



 本文介绍了在样本不平衡情况下,如何使用Python实现SMOTE(Synthetic minority over-sampling technique)算法进行过抽样。作者通过实例展示了从数据预处理、计算距离到生成新样本的完整过程,并探讨了SMOTE的改进方法,如结合Tomek link。文章还提供了相关资源链接和深度学习课程推荐。
本文介绍了在样本不平衡情况下,如何使用Python实现SMOTE(Synthetic minority over-sampling technique)算法进行过抽样。作者通过实例展示了从数据预处理、计算距离到生成新样本的完整过程,并探讨了SMOTE的改进方法,如结合Tomek link。文章还提供了相关资源链接和深度学习课程推荐。

点击“阅读原文”直接打开【北京站 | GPU CUDA 进阶课程】报名链接
沙韬伟,苏宁易购高级算法工程师。
曾任职于Hewlett-Packard、滴滴出行。
数据学院特邀讲师。
主要研究方向包括风控、推荐和半监督学习。目前专注于基于深度学习及集成模型下的用户行为模式的识别。
之前一直没有用过python,最近做了一些数量级比较大的项目,觉得有必要熟悉一下python,正好用到了smote,网上也没有搜到,所以就当做一个小练手来做一下。
首先,看下Smote算法之前,我们先看下当正负样本不均衡的时候,我们通常用的方法:

