







 本文介绍了ConcurrentHashMap的数据结构,它类似HashMap,内部维护Segment数组,Segment继承自ReentrantLock,还维护HashEntry数组和链表。在put数据时,先计算hash值获取对应segment,尝试获取锁,若失败则扫描重试,获锁后设置值,最后释放锁,采用非全局的分段锁机制。
本文介绍了ConcurrentHashMap的数据结构,它类似HashMap,内部维护Segment数组,Segment继承自ReentrantLock,还维护HashEntry数组和链表。在put数据时,先计算hash值获取对应segment,尝试获取锁,若失败则扫描重试,获锁后设置值,最后释放锁,采用非全局的分段锁机制。
1.数据结构(数组+链表)
同hashmap类似,首先内部维护了一个Segment<K,V>数组。
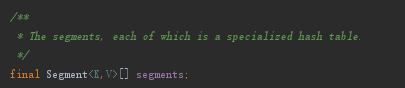
这个Segment比较有特色,它继承自ReentrantLock
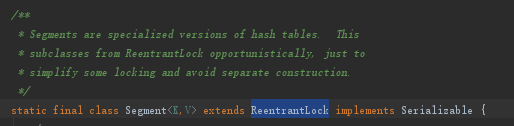
同时在Segment中也维护着一个HashEntry<K,V> table,这个跟HashMap中维护Entry<K,V>[]比较相像了。

再看下HashEntry的结构,发现它也是个链表结构,跟HashMap中的Entry<K,V>是不是几乎一模一样。

总结下:
ConcurrentHashMap的数据结构:segment[] -- HashEntry[] -- HashEntry链表;HashMap的数据结构:Entry<K,V> -- Entry链表。
2.put分析
put数据时,先计算hash值,再通过下图红框部分获得对应segment,执行s.put。
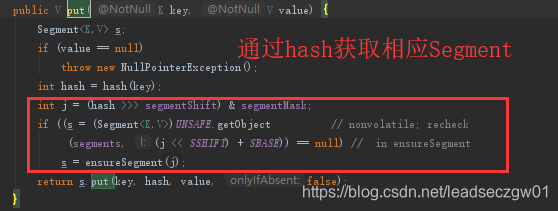
s.put时,会先尝试获取锁(因为Segment集成自ReentrantLock,所以可以直接用tryLock()方法),如果成功获得锁,则HashEntry<K,V>为null,否则持续扫描(超过最大默认最大次数64停止)获得锁。
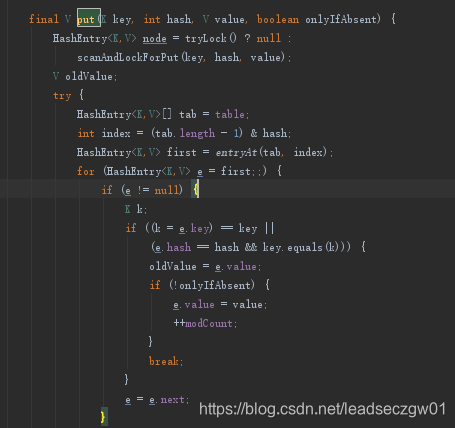
cpu处理器核数大于1则最大扫描重试次数为64,否则为1。

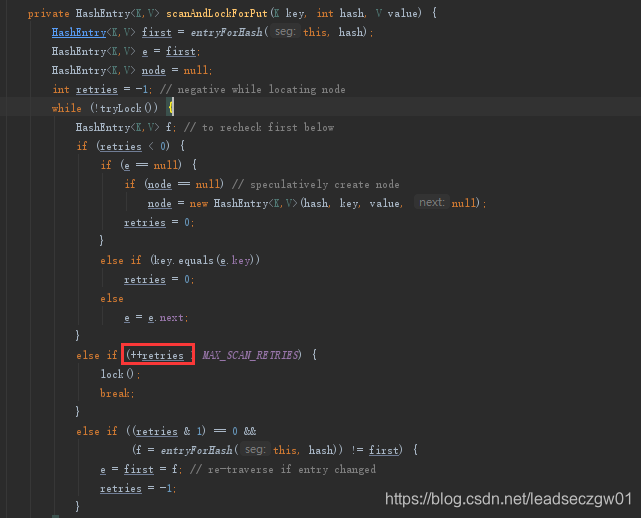
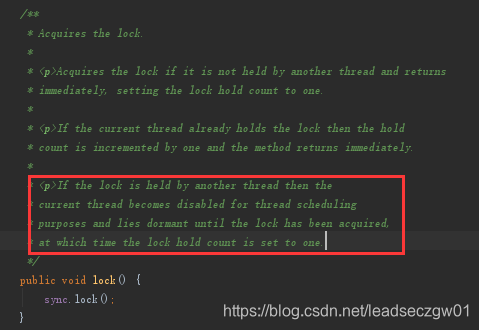
下面看看为put获取锁操作,注意下图红色部分,每次在做if判断前都先进行了自增,当重试次数超过最大次数后,会将当前线程变成不可用状态,直到获取到锁(相当于阻塞)。
获得锁之后开始进行put设置值,这部分跟HashMap类似。

到最后返回值,并释放锁。
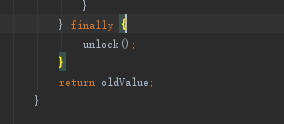
concurrent这种非全局锁(又称分段锁)是不是挺有意思的。


















 1306
1306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











