






 这篇博客详细记录了在NowCoder上的SQL刷题经历,重点讲解了MySQL中的字符串处理、OVER函数、CASE关键字的用法,以及在不同场景下IN和EXISTS的比较。内容涵盖字符串计数、窗口函数的应用、分组排名和条件判断,并提供了多个示例和代码演示。
这篇博客详细记录了在NowCoder上的SQL刷题经历,重点讲解了MySQL中的字符串处理、OVER函数、CASE关键字的用法,以及在不同场景下IN和EXISTS的比较。内容涵盖字符串计数、窗口函数的应用、分组排名和条件判断,并提供了多个示例和代码演示。
nowcoder SQL刷题记录:
https://www.nowcoder.com/ta/sql
复习题目:12, 18, 21, 44, 57, 88, 60, 61, 91, 88
60虽然做出来了,但是对over中的partition by 和order by 还是不够理解,可以尝试不用window function可以做出来吗
61虽然做出来了,但是学习子查询欠缺
91虽然做出来了,但是with语法并不会
88有大佬使用了一个NB的解法,这个题和76题并不同,76题是单个条目取中位数的数据,但是88是很多条目累计的和,如果使用76的方法肯定是行不通的
这个题要么取巧,要么还是好好复习
如果over中使用了order by 则之后的clause不用再使用order by语句,order by在window中使用会导致所有的行都有效
【Mysql】查找字符串'10,A,B' 中逗号','出现的次数cnt。
题目描述:查找字符串'10,A,B' 中逗号','出现的次数cnt。。
知识点总结:
统计字符串长度:
char_length('string')/char_length(column_name)
1、返回值为字符串string或者对应字段长度,长度的单位为字符,一个多字节字符(例如,汉字)算作一个单字符;
2、不管汉字还是数字或者是字母都算是一个字符;
3、任何编码下,多字节字符都算是一个字符;
参考资料来源:https://blog.youkuaiyun.com/iris_xuting/article/details/53763894
length('string')/length(column_name)
1、utf8字符集编码下,一个汉字是算三个字符,一个数字或字母算一个字符。
2、其他编码下,一个汉字算两个字符, 一个数字或字母算一个字符。
字符串替换:REPLACE(s,s1,s2),将字符串 s2 替代字符串 s 中的字符串 s1
MySQL常用函数:https://www.runoob.com/mysql/mysql-functions.html
代码:
| 1 |
|
select s.emp_no, a.max-min(s.salary) growth from (select emp_no, salary max from salaries where to_date='9999-01-01') a
LEFT JOIN salaries s on a.emp_no=s.emp_no GROUP BY s.emp_no ORDER BY growth;select s.emp_no, a.max-min(s.salary) growth from (select emp_no, salary max from salaries where to_date='9999-01-01') a LEFT JOIN salaries s on a.emp_no=s.emp_no GROUP BY s.emp_no ORDER BY growth
> 1055 - Expression #2 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'nowcoder.salaries.salary' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
对于下面的SQL,并不是不在group by 后边的字段出现在select中就会出现错误,但是必须是来自同一张表才可以
| select c.name, count(f.film_id) from film f join film_category fc on f.film_id=fc.film_id join category c on c.category_id=fc.category_id join ( select fc.category_id, count(fc.film_id) cnt from film f join film_category fc on f.film_id=fc.film_id group by fc.category_id ) r on r.category_id= fc.category_id where f.description like "%robot%" and r.cnt >= 5 group by c.category_id; |
非group by 的列查询出来的结果是不确定的,不是想要的那行数据
group by 之后的hvaing也只能出现group by后的字段吗?> 1054 - Unknown column 'client_id' in 'IN/ALL/ANY subquery'
select job, count(id) cnt from grade
In aggregated query without GROUP BY, expression #1 of SELECT list contains nonaggregated column 'nowcoder.grade.job'; this is incompatible with sql_mode=only_full_group_by
MySQL over函数的用法
over不能单独使用,要和分析函数:rank(),dense_rank(),row_number()等一起使用。
其参数:over(partition by columnname1 order by columnname2)
含义:按columname1指定的字段进行分组排序,或者说按字段columnname1的值进行分组排序。
