



 本文介绍了如何实现一个拼图游戏,并探讨了多种AI算法,包括广度优先搜索、双向广度优先搜索和A*搜索。游戏允许用户自定义图片、设置难度,并具有自动复原功能。文章详细讨论了各种搜索算法的实现细节,如状态树、搜索策略以及启发式函数,并对比了不同算法在不同难度下的性能表现。
本文介绍了如何实现一个拼图游戏,并探讨了多种AI算法,包括广度优先搜索、双向广度优先搜索和A*搜索。游戏允许用户自定义图片、设置难度,并具有自动复原功能。文章详细讨论了各种搜索算法的实现细节,如状态树、搜索策略以及启发式函数,并对比了不同算法在不同难度下的性能表现。

写了个拼图游戏,探讨一下相关的AI算法。拼图游戏的复原问题也叫做N数码问题。
-
拼图游戏
-
N数码问题
-
广度优先搜索
-
双向广度优先搜索
-
A*搜索

实现一个拼图游戏,使它具备以下功能:
1、自由选取喜欢的图片来游戏
2、自由选定空格位置
3、空格邻近的方块可移动,其它方块不允许移动
4、能识别图片是否复原完成,游戏胜利时给出反馈
5、一键洗牌,打乱图片方块
6、支持重新开始游戏
7、难度分级:高、中、低
8、具备人工智能,自动完成拼图复原
9、实现几种人工智能算法:广度优先搜索、双向广度优先搜索、A*搜索
10、保存游戏进度
11、读取游戏进度

Puzzle Game.png

先看看完成后的效果。点自动按钮后,游戏将会把当前的拼图一步一步移动直到复原图片。

自动复原.gif
图片的选取可通过拍照、从相册选,或者使用内置默认图片。
由于游戏是在正方形区域内进行的,所以若想有最好的游戏效果,我们需要一张裁剪成正方形的图片。

截取正方形区域.png
选好图片后,需要把图片切割成n x n块。这里每一个方块PuzzlePiece都是一个UIButton。
由于图片是会被打散打乱的,所以每个方块应该记住它自己在原图上的初始位置,这里给方块添加一个属性ID,用于保存。
@interface PuzzlePiece : UIButton /// 本方块在原图上的位置,从0开始编号
@property (nonatomic, assign) NSInteger ID; /// 创建实例+ (instancetype)pieceWithID:(NSInteger)ID image:(UIImage *)image; @end
切割后的图片块组成了一个n x n矩阵,亦即n阶方阵。而想要改变游戏难度,我们只需要改变方阵的阶数即可。
设计三档难度,从低到高分别对应3 x 3、4 x 4、5 x 5的方阵。

难度选择.gif
假如我们把游戏中某个时刻的方块排列顺序称为一个状态,那么当阶数为n时,游戏的总状态数就是n²的阶乘。
在不同难度下进行游戏将会有非常大的差异,无论是手动游戏还是AI进行游戏。
在低难度下,拼图共有(3*3)! = 362880个状态,并不多,即便是最慢的广搜算法也可以在短时间内搜出复原路径。

3阶方阵的搜索空间.png
在中难度下,拼图变成了4阶方阵,拼图状态数飙升到(4*4)! = 20922789888000,二十万亿。广搜算法已基本不能搜出结果,直到爆内存。

广搜算法占用的巨量内存.gif
在高难度下,拼图变成了5阶方阵,状态数是个天文数字(5*5)! = 1.551121004333098e25,10的25次方。此时无论是广搜亦或是双向广搜都已无能为力,而A*尚可一战。

高难度下的5阶方阵.png
在选取完图片后,拼图是完整无缺的,此时让第一个被触击的方块成为空格。
从第二次触击开始,将会对所触击的方块进行移动,但只允许空格附近的方块发生移动。
每一次移动方块,实质上是让方块的位置与空格的位置进行交换。在这里思维需要转个小弯,空格并不空,它也是一个对象,只不过表示出来是一块空白而已。那么我们移动了方块,是否可以反过来想,其实是移动了空格?答案是肯定的,并且思维这样转过来后,更方便代码实现。

