功能类似或者重复的安全软件。
殊不知,这会造成系统混乱、不稳定,有的在服务器同时安装两款国产的杀毒软件后,操作系统直接无法启动了,只能进入安全模式强制卸载其中一款,才解决问题。
所以说,杀毒软件、安全助手类软件,同一台服务器或者电脑上,最好只安装一款。
04 同时安装同一软件的多个版本
案例:经常接到客户的求助,说是xx软件突然打不开了,细问才知,原来是同一软件装了两三个版本,卸载其中一个版本后,另一个版本也无法运行了。
其实这种情况应该是在软件卸载的时候,删除了相关的系统文件,导致另外一个版本缺少关键文件,也就无法运行了;
想要覆盖安装还不一定能行,有时候会提示软件已存在,那就只能卸载重装,或者选择修复。
个人电脑无所谓,最多麻烦一点,几次重装而已,但是服务器上要安装同一软件的多个版本,就要慎重了。@网络工程师俱乐部
强烈建议先用虚拟机测试,确定没问题,再正式安装。
总结
以上故障修复的一般思路和通用策略,而现实遇到的问题都是千差万别的,每个问题的处理都不尽相同。
只有理解故障发生的规律、掌握故障管理的方法,做好复盘和改进,持续归纳总结和反思,才能做好对故障的管理。
既然无法彻底摆脱它,那就理解它、掌控它吧!
这两年,IT行业面临经济周期波动与AI产业结构调整的双重压力,确实有很多运维与网络工程师因企业缩编或技术迭代而暂时失业。
很多人都在提运维网工失业后就只能去跑滴滴送外卖了,但我想分享的是,对于运维人员来说,即便失业以后仍然有很多副业可以尝试。
运维,千万不要再错过这些副业机会!
第一个是知识付费类副业:输出经验打造个人IP
在线教育平台讲师
操作路径:在慕课网、极客时间等平台开设《CCNA实战》《Linux运维从入门到精通》等课程,或与培训机构合作录制专题课。
收益模式:课程销售分成、企业内训。
技术博客与公众号运营
操作路径:撰写网络协议解析、故障排查案例、设备评测等深度文章,通过公众号广告、付费专栏及企业合作变现。
收益关键:每周更新2-3篇原创,结合SEO优化与社群运营。
第二个是技术类副业:深耕专业领域变现
企业网络设备配置与优化服务
操作路径:为中小型企业提供路由器、交换机、防火墙等设备的配置调试、性能优化及故障排查服务。可通过本地IT服务公司合作或自建线上接单平台获客。
收益模式:按项目收费或签订年度维护合同。
远程IT基础设施代维
操作路径:通过承接服务器监控、日志分析、备份恢复等远程代维任务。适合熟悉Zabbix、ELK等技术栈的工程师。
收益模式:按工时计费或包月服务。
网络安全顾问与渗透测试
操作路径:利用OWASP Top 10漏洞分析、Nmap/BurpSuite等工具,为企业提供漏洞扫描、渗透测试及安全加固方案。需考取CISP等认证提升资质。
收益模式:单次渗透测试报告收费;长期安全顾问年费。
比如不久前跟我一起聊天的一个粉丝,他自己之前是大四实习的时候做的运维,发现运维7*24小时待命受不了,就准备转网安,学了差不多2个月,然后开始挖漏洞,光是补天的漏洞奖励也有个四五千,他说自己每个月的房租和饭钱就够了。
为什么我会推荐你网安是运维人员的绝佳副业&转型方向?
1.你的经验是巨大优势: 你比任何人都懂系统、网络和架构。漏洞挖掘、内网渗透、应急响应,这些核心安全能力本质上是“攻击视角下的运维”。你的运维背景不是从零开始,而是降维打击。
2.越老越吃香,规避年龄危机: 安全行业极度依赖经验。你的排查思路、风险意识和对复杂系统的理解能力,会随着项目积累而愈发珍贵,真正做到“姜还是老的辣”。
3.职业选择极其灵活: 你可以加入企业成为安全专家,可以兼职“挖洞“获取丰厚奖金,甚至可以成为自由顾问。这种多样性为你提供了前所未有的抗风险能力。
4.市场需求爆发,前景广阔: 在国家级政策的推动下,从一线城市到二三线地区,安全人才缺口正在急剧扩大。现在布局,正是抢占未来先机的黄金时刻。
1. 阶段目标
你已经有运维经验了,所以操作系统、网络协议这些你不是零基础。但要学安全,得重新过一遍——只不过这次我们是带着“安全视角”去学。
2. 学习内容
**操作系统强化:**你需要重点学习 Windows、Linux 操作系统安全配置,对比运维工作中常规配置与安全配置的差异,深化系统安全认知(比如说日志审计配置,为应急响应日志分析打基础)。
**网络协议深化:**结合过往网络协议应用经验,聚焦 TCP/IP 协议簇中的安全漏洞及防护机制,如 ARP 欺骗、TCP 三次握手漏洞等(为 SRC 漏扫中协议层漏洞识别铺垫)。
**Web 与数据库基础:**补充 Web 架构、HTTP 协议及 MySQL、SQL Server 等数据库安全相关知识,了解 Web 应用与数据库在网安中的作用。
**编程语言入门:**学习 Python 基础语法,掌握简单脚本编写,为后续 SRC 漏扫自动化脚本开发及应急响应工具使用打基础。
**工具实战:**集中训练抓包工具(Wireshark)、渗透测试工具(Nmap)、漏洞扫描工具(Nessus 基础版)的使用,结合模拟场景练习工具应用(掌握基础扫描逻辑,为 SRC 漏扫工具进阶做准备)。
1. 阶段目标
这阶段是真正开始“动手”了。信息收集、漏洞分析、工具联动,一样不能少。
熟练运用漏洞挖掘及 SRC 漏扫工具,具备独立挖掘常见漏洞及 SRC 平台漏扫实战能力,尝试通过 SRC 挖洞搞钱,不管是低危漏洞还是高危漏洞,先挖到一个。