例如:employees表中,有两个部门的记录:department_id =10和20
select department_id,rank() over(partition by department_id order by salary) from employees就是指在部门10中进行薪水的排名,在部门20中进行薪水排名。如果是partition by org_id,则是在整个公司内进行排名。
以下是个人见解:
sql中的over函数和row_numbert()函数配合使用,可生成行号。可对某一列的值进行排序,对于相同值的数据行进行分组排序。
执行语句:select row_number() over(order by AID DESC) as rowid,* from bb
CASE关键字有两种使用方法
分别是‘简单case函数’和‘case搜索函数’
简单case函数
| 1 2 3 4 |
|
case搜索函数
| 1 2 3 4 |
|
分析说明
-
- 简单case函数是case搜索函数的真子集
- 简单case函数的使用方法与一些高级语言(如:java)中的switch语句相似:CASE给定匹配字段,WHEN给出具体的字段值,如果匹配到后返回THEN值。
- 简单case函数其实就是case搜索函数的‘=’逻辑的实现。case搜索函数可以实现简单case函数的所有功能,而简单case函数却不可实现case搜索函数的‘=’逻辑以外的功能。
- case函数匹配原则
- case函数与switch的不同在于case仅返回第一个匹配到的结果,而switch则会在没有中断的情况下继续后面的判断,将会执行所有匹配的结果。
- case搜索函数比简单case函数更加灵活
- case搜索函数与简单case函数相比的灵活之处在于可以在WHEN中书写判断式。
- 简单case函数是case搜索函数的真子集
1、等值转换
SELECT user_name,( CASE WHEN sex = 0 THEN '男人' WHEN sex = 1 THEN '女人' ELSE '中性人' END ) AS 性别 FROM imooc_goddess;
SELECT user_name,( CASE sex WHEN 0 THEN '男人' WHEN 1 THEN '女人' ELSE null END ) AS 性别 FROM imooc_goddess;
2、范围转换
select user_name, (case when age BETWEEN 0 and 18 then '未成年' when age BETWEEN 18 and 30 then '成年' when age BETWEEN 30 and 50 then '中年人' else '老年人' end) as 年龄段
FROM imooc_goddess;
select user_name,(case when age>0 and age<=18 then '未成年' when age >18 and age<=30 then '成年' when age >30 and age<=50 then '中年人' else '老年人' end) as 年龄段 FROM imooc_goddess;
3、行转列
select name , (case when sub = 'english' then score else 0 end ) 'english' ,
(case when sub = 'maths' then score else 0 end) 'maths' ,
(case when sub = 'chinese' then score else 0 end) 'chinese'
FROM stu;
4、聚合函数使用case when
select name , sum((case when sub = 'english' then score else 0 end )) 'english' ,
sum((case when sub = 'maths' then score else 0 end)) 'maths' ,
sum((case when sub = 'chinese' then score else 0 end)) 'chinese'
FROM stu GROUP BY name ;
1.IF
表达式:IF( expr1 , expr2 , expr3 )
expr1条件,条件为true,则值是expr2 ,false,值就是expr3
2. IFNULL
表达式:IFNULL( expr1 , expr2)
在 expr1 的值不为 NULL的情况下都返回 expr1,否则返回 expr2
MySQL为查询结果添加序号
时间:2018-12-19
本文章向大家介绍MySQL为查询结果添加序号,主要包括MySQL为查询结果添加序号使用实例、应用技巧、基本知识点总结和需要注意事项,具有一定的参考价值,需要的朋友可以参考一下。

现在的要求是:根据salary的值排名,并添加序号。
有三种添加序号的方式:
- 顺序排名
- 顺序排名,有相同的salary采取并列,保持排名不变
- 顺序排名,采取并列,且排名不变的salary仍然占用一个位置
一、不考虑并列( “:=”表示赋值)
select
s.emp_no,s.salary,
@n:=@n+1 rank
from salaries s, (select @n:= 0) d
where s.to_date='9999-01-01' order by s.salary desc
查询结果
二、采取并列(需要添加一个字段来保存上一次的salary值进行比较,如果相同,排名不变;如果不同,排名+1)
select
s.emp_no,s.salary,
case
when @t=s.salary then @n
when @t:=s.salary then @n:=@n+1
end rank
from salaries s, (select @n:= 0,@t:= -1) d
where s.to_date='9999-01-01' order by s.salary desc
还有一种简便写法
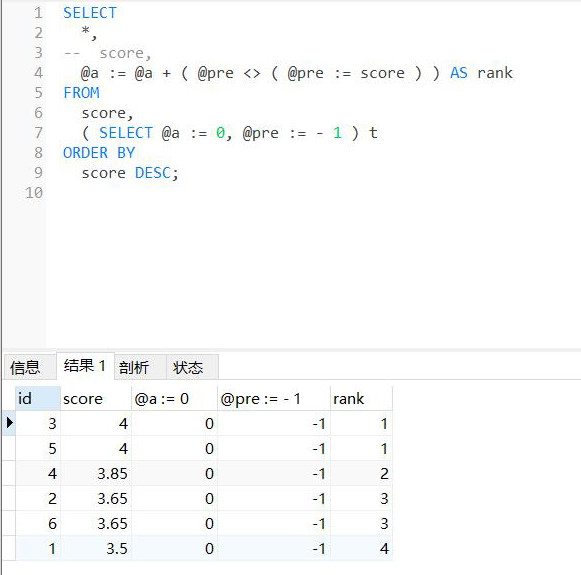
SELECT emp_no,salary,