方块移动.gif
这里为了让打乱顺序后的拼图有解,采用随机移动一定步数的方法来实现洗牌。
对于n阶方阵,可设计随机的步数为:n * n * 10。在实际测试当中,这个随机移动的步数已足够让拼图完全乱序,即使让随机的步数再加大10倍,其复原所需的移动步数也变化不大。复原步数与方阵的阶数有关,无论打乱多少次,复原步数都是趋于一个稳定的范围。

打乱方块顺序.gif

随机移动一定步数.png
我们需要定义一个类来表示拼图在某个时刻的状态。
一个状态应持有以下几个属性:
-
矩阵阶数
-
方块数组,以数组的顺序来表示本状态下方块的排列顺序
-
空格所在的位置,其值指向方块数组中显示成空白的那一个方块
同时它应能提供操作方块的方法,以演进游戏状态。
-
判断空格是否能移动到某个位置
-
把空格移动到某个位置
-
移除所有方块
-
打乱所有方块,变成一个随机状态
-
与另一个状态对象进行比较,判断是否状态等同
/// 表示游戏过程中,某一个时刻,所有方块的排列状态 @interface PuzzleStatus : NSObject <JXPathSearcherStatus, JXAStarSearcherStatus> /// 矩阵阶数 @property (nonatomic, assign) NSInteger matrixOrder; /// 方块数组,按从上到下,从左到右,顺序排列 @property (nonatomic, strong) NSMutableArray<PuzzlePiece *> *pieceArray; /// 空格位置,无空格时为-1 @property (nonatomic, assign) NSInteger emptyIndex; /// 创建实例,matrixOrder至少为3,image非空+ (instancetype)statusWithMatrixOrder:(NSInteger)matrixOrder image:(UIImage *)image; /// 复制本实例 - (instancetype)copyStatus ;/// 判断是否与另一个状态相同 - (BOOL)equalWithStatus:(PuzzleStatus *)status; /// 打乱,传入随机移动的步数 - (void)shuffleCount:(NSInteger)count; /// 移除所有方块 - (void)removeAllPieces; /// 空格是否能移动到某个位置 - (BOOL)canMoveToIndex:(NSInteger)index; /// 把空格移动到某个位置 - (void)moveToIndex:(NSInteger)index; @end
我们把拼图在某个时刻的方块排列称为一个状态,那么一旦发生方块移动,就会生成一个新的状态。
对于每个状态来说,它都能够通过改变空格的位置而衍生出另一个状态,而衍生出的状态又能够衍生出另一些状态。这种行为非常像一棵树的生成,当然这里的树指的是数据结构上的树结构。
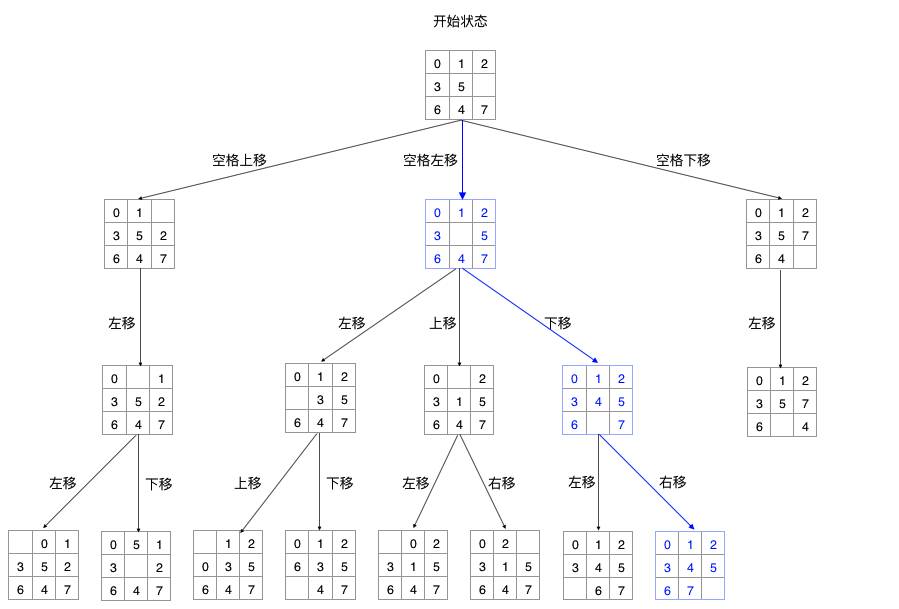
拼图状态树.png
推演移动路径的过程,就是根据当前状态不断衍生状态,然后判断新状态是否为我们的目标状态(拼图完全复原时的状态)。如果找到了目标,就可以原路返回,依次找出目标所经过的所有状态。
由此,状态树中的每一个结点都需要提供以下属性和方法:
-
父结点引用。要实现从目标状态逆向找回所有经过的状态,需要让每一个状态都持有它上一状态的引用,即持有它的父结点引用。
-
结点的唯一标识。用于算法过程中识别状态等同,以及哈希策略去重。
-
子结点的生成方法。用于衍生出新的结点,演进搜索。
/// 状态协议 @protocol JXPathSearcherStatus <NSObject> /// 父状态 @property (nonatomic, strong) id<JXPathSearcherStatus> parentStatus; /// 此状态的唯一标识 - (NSString *)statusIdentifier; /// 取所有邻近状态(子状态),排除父状态。每一个状态都需要给parentStatus赋值。 - (NSMutableArray<id<JXPathSearcherStatus>> *)childStatus;@end
