




 本文详细解析了HashMap的基本数据结构,包括其由数组和链表组成的独特结构,探讨了节点的插入方式,从Java7的头插法到Java8的尾插法的改进,以及扩容机制和初始化大小的选择。同时,文章还解释了为什么在重写equals方法时需要重写hashCode方法。
本文详细解析了HashMap的基本数据结构,包括其由数组和链表组成的独特结构,探讨了节点的插入方式,从Java7的头插法到Java8的尾插法的改进,以及扩容机制和初始化大小的选择。同时,文章还解释了为什么在重写equals方法时需要重写hashCode方法。
HashMap
基本数据结构
HashMap是由数组和链表组合构成的数据结构
数组里面的每个地方都存了Key-Value这样的实例,在Java7叫Entry而在Java8中叫Node
结构
数组

因为HashMap本身所有的位置都为null,在put插入Node的时候会根据key的hash去计算index值。index就是该Node所属于数组位置的下标
链表
数组的长度是有点,而在有限的长度里面我们使用Hash,Hash本身就存在概率性,就可能2个Node的Hash会有一致的概率,则2个相同hash的Node就形成了链表。每个node都会保存自身的hash,key,value以及下个节点。
节点插入方式
Java8之前是头插法,也就是说新来的值会取代原有的值,原有的值就顺推到链表中去,因为源码的作者认为后来的值被查找的可能性更大一点,从而提升查找的效率。
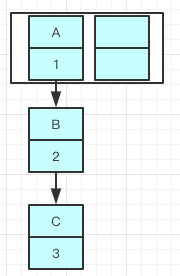
因为resize的赋值方式,也就是使用了单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置,在旧数组中同一条Entry链上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置上。
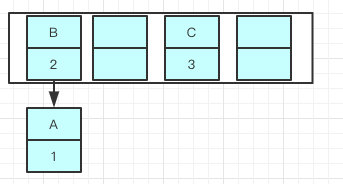
在多线程的情况下 多个线程都调整完成,就可能出现环形链表
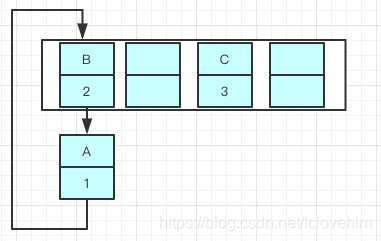
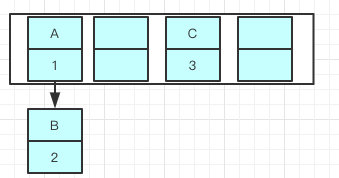
Java8之后都是采用尾部插入,尾插入的时候,在扩容链表元素原本的顺序,就不会出现链表成环的问题
也就是说原本是A->B,在扩容后那个链表还是A->B
-
Java7在多线程操作HashMap时可能引起死循环,原因是扩容转移后前后链表顺序倒置,在转移过程中修改了原来链表中节点的引用关系。
-
Java8在同样的前提下并不会引起死循环,原因是扩容转移后前后链表顺序不变,保持之前节点的引用关系。
扩容机制
数组的容量是有限的,数据多次插入,到达一定的数量就会进行扩容,也就是resize。
resize的时机
Capacity:HashMap当前的长度
LoadFactor:负载因子,默认值0.75
当前的最大容量MAXIMUM_CAPACITY位100,当你存进第76的时候,判断发现需要进行resize了,那就进行扩容,但是HashMap的扩容也不是简单的扩大点容量这么简单
扩容:创建一个新的Entry空数组,长度是原数组的2倍。
ReHash:遍历原Entry数组,把所有的Entry重新Hash到新数组。
长度扩大后,Hash的规则也随之改变
Hash的公式—> index = HashCode(Key) & (Length - 1)
原来长度(Length)是8你位运算出来的值是2 ,新的长度是16你位运算出来的值明显不一样了。
初始化大小
HashMap的默认初始化长度是16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
位与运算比算数计算的效率高了很多,之所以选择16,是为了服务将Key映射到index的算法。
通过Key的HashCode值去做位运算。
index的计算公式:index = HashCode(Key) & (Length- 1)
因为在使用是2的幂的数字的时候,Length-1的值是所有二进制位全为1,这种情况下,index的结果等同于HashCode后几位的值。
只要输入的HashCode本身分布均匀,Hash算法的结果就是均匀的。
这是为了实现均匀分布。
重写equals方法需要重写hashCode方法
因为在java中,所有的对象都是继承于Object类。Ojbect类中有两个方法equals、hashCode,这两个方法都是用来比较两个对象是否相等的。
在未重写equals方法我们是继承了object的equals方法,那里的 equals是比较两个对象的内存地址,显然我们new了2个对象内存地址肯定不一样
- 对于值对象,==比较的是两个对象的值
- 对于引用对象,比较的是两个对象的地址

















 342
342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