@rank := @rank + (@pre <> (@pre := salary)) Rank
FROM salaries, (SELECT @rank := 0, @pre := -1) INIT
WHERE to_date = '9999-01-01
order by salary
mysql分组排序加序号(不用存储过程,就简简单单sql语句哦)
一 建表
CREATE TABLE `my_test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`parent_code` varchar(255) DEFAULT NULL,
`code` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8;
二 模拟数据
INSERT INTO `my_test` ( `parent_code`, `code`) VALUES ('01', '001');
INSERT INTO `my_test` ( `parent_code`, `code`) VALUES ('01', '002');
INSERT INTO `my_test` ( `parent_code`, `code`) VALUES ('02', '001');
INSERT INTO `my_test` ( `parent_code`, `code`) VALUES ('01', '003');
INSERT INTO `my_test` ( `parent_code`, `code`) VALUES ('02', '002');
INSERT INTO `my_test` ( `parent_code`, `code`) VALUES ('03', '001');
INSERT INTO `my_test` ( `parent_code`, `code`) VALUES ('04', '001');
查询 结果如下:

三 不分组加序号
select (@i := @i + 1) rownum,my_test.* from my_test , (SELECT @i := 0) AS a group by parent_code ,code ,id order by parent_code 结果如下:

解释一下 这个地方用了@i变量 刚开始的 让 @i=0 然后 每查询一条 让 @i+=1
四 分组 排序 加 序号了
刚开始的没 思路,就度娘了 ,有用 存储过程 创建临时表 插入临时表实现的,还有用存储过程游标实现,对于好久没动sql,而且之前也没写过mysql 查询的 淫来说 好复杂,
好囧 ,赶脚要再我女神面前丢人了,but 多谢上天眷顾,查看我女神聊天记录的时候,灵感来了,为什么不继续发掘下变量的作用呢 。

于是 再定义一个变量@pre_parent_code:='' 再存上一个 parent_code ,只要 pre_parent_code不等于当前的parent_code 让 @i:=0 else @i+=1 就ok了
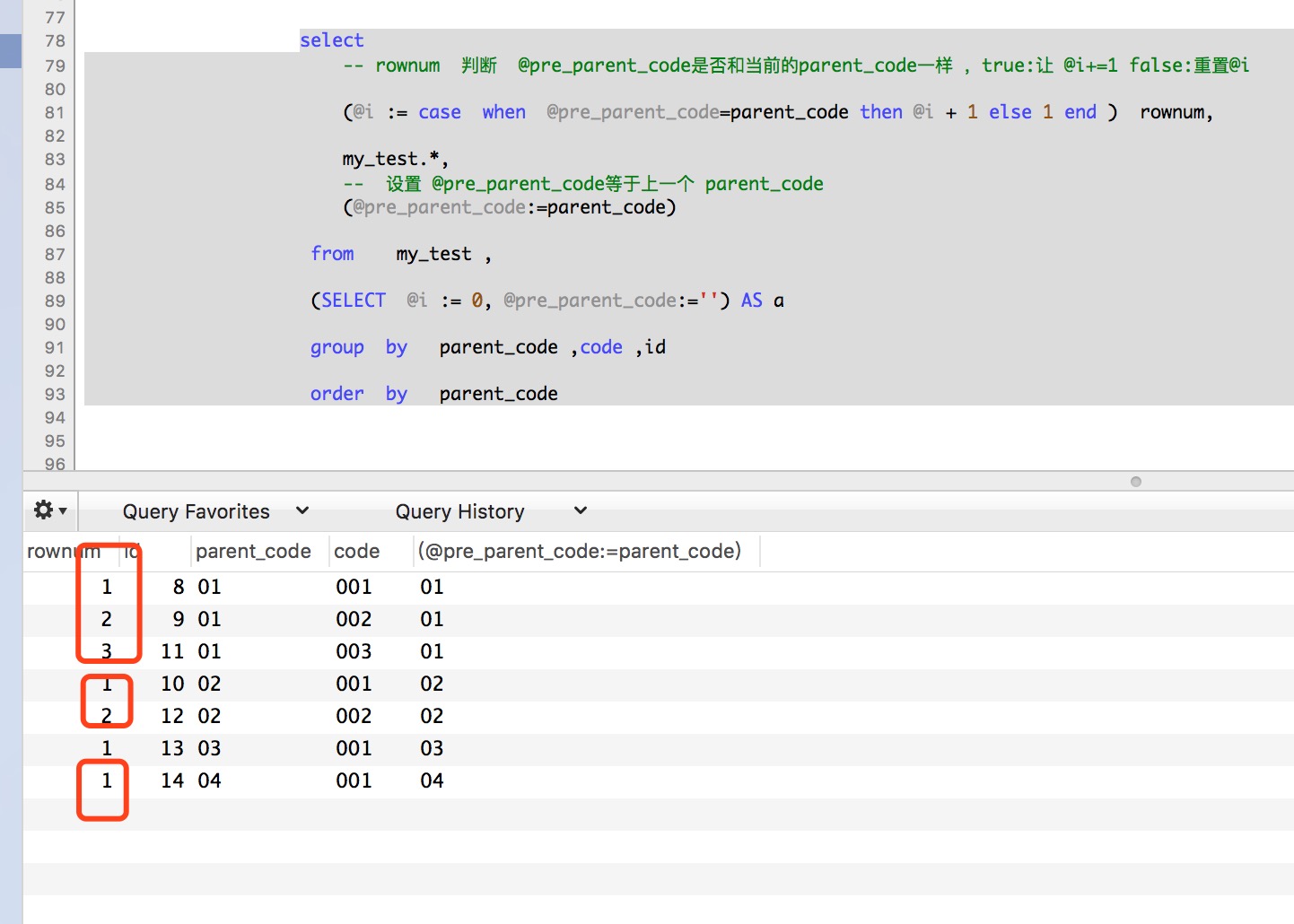
select
-- rownum 判断 @pre_parent_code是否和当前的parent_code一样 ,true:让 @i+=1 false:重置@i
(@i := case when @pre_parent_code=parent_code then @i + 1 else 1 end ) rownum,
my_test.*,
-- 设置 @pre_parent_code等于上一个 parent_code
(@pre_parent_code:=parent_code)
from my_test ,
(SELECT @i := 0, @pre_parent_code:='') AS a
group by parent_code ,code ,id
order by parent_code
结果如下图
链接:https://www.cnblogs.com/CharlieLau/p/6737243.html
mysql实现over()开窗函数功能
Mysql实现开窗函数功能:
参考:http://stackoverflow.com/questions/3333665/rank-function-in-mysql
CREATE TABLE person (id int, first_name varchar(20), age int, gender char(1));
INSERT INTO person VALUES (1, 'Bob', 25, 'M');
INSERT INTO person VALUES (2, 'Jane', 20, 'F');
INSERT INTO person VALUES (3, 'Jack', 30, 'M');
INSERT INTO person VALUES (4, 'Bill', 32, 'M');
INSERT INTO person VALUES (5, 'Nick', 22, 'M');
INSERT INTO person VALUES (6, 'Kathy', 18, 'F');
INSERT INTO person VALUES (7, 'Steve', 36, 'M');
INSERT INTO person VALUES (8, 'Anne', 25, 'F');
---------------------------------------------
--不是做分区,只做排名---
SELECT first_name,
age,
gender,
@curRank := @curRank + 1 AS rank
FROM person p, (SELECT @curRank := 0) r
ORDER BY age;
--分区排名:按照性别分区,on条件相等的那个,按照>条件的字段age作为排名--
SELECT a.first_name,
a.age,
a.gender,
count(b.age)+1 as 'rank'
FROM person a
left join person b
on a.age>b.age and a.gender=b.gender