对于一个路径搜索算法来说,它应该知道开始于哪里,和结束于哪里。
再有,作为一个通用的算法,不仅限于拼图游戏的话,它还需要算法使用者传入一个比较器,用于判断两个搜索状态是否等同,因为算法并不清楚它所搜索的是什么东西,也就不知道如何确定任意两个状态是否一样的。
给路径搜索算法作如下属性和方法定义:
/// 比较器定义 typedef BOOL(^JXPathSearcherEqualComparator)(id<JXPathSearcherStatus> status1, id<JXPathSearcherStatus> status2); /// 路径搜索 @interface JXPathSearcher : NSObject /// 开始状态 @property (nonatomic, strong) id<JXPathSearcherStatus> startStatus; /// 目标状态 @property (nonatomic, strong) id<JXPathSearcherStatus> targetStatus; /// 比较器 @property (nonatomic, strong) JXPathSearcherEqualComparator equalComparator; /// 开始搜索,返回搜索结果。无法搜索时返回 nil- (NSMutableArray *)search; /// 构建路径。isLast表示传入的status是否路径的最后一个元素 - (NSMutableArray *)constructPathWithStatus:(id<JXPathSearcherStatus>)status isLast(BOOL)isLast; @end
关于“搜索”两字,在代码上可以理解为拿着某个状态与目标状态进行比较,如果这两个状态一致,则搜索成功;如果不一致,则继续取另一个状态与目标状态比较,如此循环下去直到找出与目标一致的状态。
各算法的区别,主要在于它们对搜索空间内的状态结点有不同的搜索顺序。
广度优先搜索是一种盲目搜索算法,它认为所有状态(或者说结点)都是等价的,不存在优劣之分。
假如我们把所有需要搜索的状态组成一棵树来看,广搜就是一层搜完再搜下一层,直到找出目标结点,或搜完整棵树为止。
1、我们可以使用一个先进先出(First Input First Output, FIFO)的队列来存放待搜索的状态,这个队列可以给它一个名称叫开放队列,也有人把它叫做开放列表(Open List)。
2、然后还需要把所有已搜索过的状态记录下来,以确保不会对已搜索过的状态作重复扩展,注意这里的扩展即为衍生出子状态,对应于拼图游戏来说就是空格移动了一格。
由于每搜到一个状态,都需要拿着这个状态去已搜记录中查询是否有这个状态存在,那么已搜记录要使用怎样的存储方式才能适应这种高频率查找需求呢?
假如我们使用数组来存储所有已搜记录,那么每一次查找都需要遍历整个数组。当已搜记录表的数据有10万条时,再去搜一个新状态,就需要做10万次循环来确定新状态是从来没有被搜索过的。显然这样做的效率是非常低的。
一种高效的方法是哈希策略,哈希表(Hash Table)能通过键值映射直接查找到目标对象,免去遍历整个存储空间。在Cocoa框架中,已经有能满足这种键值映射的数据结构--字典。这里我没有再去实现一个哈希表,而是使用NSMutableDictionary来存放已搜记录。我们可以给这个存储空间起个名字叫关闭堆,也有人把它叫做关闭列表(Close List)。
1、搜索开始时,开放队列是空的,然后我们把起始状态入队,此时开放队列有了一个待搜索的状态,搜索循环开始。
2、每一次循环的目的,就是搜索一个状态。所谓搜索,前面已经讲过,可以通俗理解为就是比较。我们需要从开放队列中取出一个状态来,假如取出的状态是已经比较过了的,则放弃此次循环,直到取出一个从来没有比较过的状态。
