




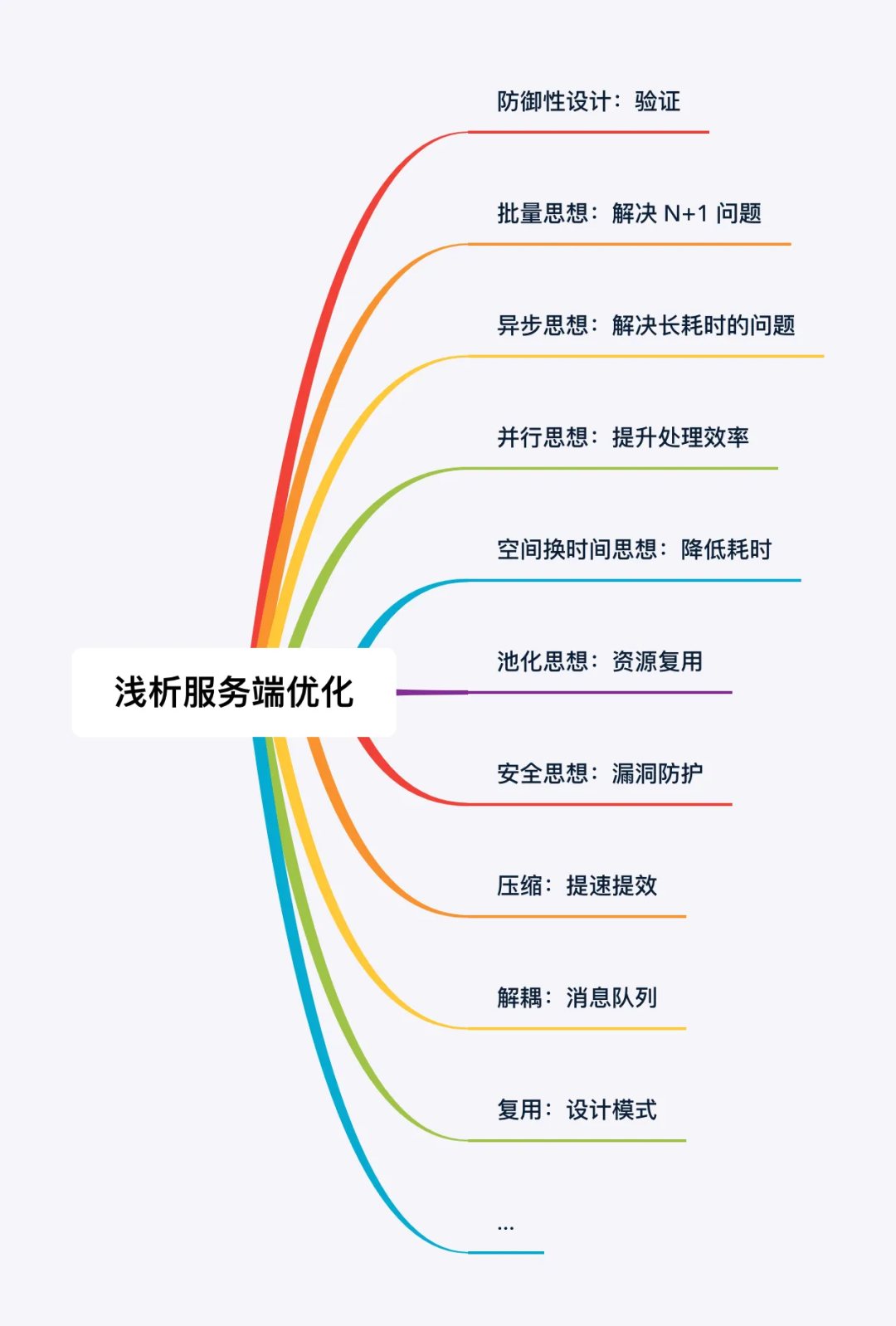
目录
1 写在前面
2 防御性设计:验证
3 批量思想:解决 N+1 问题
4 异步思想:解决长耗时问题
5 并行思想:提升处理效率
6 空间换时间思想:降低耗时
7 连接池:资源复用
8 安全思想:漏洞防护
9 压缩:提速提效
10 解耦:消息队列
11 复用:设计模式
写在前面
性能优化是软件项目开发过程中的一个永恒话题。
随着功能迭代,复杂度不断增加,同时伴随着流量、数据不断增长,接口性能可能会逐渐下降,尤其是在高并发场景,性能问题就更容易暴露出来。这时,我们也不能闲着。开始翻古书、找资料、访道友,不断提升,慢慢练成属于自己的七十二绝技。
本文主要总结了日常开发中一些通用的优化手段,以期对日后的开发有所裨益。
02
防御性设计:验证
2.1 业务场景
在日常开发中,尤其是在 web 应用开发中,我们经常需要对数据的合法性进行验证。为了实现这一目的,我们通常会对参数进行一些前置验证。这些验证规则可以包括必填项、范围、格式、正则表达式、安全性以及自定义规则等。
通常,为简化业务逻辑,我们会借助一些第三方工具来进行这些通用性的检测。
2.2 案例
⓵ Protocol Buffer Validation
如果是基于 pb 协议,可以启用 protoc-gen-validate (PGV) 自动化数据校验插件。配置规则如:

强校验 title 字段长度在 1 ~ 100 个字符:
string title = 1 [(validate.rules).string = {min_len: 1, max_len: 100 }];一般地,保存数据库之前,为防止溢出,可对其长度做前置检查。
《约束规则》支持的类型有 Numerics、Bools、Strings、Bytes、Enums、Messages、Repeated、Maps 等。
⓶ Go Struct and Field validation
对于非 pb 定义的结构,也有一些类似的组件实现自动化校验。如 Go Struct and Field validation ,基本用法如下:
// User contains user informationtype User struct {FirstName string `validate:"required"`LastName string `validate:"required"`Age uint8 `validate:"gte=0,lte=130"`Email string `validate:"required,email"`Gender string `validate:"oneof=male female prefer_not_to"`FavouriteColor string `validate:"iscolor"` // alias for 'hexcolor|rgb|rgba|hsl|hsla'Addresses []*Address `validate:"required,dive,required"` // a person can have a home and cottage...}
详细参考 《常用的验证》。如果预置的 valadator 不满足需求,也可以自定义 validator。
https://github.com/go-playground/validator?tab=readme-ov-file#baked-in-validations
2.3 小结
谚云:防御不到位,上线跑断腿
防御性设计是考虑使用者可能会错误使用的情况,从设计上避免错误使用,或是降低错误使用的机会。防御性设计可以让软件更安全、可靠,更方便地找到使用者的错误。
03
批量思想:解决 N+1 问题
3.1 业务场景
N+1 查询问题指的是当查询一个对象的列表数据的时候,会首先查询列表中的对象的 ID,然后循环生成单独的 SQL/RPC 去查询对象的详细数据。这会导致 SQL/RPC 查询过多问题。
在一个循环内多次执行 RPC 调用或者数据库操作。数据量小的时候问题不大,能跑起来。随着业务的发展,数据量越来越大,或者要查询的 id 越来越多(特别是未加限制的时候),耗时部题可想而知,长尾会越来越多。
3.2 案例
⓵ 循环中的 RPC
读取多条记录时在 for 循环中去分别读取单行。
for _, id := range ids {record := GetDetail(id)// do something ...}
解决方案:改批量(一次从存储中取出所有 id 的结果)
records := GetDetails(ids)// do something ...