group by a.first_name,
a.age,
a.gender
ORDER BY a.gender,a.age;MYSQL如何实现row_number()over()函数功能
一:创建表格
use data;
create table SC(SId varchar(10),CId varchar(10),score decimal(18,1));
insert into SC values('01' , '01' , 80);
insert into SC values('01' , '02' , 90);
insert into SC values('01' , '03' , 99);
insert into SC values('02' , '01' , 70);
insert into SC values('02' , '02' , 60);
insert into SC values('02' , '03' , 80);
insert into SC values('03' , '01' , 80);
insert into SC values('03' , '02' , 80);
insert into SC values('03' , '03' , 80);
insert into SC values('04' , '01' , 50);
insert into SC values('04' , '02' , 30);
insert into SC values('04' , '03' , 20);
insert into SC values('05' , '01' , 76);
insert into SC values('05' , '02' , 87);
insert into SC values('06' , '01' , 31);
insert into SC values('06' , '03' , 34);
insert into SC values('07' , '02' , 89);
insert into SC values('07' , '03' , 98);
二:代码编写
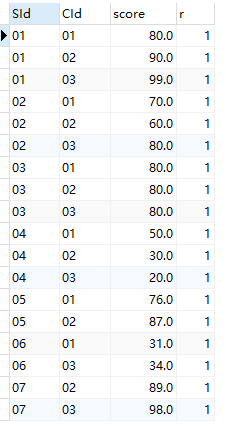
set @rank:=0;
set @CI:=null;
select SId,CId,score,rank from(
select
SId, CId,score,
@rank:=if(@CI=CId,@rank+1,1) as rank,
@CI:=CId
from data.sc
order by CId,score desc) as t1
mysql实现开窗函数、Mysql实现分析函数
目录
关键字:mysql实现开窗函数、Mysql实现分析函数、利用变量实现窗口函数
【Mysql5.7及以下版本】
适用范围:mysql5.7及以下版本,mysql8.0+ 可以直接使用窗口函数
注意,变量是从左到右顺序执行的
【测试数据】
-- 测试数据
CREATE TABLE `tem` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`str` char(1) DEFAULT NULL,
PRIMARY KEY (`id`)
) ;
INSERT INTO `test`.`tem`(`id`, `str`) VALUES (1, 'A');
INSERT INTO `test`.`tem`(`id`, `str`) VALUES (2, 'B');
INSERT INTO `test`.`tem`(`id`, `str`) VALUES (3, 'A');
INSERT INTO `test`.`tem`(`id`, `str`) VALUES (4, 'C');
INSERT INTO `test`.`tem`(`id`, `str`) VALUES (5, 'A');
INSERT INTO `test`.`tem`(`id`, `str`) VALUES (6, 'C');
INSERT INTO `test`.`tem`(`id`, `str`) VALUES (7, 'B');
【1】row_number() over(order by )
变量会最后再计算,所以是先排序好之后,才会开始计算@num
SELECT
@num := @num+1 num,
id,
str
FROM
tem, (SELECT @str := '', @num := 0) t1
ORDER BY
str, id;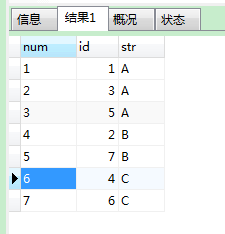
【2】实现分组排名效果(row_number() over(partition by order by ))
--变量方式
SELECT
@num := IF(@str = str, @num + 1, 1) num,
id,
@str := str str
FROM
tem, (SELECT @str := '', @num := 0) t1
ORDER BY
str, id;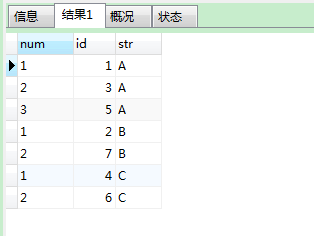
--子查询方式【取分组中前N行(排名前几名)】
mysql 相关子查询参考
select * from testGroup as a
where a.ID in (select ID from testGroup b where a.UserID = b.UserID order by b.OrderID limit 2)
--或者
select * from testGroup a
where not exists (select 1 from testGroup b where a.UserID = b.UserID and a.OrderID > b.OrderID
having count(1) >= 2)
--或者
select * from testGroup a
where (select count(1) from testGroup b where a.UserID = b.UserID and a.ID >= b.ID) <= 2
--没有唯一标识的表,可以用checksum来标识每行(MSSQL?)