3、拿着取出的新状态,与目标状态比较,如果一致,则说明路径已找到。为何说路径已找到了呢?因为每一个状态都持有一个父状态的引用,意思是它记录着自己是来源于哪一个状态衍生出来的,所以每一个状态都必然知道自己上一个状态是谁,除了开始状态。
4、找到目标状态后,就可以构建路径。所谓路径,就是从开始状态到目标状态的搜索过程中,经过的所有状态连起来组成的数组。我们可以从搜索结束的状态开始,把它放入数组中,然后把这个状态的父状态放入数组中,再把其祖先状态放入数组中,直到放入开始状态。如何识别出开始状态呢?当发现某个状态是没有父状态的,就说明了它是开始状态。最后算法把构建完成的路径作为结果返回。
5、在第5步中,如果发现取出的新状态并非目标状态,这时就需要衍生新的状态来推进搜索。调用生成子状态的方法,把产生的子状态入队,依次追加到队列尾,这些入队的子状态将会在以后的循环中被搜索。由于队列的FIFO特性,在循环进行过程中,将会优先把某个状态的子状态全部出列完后,再出列其子状态的子状态。入列和出列的两步操作决定了算法的搜索顺序,这里的操作实现了广度优先搜索。
广度优先搜索:
- (NSMutableArray *)search {
if (!self.startStatus || !self.targetStatus || !self.equalComparator) {
return nil;
}
NSMutableArray *path = [NSMutableArray array];
// 关闭堆,存放已搜索过的状态
NSMutableDictionary *close = [NSMutableDictionary dictionary];
// 开放队列,存放由已搜索过的状态所扩展出来的未搜索状态
NSMutableArray *open = [NSMutableArray array];
[open addObject:self.startStatus];
while (open.count > 0) {
// 出列
id status = [open firstObject];
[open removeObjectAtIndex:0];
// 排除已经搜索过的状态
NSString *statusIdentifier = [status statusIdentifier];
if (close[statusIdentifier]) {
continue;
}
close[statusIdentifier] = status;
// 如果找到目标状态
if (self.equalComparator(self.targetStatus, status)) {
path = [self constructPathWithStatus:status isLast:YES];
break;
}
// 否则,扩展出子状态
[open addObjectsFromArray:[status childStatus]];
}
NSLog(@"总共搜索了: %@个状态", @(close.count));
return path; }
构建路径:
/// 构建路径。isLast表示传入的status是否路径的最后一个元素
- (NSMutableArray *)constructPathWithStatus:(id<JXPathSearcherStatus>)status isLast:(BOOL)isLast {
NSMutableArray *path = [NSMutableArray array];
if (!status) {
return path;
}
do {
if (isLast) {
[path insertObject:status atIndex:0];
}
else {
[path addObject:status];
}
status = [status parentStatus];
} while (status);
returnpath; }