2. 学习内容
信息收集实战:结合运维中对网络拓扑、设备信息的了解,强化基本信息收集、网络空间搜索引擎(Shodan、ZoomEye)、域名及端口信息收集技巧,针对企业级网络场景开展信息收集练习(为 SRC 漏扫目标筛选提供支撑)。
漏洞原理与分析:深入学习 SQL 注入、CSRF、文件上传等常见漏洞的原理、危害及利用方法,结合运维工作中遇到的类似问题进行关联分析(明确 SRC 漏扫重点漏洞类型)。
工具进阶与 SRC 漏扫应用:
-
系统学习 SQLMap、BurpSuite、AWVS 等工具的高级功能,开展工具联用实战训练;
-
专项学习 SRC 漏扫流程:包括 SRC 平台规则解读(如漏洞提交规范、奖励机制)、漏扫目标范围界定、漏扫策略制定(全量扫描 vs 定向扫描)、漏扫结果验证与复现;
-
实战训练:使用 AWVS+BurpSuite 组合开展 SRC 平台目标漏扫,练习 “扫描 - 验证 - 漏洞报告撰写 - 平台提交” 全流程。
SRC 实战演练:选择合适的 SRC 平台(如补天、CNVD)进行漏洞挖掘与漏扫实战,积累实战经验,尝试获取挖洞收益。
恭喜你,如果学到这里,你基本可以下班搞搞副业创收了,并且具备渗透测试工程师必备的「渗透技巧」、「溯源能力」,让你在黑客盛行的年代别背锅,工作实现升职加薪的同时也能开创副业创收!
如果你想要入坑黑客&网络安全,笔者给大家准备了一份:全网最全的网络安全资料包需要保存下方图片,微信扫码即可前往获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
1. 阶段目标
全面掌握渗透测试理论与实战技能,能够独立完成渗透测试项目,编写规范的渗透测试报告,具备渗透测试工程师岗位能力,为护网红蓝对抗及应急响应提供技术支撑。
2. 学习内容
渗透测试核心理论:系统学习渗透测试流程、方法论及法律法规知识,明确渗透测试边界与规范(与红蓝对抗攻击边界要求一致)。
实战技能训练:开展漏洞扫描、漏洞利用、电商系统渗透测试、内网渗透、权限提升(Windows、Linux)、代码审计等实战训练,结合运维中熟悉的系统环境设计测试场景(强化红蓝对抗攻击端技术能力)。
工具开发实践:基于 Python 编程基础,学习渗透测试工具开发技巧,开发简单的自动化测试脚本(可拓展用于 SRC 漏扫自动化及应急响应辅助工具)。
报告编写指导:学习渗透测试报告的结构与编写规范,完成多个不同场景的渗透测试报告撰写练习(与 SRC 漏洞报告、应急响应报告撰写逻辑互通)。
1. 阶段目标
掌握企业级安全攻防、护网红蓝对抗及应急响应核心技能,考取网安行业相关证书。
2. 学习内容
护网红蓝对抗专项:
-
红蓝对抗基础:学习护网行动背景、红蓝对抗规则(攻击范围、禁止行为)、红蓝双方角色职责(红队:模拟攻击;蓝队:防御检测与应急处置);
-
红队实战技能:强化内网渗透、横向移动、权限维持、免杀攻击等高级技巧,模拟护网中常见攻击场景;
-
蓝队实战技能:学习安全设备(防火墙、IDS/IPS、WAF)联动防御配置、安全监控平台(SOC)使用、攻击行为研判与溯源方法;
-
模拟护网演练:参与团队式红蓝对抗演练,完整体验 “攻击 - 检测 - 防御 - 处置” 全流程。
应急响应专项: -
应急响应流程:学习应急响应 6 步流程(准备 - 检测 - 遏制 - 根除 - 恢复 - 总结),掌握各环节核心任务;
-
实战技能:开展操作系统入侵响应(如病毒木马清除、异常进程终止)、数据泄露应急处置、漏洞应急修补等实战训练;
-
工具应用:学习应急响应工具(如 Autoruns、Process Monitor、病毒分析工具)的使用,提升处置效率;
-
案例复盘:分析真实网络安全事件应急响应案例(如勒索病毒事件),总结处置经验。
其他企业级攻防技能:学习社工与钓鱼、CTF 夺旗赛解析等内容,结合运维中企业安全防护需求深化理解。
证书备考:针对网安行业相关证书考试内容(含红蓝对抗、应急响应考点)进行专项复习,参加模拟考试,查漏补缺。
网络安全这行,不是会几个工具就能搞定的。你得有体系,懂原理,能实战。尤其是从运维转过来的,别浪费你原来的经验——你比纯新人强多了。
但也要沉得住气,别学了两天Web安全就觉得自己是黑客了。内网、域渗透、代码审计、应急响应,要学的还多着呢。
如果你真的想转,按这个路子一步步走,没问题。如果你只是好奇,我劝你再想想——这行要持续学习,挺累的,但也是真有意思。
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
1、网络安全意识
2、Linux操作系统
3、WEB架构基础与HTTP协议
4、Web渗透测试
5、渗透测试案例分享
6、渗透测试实战技巧

7、攻防对战实战
8、CTF之MISC实战讲解
关于如何学习网络安全,笔者也给大家整理好了全套网络安全知识库,需要的可以扫码获取!
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取

















 2057
2057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