select * from testGroup as a
where checksum(*) in (select top 2 checksum(*) from testGroup b where a.UserID = b.UserID order by b.OrderID)
mysql使用子查询实现
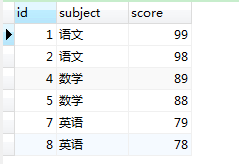
create table test1_1(id int auto_increment primary key,`subject` char(20),score int);
insert into test1_1 values(null,'语文',99),(null,'语文',98),(null,'语文',97);
insert into test1_1 values(null,'数学',89),(null,'数学',88),(null,'数学',87);
insert into test1_1 values(null,'英语',79),(null,'英语',78),(null,'英语',77);
-- 根据成绩,求出每个科目的前2名
select * from test1_1;
select * from test1_1 t1
where (select count(1) from test1_1 t2 where t1.subject=t2.subject and t2.score>=t1.score ) <=2;
-- 查询结果【左边】原表内容 【右边】需求结果,根据成绩,求出每个科目的前2名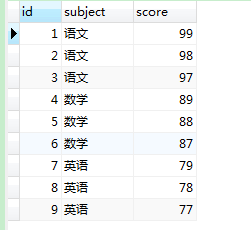
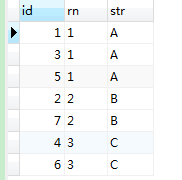
【3】实现dense_rank() over(order by)
--变量会最后再计算,所以是先排序好之后,才会开始计算@num
select id,@num:=IF(@STR=STR,@num,@num+1) rn,@str:=str str
from tem t1,(select @str:='',@num:=0) t2
order by str
--
---case when 形式,但该方法在mysql5.5中,只支持非0数字排序生成,字符会有大问题(任意字符被case when 'a' then else end,都会走else)
--且,赋值语句等于0时也为假
--错误的方式
select id,str,
case when @str=str then @num
when @str:=str then @num:=@num+1 end as 'rn'
from tem t1,(select @str:='',@num:=1) t2
order by str
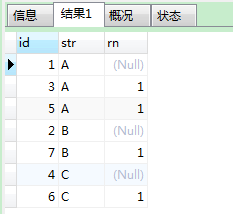
--正确的方式
select id,str,
case when @str=str then @num
when @str:=str then @num:=@num+1
else @num:=@num+1 end as 'rn'
from tem t1,(select @str:='',@num:=0) t2
order by str
--关于数字的case when 验证
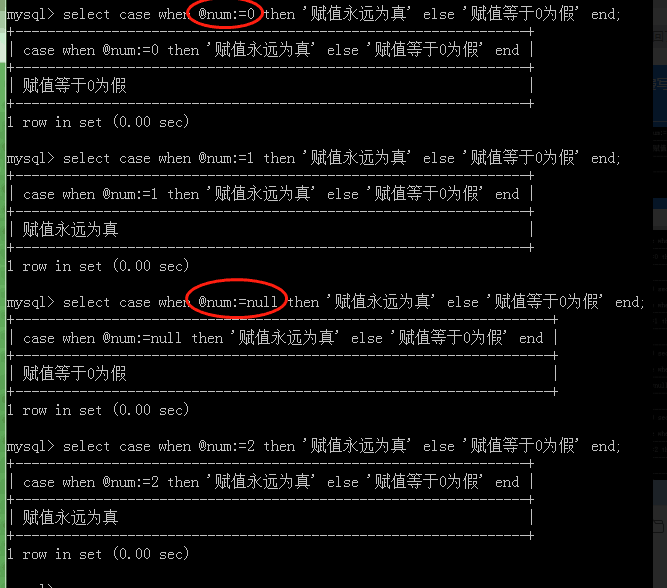
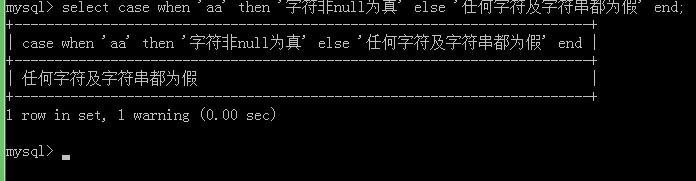
关于字符、字符串 的case when验证
【4】rank() over()
---------------------
测试数据代码大部分引用自:https://blog.youkuaiyun.com/mingqing6364/article/details/82621840
链接:https://www.cnblogs.com/gered/p/10430829.html
窗口函数
窗口:记录集合
窗口函数:在满足某些条件的记录集合上执行的特殊函数,对于每条记录都要在此窗口内执行函数。有的函数随着记录的不同,窗口大小都是固定的,称为静态窗口;有的函数则相反,不同的记录对应着不同的窗口,称为滑动窗口。
1. 窗口函数和普通聚合函数的区别:
①聚合函数是将多条记录聚合为一条;窗口函数是每条记录都会执行,有几条记录执行完还是几条。
②聚合函数也可以用于窗口函数。
2. 窗口函数的基本用法:
函数名 OVER 子句
over关键字用来指定函数执行的窗口范围,若后面括号中什么都不写,则意味着窗口包含满足WHERE条件的所有行,窗口函数基于所有行进行计算;如果不为空,则支持以下4中语法来设置窗口。
①window_name:给窗口指定一个别名。如果SQL中涉及的窗口较多,采用别名可以看起来更清晰易读;
②PARTITION BY 子句:窗口按照哪些字段进行分组,窗口函数在不同的分组上分别执行;
③ORDER BY子句:按照哪些字段进行排序,窗口函数将按照排序后的记录顺序进行编号;
④FRAME子句:FRAME是当前分区的一个子集,子句用来定义子集的规则,通常用来作为滑动窗口使用。
3. 按功能划分可将MySQL支持的窗口函数分为如下几类:
①序号函数:ROW_NUMBER()、RANK()、DENSE_RANK()
用途:显示分区中的当前行号
应用场景:查询每个学生的分数最高的前3门课程
ROW_NUMBER() OVER (PARTITION BY stu_id ORDER BY score)
mysql> SELECT *
-> FROM(
-> SELECT stu_id,
-> ROW_NUMBER() OVER (PARTITION BY stu_id ORDER BY score DESC) AS score_
order,
-> lesson_id, score
-> FROM t_score) t
-> WHERE score_order <= 3
-> ;
+--------+-------------+-----------+-------+
| stu_id | score_order | lesson_id | score |
+--------+-------------+-----------+-------+
| 1 | 1 | L005 | 98 |
| 1 | 2 | L001 | 98 |
| 1 | 3 | L004 | 88 |