3阶方阵,广搜平均需要搜索10万个状态
双向广度优先搜索是对广度优先搜索的优化,但是有一个使用条件:搜索路径可逆。
双向广搜是同时从开始状态和目标状态展开搜索的,这样就会产生两棵搜索状态树。我们想象一下,让起始于开始状态的树从上往下生长,再让起始于目标状态的树从下往上生长,同时在它们的生长空间中遍布着一个一个的状态结点,等待着这两棵树延伸去触及。
由于任一个状态都是唯一存在的,当两棵搜索树都触及到了某个状态时,这两棵树就出现了交叉,搜索即告结束。
让两棵树从发生交叉的状态结点各自原路返回构建路径,然后算法把两条路径拼接起来,即为结果路径。
对于拼图游戏来说,已经知道了开始状态(某个乱序的状态)和目标状态(图片复原时的状态),而这两个状态其实是可以互换的,完全可以从目标复原状态开始搜索,反向推进,直到找出拼图开始时的乱序状态。所以,我们的拼图游戏是路径可逆的,适合双向广搜。
要实现双向广搜,并不需要真的用两条线程分别从开始状态和目标状态对向展开搜索,在单线程下也完全可以实现,实现的关键是于让两个开放队列交替出列元素。
在每一次循环中,比较两个开放队列的长度,每一次都选择最短的队列进行搜索,优先让较小的树生长出子结点。这样做能够使两个开放队列维持大致相同的长度,同步增长,达到均衡两棵搜索树的效果。
- (NSMutableArray *)search {
if (!self.startStatus || !self.targetStatus || !self.equalComparator) {
return nil;
}
NSMutableArray *path = [NSMutableArray array];
// 关闭堆,存放已搜索过的状态
NSMutableDictionary *positiveClose = [NSMutableDictionary dictionary];
NSMutableDictionary *negativeClose = [NSMutableDictionary dictionary];
// 开放队列,存放由已搜索过的状态所扩展出来的未搜索状态
NSMutableArray *positiveOpen = [NSMutableArray array];
NSMutableArray *negativeOpen = [NSMutableArray array];
[positiveOpen addObject:self.startStatus];
[negativeOpen addObject:self.targetStatus];
while (positiveOpen.count > 0 || negativeOpen.count > 0) {
// 较短的那个扩展队列
NSMutableArray *open;
// 短队列对应的关闭堆
NSMutableDictionary *close;
// 另一个关闭堆
NSMutableDictionary *otherClose;
// 找出短队列
if (positiveOpen.count && (positiveOpen.count < negativeOpen.count)) {
open = positiveOpen;
close = positiveClose;
otherClose = negativeClose;
}
else {
open = negativeOpen;
close = negativeClose;
otherClose = positiveClose;
}
// 出列
id status = [open firstObject];
[open removeObjectAtIndex:0];
// 排除已经搜索过的状态
NSString *statusIdentifier = [status statusIdentifier];
if (close[statusIdentifier]) {
continue;
}
close[statusIdentifier] = status;
// 如果本状态同时存在于另一个已检查堆,则说明正反两棵搜索树出现交叉,搜索结束
if (otherClose[statusIdentifier]) {
NSMutableArray *positivePath = [self constructPathWithStatus:positiveClose[statusIdentifier] isLast:YES];
NSMutableArray *negativePath = [self constructPathWithStatus:negativeClose[statusIdentifier] isLast:NO];
// 拼接正反两条路径
[positivePath addObjectsFromArray:negativePath];
path = positivePath;
break;
}
// 否则,扩展出子状态
[open addObjectsFromArray:[status childStatus]];
}
NSLog(@"总搜索数量: %@", @(positiveClose.count + negativeClose.count - 1));
return path; }