3.3 小结
谚云:积羽沉舟,群轻折轴
上述场景是一个典型的 N+1 问题,不限于读取,写入亦然。它可能导致性能问题和增加数据库负载。
为了解决 N+1 问题,开发人员可以使用一些技术,如批量加载(batch loading)、批量更新(Bulk Updates),从而减少请求次数。通过优化数据库查询和加载策略,开发人员可以避免 N+1 问题,并提高应用程序的效率。
04
异步思想:解决长耗时问题
异步思想是一种解决长耗时问题的方法,它通过将耗时的操作放在后台进行,不阻塞主线程或其他任务的执行,从而提高系统的响应性能和并发处理能力。
4.1 业务场景
在处理一些复杂的业务场景时,对于部分操作考虑使用异步,可以大幅降低接口耗时。
比如,在做服务性能优化时,可以将如数据上报、流水日志等做异步处理,以降低接口时延。用户上传图片后的审核,音视频的合成等等。
4.2 案例
⓵ 子过程改异步、协程
以文本配音(TTS)为例,【合成音频】和【添加音效】这两个子过程耗耗时比较长:https://kf.zenvideo.qq.com/help/doc?id=dcccf9045b50dca3
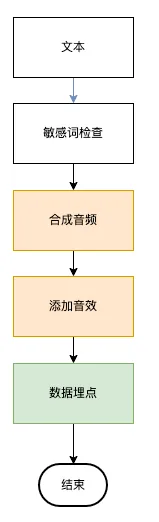
我们可以把耗时长的部分封装到一个异步任务中,并生成一个任务 ID,后续可以查询处理进度和结果。音频生成部分改为异步任务是因为该子过程是文本配音的关键路径(主流程、耗时长),对非关键路径如【数据埋点】直接改为协程处理即可:
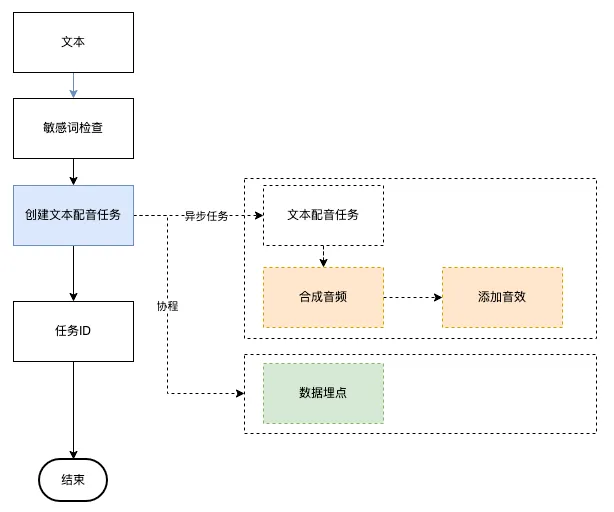
⓶ 异步在数据库、消息队列的应用
异步处理在数据库中同样应用广泛,例如 Redis 的 bgsave,bgrewriteof 就是分别用来异步保存 RDB 跟 AOF 文件的命令,bgsave 执行后会立刻返回成功,主线程 fork 出一个线程用来将内存中数据生成快照保存到磁盘,而主线程继续执行客户端命令;Redis 删除 key 的方式有 del 跟 unlink 两种,对于 del 命令是同步删除,直接释放内存,当遇到大 key 时,删除操作会让 Redis 出现卡顿的问题,而 unlink 是异步删除的方式,执行后对于 key 只做不可达的标识,对于内存的回收由异步线程回收,不阻塞主线程。
MySQL 的主从同步支持异步复制、同步复制跟半同步复制。异步复制是指主库执行完提交的事务后立刻将结果返回给客户端,并不关心从库是否已经同步了数据;同步复制是指主库执行完提交的事务,所有的从库都执行了该事务才将结果返回给客户端;半同步复制指主库执行完后,至少一个从库接收并执行了事务才返回给客户端。有多种主要是因为异步复制客户端写入性能高,但是存在丢数据的风险,在数据一致性要求不高的场景下可以采用,同步方式写入性能差,适合在数据一致性要求高的场景使用。
此外,对 Kafka 的生产者跟消费者都可以采用异步的方式进行发送跟消费消息,但是采
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 173万+
173万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