| 2 | 1 | L002 | 90 |
| 2 | 2 | L003 | 86 |
| 2 | 3 | L001 | 84 |
| 3 | 1 | L001 | 100 |
| 3 | 2 | L002 | 91 |
| 3 | 3 | L003 | 85 |
| 4 | 1 | L001 | 99 |
| 4 | 2 | L005 | 98 |
| 4 | 3 | L002 | 88 |
+--------+-------------+-----------+-------+
对于stu_id=1的同学,有两门课程的成绩均为98,序号随机排了1和2。但很多情况下二者应该是并列第一,则他的成绩为88的这门课的序号可能是第2名,也可能为第3名。
这时候,ROW_NUMBER()就不能满足需求,需要RANK()和DENSE_RANK()出场,它们和ROW_NUMBER()非常类似,只是在出现重复值时处理逻辑有所不同。
mysql> SELECT *
-> FROM(
-> SELECT
-> ROW_NUMBER() OVER (PARTITION BY stu_id ORDER BY score DESC) AS score_order1,
-> RANK() OVER (PARTITION BY stu_id ORDER BY score DESC) AS score_order2,
-> DENSE_RANK() OVER (PARTITION BY stu_id ORDER BY score DESC) AS score_order3,
-> stu_id, lesson_id, score
-> FROM t_score) t
-> WHERE stu_id = 1 AND score_order1 <= 3 AND score_order2 <= 3 AND score_order3 <= 3
-> ;
+--------------+--------------+--------------+--------+-----------+-------+
| score_order1 | score_order2 | score_order3 | stu_id | lesson_id | score |
+--------------+--------------+--------------+--------+-----------+-------+
| 1 | 1 | 1 | 1 | L005 | 98 |
| 2 | 1 | 1 | 1 | L001 | 98 |
| 3 | 3 | 2 | 1 | L004 | 88 |
+--------------+--------------+--------------+--------+-----------+-------+
ROW_NUMBER():顺序排序——1、2、3
RANK():并列排序,跳过重复序号——1、1、3
DENSE_RANK():并列排序,不跳过重复序号——1、1、2
②分布函数:PERCENT_RANK()、CUME_DIST()
PERCENT_RANK()
用途:每行按照公式(rank-1) / (rows-1)进行计算。其中,rank为RANK()函数产生的序号,rows为当前窗口的记录总行数
应用场景:不常用
给窗口指定别名:WINDOW w AS (PARTITION BY stu_id ORDER BY score)
rows = 5
mysql> SELECT
-> RANK() OVER w AS rk,
-> PERCENT_RANK() OVER w AS prk,
-> stu_id, lesson_id, score
-> FROM t_score
-> WHERE stu_id = 1
-> WINDOW w AS (PARTITION BY stu_id ORDER BY score)
-> ;
+----+------+--------+-----------+-------+
| rk | prk | stu_id | lesson_id | score |
+----+------+--------+-----------+-------+
| 1 | 0 | 1 | L003 | 79 |
| 2 | 0.25 | 1 | L002 | 86 |
| 3 | 0.5 | 1 | L004 | 88 |
| 4 | 0.75 | 1 | L005 | 98 |
| 4 | 0.75 | 1 | L001 | 98 |
+----+------+--------+-----------+-------+
CUME_DIST()
用途:分组内小于、等于当前rank值的行数 / 分组内总行数
应用场景:查询小于等于当前成绩(score)的比例
cd1:没有分区,则所有数据均为一组,总行数为8
cd2:按照lesson_id分成了两组,行数各为4
mysql> SELECT stu_id, lesson_id, score,
-> CUME_DIST() OVER (ORDER BY score) AS cd1,
-> CUME_DIST() OVER (PARTITION BY lesson_id ORDER BY score) AS cd2
-> FROM t_score
-> WHERE lesson_id IN ('L001','L002')
-> ;
+--------+-----------+-------+-------+------+
| stu_id | lesson_id | score | cd1 | cd2 |
+--------+-----------+-------+-------+------+
| 2 | L001 | 84 | 0.125 | 0.25 |
| 1 | L001 | 98 | 0.75 | 0.5 |
| 4 | L001 | 99 | 0.875 | 0.75 |
| 3 | L001 | 100 | 1 | 1 |
| 1 | L002 | 86 | 0.25 | 0.25 |
| 4 | L002 | 88 | 0.375 | 0.5 |
| 2 | L002 | 90 | 0.5 | 0.75 |
| 3 | L002 | 91 | 0.625 | 1 |
+--------+-----------+-------+-------+------+
③前后函数:LAG(expr,n)、LEAD(expr,n)