3阶方阵,双向广搜平均需要搜索3500个状态
不同于盲目搜索,A*算法是一种启发式算法(Heuristic Algorithm)。
上文提到,盲目搜索对于所有要搜索的状态结点都是一视同仁的,因此在每次搜索一个状态时,盲目搜索并不会考虑这个状态到底是有利于趋向目标的,还是偏离目标的。
而启发式搜索的启发二字,看起来是不是感觉这个算法就变得聪明一点了呢?正是这样,启发式搜索对于待搜索的状态会进行不同的优劣判断,这个判断的结果将会对算法搜索顺序起到一种启发作用,越优秀的状态将会得到越高的搜索优先级。
我们把对于状态优劣判断的方法称为启发函数,通过给它评定一个搜索代价来量化启发值。
启发函数应针对不同的使用场景来设计,那么在拼图的游戏中,如何评定某个状态的优劣性呢?粗略的评估方法有两种:
1、可以想到,某个状态它的方块位置放对的越多,说明它能复原目标的希望就越大,这个状态就越优秀,优先选择它就能减少无效的搜索,经过它而推演到目标的代价就会小。所以可求出某个状态所有方块的错位数量来作为评估值,错位越少,状态越优秀。
2、假如让拼图上的每个方块都可以穿过邻近方块,无阻碍地移动到目标位置,那么每个不在正确位置上的方块它距离正确位置都会存在一个移动距离,这个非直线的距离即为曼哈顿距离(Manhattan Distance),我们把每个方块距离其正确位置的曼哈顿距离相加起来,所求的和可以作为搜索代价的值,值越小则可认为状态越优秀。
其实上述两种评定方法都只是对当前状态距离目标状态的代价评估,我们还忽略了一点,就是这个状态距离搜索开始的状态是否已经非常远了,亦即状态结点的深度值。
在拼图游戏中,我们进行的是路径搜索,假如搜索出来的一条移动路径其需要的步数非常多,即使最终能够把拼图复原,那也不是我们希望的路径。所以,路径搜索存在一个最优解的问题,搜索出来的路径所需要移动的步数越少,就越优。
A*算法对某个状态结点的评估,应综合考虑这个结点距离开始结点的代价与距离目标结点的代价。总估价公式可以表示为:
f(n) = g(n) + h(n)
n表示某个结点,f(n)表示对某个结点进行评价,值等于这个结点距离开始结点的已知价g(n)加上距离目标结点的估算价h(n)。
为什么说g(n)的值是确定已知的呢?在每次生成子状态结点时,子状态的g值应在它父状态的基础上+1,以此表示距离开始状态增加了一步,即深度加深了。所以每一个状态的g值并不需要估算,是实实在在确定的值。
影响算法效率的关键点在于h(n)的计算,采用不同的方法来计算h值将会让算法产生巨大的差异。
-
当增大h值的权重,即让h值远超g值时,算法偏向于快速寻找到目标状态,而忽略路径长度,这样搜索出来的结果就很难保证是最优解了,意味着可能会多绕一些弯路,通往目标状态的步数会比较多。
-
当减小h值的权重,降低启发信息量,算法将偏向于注重已搜深度,当h(n)恒为0时,A*算法其实已退化为广度优先搜索了。(这是为照应上文的方便说法。严谨的说法应是退化为Dijkstra算法,在本游戏中,广搜可等同为Dijkstra算法,关于Dijkstra这里不作深入展开。)
以下是拼图状态结点PuzzleStatus的估价方法,在实际测试中,使用方块错位数量来作估价的效果不太明显,所以这里只使用曼哈顿距离来作为h(n)估价,已能达到不错的算法效率。
/// 估算从当前状态到目标状态的代价
- (NSInteger)estimateToTargetStatus:(id<JXPathSearcherStatus>)targetStatus {
PuzzleStatus *target = (PuzzleStatus *)targetStatus;
// 计算每一个方块距离它正确位置的距离
// 曼哈顿距离
NSInteger manhattanDistance = 0;
for (NSInteger index = 0; index < self.pieceArray.count; ++ index) {
// 略过空格
if (index == self.emptyIndex) {
continue;
}
PuzzlePiece *currentPiece = self.pieceArray[index];
PuzzlePiece *targetPiece = target.pieceArray[index];
manhattanDistance +=
ABS([self rowOfIndex:currentPiece.ID] - [target rowOfIndex:targetPiece.ID]) +
ABS([self colOfIndex:currentPiece.ID] - [target colOfIndex:targetPiece.ID]);
}
// 增大权重
return 5 * manhattanDistance;
}
状态估价由状态类自己负责,A*算法只询问状态的估价结果,并进行f(n) = g(n) + h(b)操作,确保每一次搜索,都是待搜空间里代价最小的状态,即f值最小的状态。
那么问题来了,在给每个状态都计算并赋予上f值后,如何做到每一次只取f值最小的那个?