常规的包含过抽样、欠抽样、组合抽样
过抽样:将样本较少的一类sample补齐。
欠抽样:将样本较多的一类sample压缩。
组合抽样:约定一个量级N,同时进行过抽样和欠抽样,使得正负样本量和等于约定量级N。
这种方法要么丢失数据信息,要么会导致较少样本共线性,存在明显缺陷。
常规的包括算法中的weight,weight matrix。
改变入参的权重比,比如boosting中的全量迭代方式、逻辑回归中的前置的权重设置。
这种方式的弊端在于无法控制合适的权重比,需要多次尝试。
通过核函数的改变,来抵消样本不平衡带来的问题。
这种使用场景局限,前置的知识学习代价高,核函数调整代价高,黑盒优化。
通过现有的较少的样本类别的数据,用算法去探查数据之间的特征,判读数据是否满足一定的规律。
比如,通过线性拟合,发现少类样本成线性关系,可以新增线性拟合模型下的新点。
实际规律比较难发现,难度较高。
SMOTE(Synthetic minoritye over-sampling technique,SMOTE)是Chawla在2002年提出的过抽样的算法,一定程度上可以避免以上的问题。
下面介绍一下这个算法:
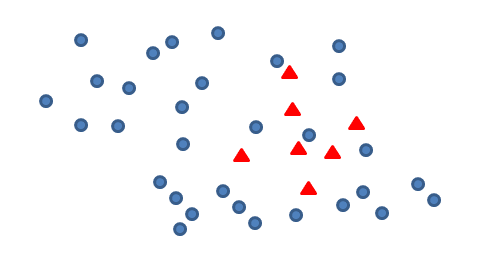
正负样本分布
很明显的可以看出,蓝色样本数量远远大于红色样本,在常规调用分类模型去判断的时候可能会导致之间忽视掉红色样本带了的影响,只强调蓝色样本的分类准确性,这边需要增加红色样本来平衡数据集。
Smote算法的思想其实很简单,先随机选定n个少类的样本,如下图:
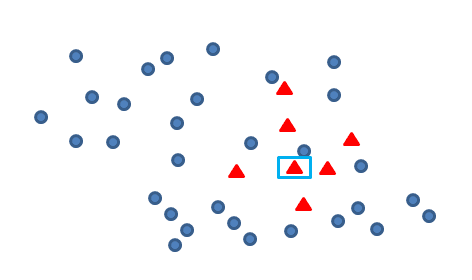
找出初始扩展的少类样本
再找出最靠近它的m个少类样本,如下图:
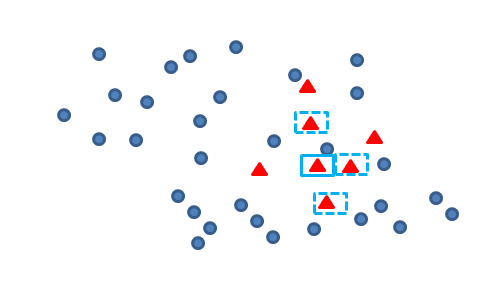
再任选最临近的m个少类样本中的任意一点,
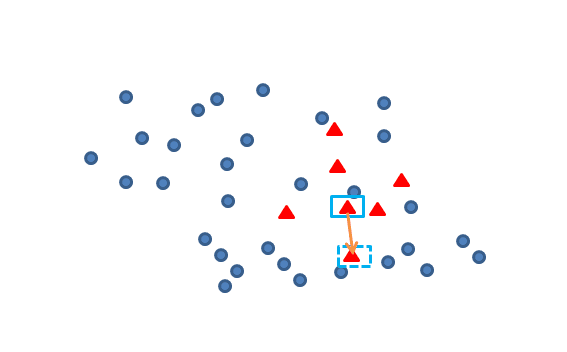
在这两点上任选一点,这点就是新增的数据样本。
R语言上的开发较为简单,有现成的包库,这边简单介绍一下:
rm(list=ls())
install.packages(“DMwR”,dependencies=T)
library(DMwR)#加载smote包
newdata=SMOTE(formula,data,perc.over=,perc.under=)
#formula:申明自变量因变量
#perc.over:过采样次数
#perc.under:欠采样次数
效果对比:
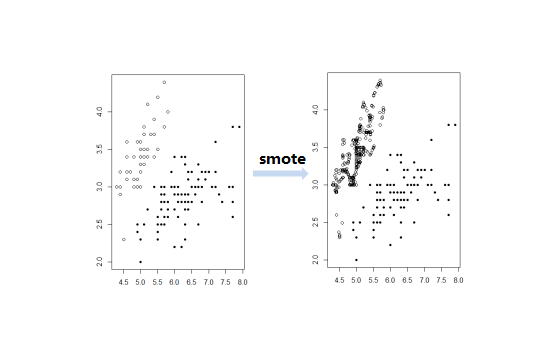
简单的看起来就好像是重复描绘了较少的类。
这边的smote是封装好的,直接调用就行了,没有什么特别之处。
这边自己想拿刚学的python练练手,所有就拿python写了一下过程:
# -*- coding: utf-8 -*-
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from numpy import *
import matplotlib.pyplot as plt
#读数据
data = pd.read_table('C:/Users/17031877/Desktop/supermarket_second_man_clothes_train.txt', low_memory=False)
#简单的预处理
test_date = pd.concat([data['label'], data.iloc[:, 7:10]], axis=1)
test_date = test_date.dropna(how='any')
数据大致如下:
test_date.head() Out[25]: label max_date_diff max_pay cnt_time 0 0 23.0 43068.0 15 1 0 10.0 1899.0 2 2 0 146.0 3299.0 21 3 0 30.0 31959.0 35 4 0 3.0 24165.0 98 test_date['label'][test_date['label']==0].count()/test_date['label'][test_date['label']==1].count() Out[37]: 67
label是样本类别判别标签,1:0=67:1,需要对label=1的数据进行扩充。
# 筛选目标变量 aimed_date = test_date[test_date['label'] == 1] # 随机筛选少类扩充中心 index = pd.DataFrame(aimed_date.index).sample(frac=0.1, random_state=1) index.columns = ['id'] number = len(index) # 生成array格式 aimed_date_new = aimed_date.ix[index.values.ravel(), :]
随机选取了全量少数样本的10%作为数据扩充的中心点。
# 自变量标准化 sc = StandardScaler().fit(aimed_date_new) aimed_date_new = pd.DataFrame(sc.transform(aimed_date_new)) sc1 = StandardScaler().fit(aimed_date) aimed_date = pd.DataFrame(sc1.transform(aimed_date)) # 定义欧式距离计算 def dist(a, b): a = array(a) b = array(b) d = ((a[0] - b[0]) ** 2 + (a[1] - b[1]) ** 2 + (a[2] - b[2]) ** 2 + (a[3] - b[3]) ** 2) ** 0.5 return d
下面定义距离计算的方式,所有算法中,涉及到距离的地方都需要标准化去除冈量,也同时加快了计算的速度。