用途:返回位于当前行的前n行(LAG(expr,n))或后n行(LEAD(expr,n))的expr的值
应用场景:查询前1名同学的成绩和当前同学成绩的差值
内层SQL先通过LAG()函数得到前1名同学的成绩,外层SQL再将当前同学和前1名同学的成绩做差得到成绩差值diff。
mysql> SELECT stu_id, lesson_id, score, pre_score,
-> score-pre_score AS diff
-> FROM(
-> SELECT stu_id, lesson_id, score,
-> LAG(score,1) OVER w AS pre_score
-> FROM t_score
-> WHERE lesson_id IN ('L001','L002')
-> WINDOW w AS (PARTITION BY lesson_id ORDER BY score)) t
-> ;
+--------+-----------+-------+-----------+------+
| stu_id | lesson_id | score | pre_score | diff |
+--------+-----------+-------+-----------+------+
| 2 | L001 | 84 | NULL | NULL |
| 1 | L001 | 98 | 84 | 14 |
| 4 | L001 | 99 | 98 | 1 |
| 3 | L001 | 100 | 99 | 1 |
| 1 | L002 | 86 | NULL | NULL |
| 4 | L002 | 88 | 86 | 2 |
| 2 | L002 | 90 | 88 | 2 |
| 3 | L002 | 91 | 90 | 1 |
+--------+-----------+-------+-----------+------+
④头尾函数:FIRST_VALUE(expr)、LAST_VALUE(expr)
用途:返回第一个(FIRST_VALUE(expr))或最后一个(LAST_VALUE(expr))expr的值
应用场景:截止到当前成绩,按照日期排序查询第1个和最后1个同学的分数
添加新列:mysql> ALTER TABLE t_score ADD create_time DATE;
1
mysql> SELECT stu_id, lesson_id, score, create_time,
-> FIRST_VALUE(score) OVER w AS first_score,
-> LAST_VALUE(score) OVER w AS last_score
-> FROM t_score
-> WHERE lesson_id IN ('L001','L002')
-> WINDOW w AS (PARTITION BY lesson_id ORDER BY create_time)
-> ;
+--------+-----------+-------+-------------+-------------+------------+
| stu_id | lesson_id | score | create_time | first_score | last_score |
+--------+-----------+-------+-------------+-------------+------------+
| 3 | L001 | 100 | 2018-08-07 | 100 | 100 |
| 1 | L001 | 98 | 2018-08-08 | 100 | 98 |
| 2 | L001 | 84 | 2018-08-09 | 100 | 99 |
| 4 | L001 | 99 | 2018-08-09 | 100 | 99 |
| 3 | L002 | 91 | 2018-08-07 | 91 | 91 |
| 1 | L002 | 86 | 2018-08-08 | 91 | 86 |
| 2 | L002 | 90 | 2018-08-09 | 91 | 90 |
| 4 | L002 | 88 | 2018-08-10 | 91 | 88 |
+--------+-----------+-------+-------------+-------------+------------+
⑤其它函数:NTH_VALUE(expr, n)、NTILE(n)
NTH_VALUE(expr,n)
用途:返回窗口中第n个expr的值。expr可以是表达式,也可以是列名
应用场景:截止到当前成绩,显示每个同学的成绩中排名第2和第3的成绩的分数
mysql> SELECT stu_id, lesson_id, score,
-> NTH_VALUE(score,2) OVER w AS second_score,
-> NTH_VALUE(score,3) OVER w AS third_score
-> FROM t_score
-> WHERE stu_id IN (1,2)
-> WINDOW w AS (PARTITION BY stu_id ORDER BY score)
-> ;
+--------+-----------+-------+--------------+-------------+
| stu_id | lesson_id | score | second_score | third_score |
+--------+-----------+-------+--------------+-------------+
| 1 | L003 | 79 | NULL | NULL |
| 1 | L002 | 86 | 86 | NULL |
| 1 | L004 | 88 | 86 | 88 |
| 1 | L001 | 98 | 86 | 88 |
| 1 | L005 | 98 | 86 | 88 |
| 2 | L004 | 75 | NULL | NULL |
| 2 | L005 | 77 | 77 | NULL |
| 2 | L001 | 84 | 77 | 84 |
| 2 | L003 | 86 | 77 | 84 |
| 2 | L002 | 90 | 77 | 84 |
+--------+-----------+-------+--------------+-------------+