前文已讲到,所有扩展出来的新状态都会放入开放队列中的,如果A*算法也像广搜那样只放在队列尾,然后每次只取队首元素来搜索的话,那么f值完全没有起到作用。
事实上,因为每个状态都有f值的存在,它们已经有了优劣高下之分,队列在存取它们的时候,应当按其f值而有选择地进行入列出列,这时候需要用到优先队列(Priority Queue),它能够每次出列优先级最高的元素。
关于优先队列的讲解和实现,可参考另一篇文章《借助完全二叉树,实现优先队列与堆排序》(http://www.jianshu.com/p/9a456d1b59b5),这里不再展开论述。
以下是A*搜索算法的代码实现:
- (NSMutableArray *)search {
if (!self.startStatus || !self.targetStatus || !self.equalComparator) {
return nil;
}
NSMutableArray *path = [NSMutableArray array];
[(id<JXAStarSearcherStatus>)[self startStatus] setGValue:0];
// 关闭堆,存放已搜索过的状态
NSMutableDictionary *close = [NSMutableDictionary dictionary];
// 开放队列,存放由已搜索过的状态所扩展出来的未搜索状态
// 使用优先队列
JXPriorityQueue *open = [JXPriorityQueue queueWithComparator:^NSComparisonResult(id<JXAStarSearcherStatus> obj1, id<JXAStarSearcherStatus> obj2) {
if ([obj1 fValue] == [obj2 fValue]) {
return NSOrderedSame;
}
// f值越小,优先级越高
return [obj1 fValue] < [obj2 fValue] ? NSOrderedDescending : NSOrderedAscending; }];
[open enQueue:self.startStatus];
while (open.count > 0) {
// 出列
id status = [open deQueue];
// 排除已经搜索过的状态
NSString *statusIdentifier = [status statusIdentifier];
if (close[statusIdentifier]) {
continue;
}
close[statusIdentifier] = status;
// 如果找到目标状态
if (self.equalComparator(self.targetStatus, status)) {
path = [self constructPathWithStatus:status isLast:YES];
break;
}
// 否则,扩展出子状态
NSMutableArray *childStatus = [status childStatus];
// 对各个子状进行代价估算
[childStatus enumerateObjectsUsingBlock:^(id<JXAStarSearcherStatus> _Nonnull obj, NSUInteger idx, BOOL * _Nonnull stop) {
// 子状态的实际代价比本状态大1
[obj setGValue:[status gValue] + 1];
// 估算到目标状态的代价
[obj setHValue:[obj estimateToTargetStatus:self.targetStatus]];
// 总价=已知代价+未知估算代价
[obj setFValue:[obj gValue] + [obj hValue]];
// 入列
[open enQueue:obj];
}];
}
NSLog(@"总共搜索: %@", @(close.count));
return path; }
可以看到,代码基本是以广搜为模块,加入了f(n) = g(n) + h(b)的操作,并且使用了优先队列作为开放表,这样改进后,算法的效率是不可同日而语。

3阶方阵,A*算法平均需要搜索300个状态
最后,贴上高难度下依然战斗力爆表的A*算法效果图:


5阶方阵下的A*搜索算法
源码
Puzzle Game:https://github.com/JiongXing/PuzzleGame
原文链接:http://www.jianshu.com/p/10a6d02616ad


往期精彩回顾

TensorFlow从1到2 | 第三章 深度学习革命的开端:卷积神经网络

点击“阅读原文”直接打开【北京站 | GPU CUDA 进阶课程】报名链接

















 422
422





 到【灌水乐园】发言
到【灌水乐园】发言