这边采取了欧式距离的方式,更多计算距离的方式参考:
多种距离及相似度的计算理论介绍(http://www.jianshu.com/p/1417fcb06797)
# 统计所有检验距离样本个数 row_l1 = aimed_date_new.iloc[:, 0].count() row_l2 = aimed_date.iloc[:, 0].count() a = zeros((row_l1, row_l2)) a = pd.DataFrame(a) # 计算距离矩阵 for i in range(row_l1): for j in range(row_l2): d = dist(aimed_date_new.iloc[i, :], aimed_date.iloc[j, :]) a.ix[i, j] = d b = a.T.apply(lambda x: x.min())
调用上面的计算距离的函数,形成一个距离矩阵,
# 找到同类点位置 h = [] z = [] for i in range(number): for j in range(len(a.iloc[i, :])): ai = a.iloc[i, j] bi = b[i] if ai == bi: h.append(i) z.append(j) else: continue new_point = [0, 0, 0, 0] new_point = pd.DataFrame(new_point) for i in range(len(h)): index_a = z[i] new = aimed_date.iloc[index_a, :] new_point = pd.concat([new, new_point], axis=1) new_point = new_point.iloc[:, range(len(new_point.columns) - 1)]
再找到位置的情况下,再去原始的数据集中根据位置查找具体的数据,
import random r1 = [] for i in range(len(new_point.columns)): r1.append(random.uniform(0, 1)) new_point_last = [] new_point_last = pd.DataFrame(new_point_last) # 求新点 new_x=old_x+rand()*(append_x-old_x) for i in range(len(new_point.columns)): new_x = (new_point.iloc[1:4, i] - aimed_date_new.iloc[number - 1 - i, 1:4]) * r1[i] + aimed_date_new.iloc[ number - 1 - i, 1:4] new_point_last = pd.concat([new_point_last, new_x], axis=1) print new_point_last
最后,再根据smote的计算公式new_x=old_x+rand()*(append_x-old_x),计算出新的点即可,python练手到此就结束了。
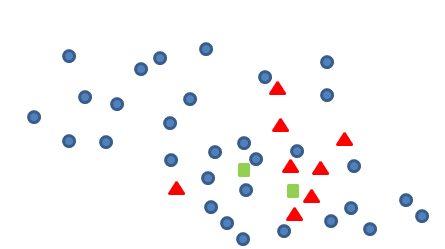
其实,在这个结果上,我们可以综合Tomek link做一个集成的数据扩充的算法,思路如下:
假设,我们利用上述的算法产生了两个青色方框的新数据点:
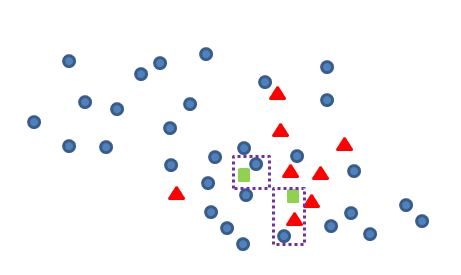
我们认为,对于新产生的青色数据点与其他非青色样本点距离最近的点,构成一对Tomek link,如下图框中的青蓝两点:
我们可以定义规则:
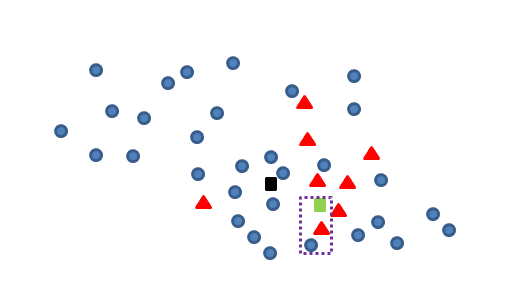
当以新产生点为中心,Tomek link的距离为范围半径,去框定一个空间,空间内的少数类的个数/多数类的个数<最低阀值的时候,认为新产生点为“垃圾点”,应该剔除或者再次进行smote训练;空间内的少数类的个数/多数类的个数>=最低阀值的时候,在进行保留并纳入smote训练的初始少类样本集合中去抽样。
所以,剔除左侧的青色新增点,只保留右边的新增数据如下:
1、https://www.jair.org/media/953/live-953-2037-jair.pdf;
2、https://github.com/fmfn/UnbalancedDataset;
3、Batista, G. E., Bazzan, A. L., & Monard, M. C. (2003, December). Balancing Training Data for Automated Annotation of Keywords: a Case Study. In WOB (pp. 10-18);
4、Batista, G. E., Prati, R. C., & Monard, M. C. (2004). A study of the behavior of several methods for balancing machine learning training data. ACM Sigkdd Explorations Newsletter, 6(1), 20-29。
原文链接:http://www.jianshu.com/p/ecbc924860af
 BY
简书
BY
简书
往期精彩回顾

深度学习视频(一) | 免费放送—深度学习的应用场景和数学基础

点击“阅读原文”直接打开【北京站 | GPU CUDA 进阶课程】报名链接


















 3399
3399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