NTILE(n)
用途:将分区中的有序数据分为n个等级,记录等级数
应用场景:将每门课程按照成绩分成3组
mysql> SELECT
-> NTILE(3) OVER w AS nf,
-> stu_id, lesson_id, score
-> FROM t_score
-> WHERE lesson_id IN ('L001','L002')
-> WINDOW w AS (PARTITION BY lesson_id ORDER BY score)
-> ;
+------+--------+-----------+-------+
| nf | stu_id | lesson_id | score |
+------+--------+-----------+-------+
| 1 | 2 | L001 | 84 |
| 1 | 1 | L001 | 98 |
| 2 | 4 | L001 | 99 |
| 3 | 3 | L001 | 100 |
| 1 | 1 | L002 | 86 |
| 1 | 4 | L002 | 88 |
| 2 | 2 | L002 | 90 |
| 3 | 3 | L002 | 91 |
+------+--------+-----------+-------+
NTILE(n)函数在数据分析中应用较多,比如由于数据量大,需要将数据平均分配到n个并行的进程分别计算,此时就可以用NTILE(n)对数据进行分组(由于记录数不一定被n整除,所以数据不一定完全平均),然后将不同桶号的数据再分配。
4. 聚合函数作为窗口函数:
用途:在窗口中每条记录动态地应用聚合函数(SUM()、AVG()、MAX()、MIN()、COUNT()),可以动态计算在指定的窗口内的各种聚合函数值
应用场景:截止到当前时间,查询stu_id=1的学生的累计分数、分数最高的科目、分数最低的科目
mysql> SELECT stu_id, lesson_id, score, create_time,
-> SUM(score) OVER w AS score_sum,
-> MAX(score) OVER w AS score_max,
-> MIN(score) OVER w AS score_min
-> FROM t_score
-> WHERE stu_id = 1
-> WINDOW w AS (PARTITION BY stu_id ORDER BY create_time)
-> ;
+--------+-----------+-------+-------------+-----------+-----------+-----------+
| stu_id | lesson_id | score | create_time | score_sum | score_max | score_min |
+--------+-----------+-------+-------------+-----------+-----------+-----------+
| 1 | L001 | 98 | 2018-08-08 | 184 | 98 | 86 |
| 1 | L002 | 86 | 2018-08-08 | 184 | 98 | 86 |
| 1 | L003 | 79 | 2018-08-09 | 263 | 98 | 79 |
| 1 | L004 | 88 | 2018-08-10 | 449 | 98 | 79 |
| 1 | L005 | 98 | 2018-08-10 | 449 | 98 | 79 |
+--------+-----------+-------+-------------+-----------+-----------+-----------+
参考链接:http://www.cnblogs.com/DataArt/p/9961676.html
https://blog.youkuaiyun.com/weixin_39010770/article/details/87862407
MySQL中In与Exists的区别
什么是exists
exists表示存在,它常常和子查询配合使用,例如下面的SQL语句
SELECT * FROM `user`
WHERE exists (SELECT * FROM `order` WHERE user.id = order.user_id)exists用于检查子查询是否至少会返回一行数据,该子查询实际上并不返回任何数据,而是返回值True或False。
当子查询返回为真时,则外层查询语句将进行查询。
当子查询返回为假时,外层查询语句将不进行查询或者查询不出任何记录。
因此上面的SQL语句旨在搜索出所有下过单的会员。需要注意的是,当我们的子查询为 SELECT NULL 时,MYSQL仍然认为它是True。
exists和in的区别和使用场景
是的,其实上面的例子,in这货也能完成,如下面SQL语句
SELECT * FROM `user`
WHERE id in (SELECT user_id FROM `order`)那么!in和exists到底有啥区别那,要什么时候用in,什么时候用exists那?接下来阿北一一教你。
我们先记住口诀再说细节!“外层查询表小于子查询表,则用exists,外层查询表大于子查询表,则用in,如果外层和子查询表差不多,则爱用哪个用哪个。”
In关键字原理
SELECT * FROM `user`
WHERE id in (SELECT user_id FROM `order`)in()语句只会执行一次,它查出order表中的所有user_id字段并且缓存起来,之后,检查user表的id是否和order表中的user_id相当,如果相等则加入结果期,直到遍历完user的所有记录。
in的查询过程类似于以下过程
$result = [];
$users = "SELECT * FROM `user`";
$orders = "SELECT user_id FROM `order`";
for($i = 0;$i < $users.length;$i++){
for($j = 0;$j < $orders.length;$j++){
// 此过程为内存操作,不涉及数据库查询。
if($users[$i].id == $orders[$j].user_id){
$result[] = $users[$i];
break;
}
}
}我想你已经看出来了,当order表数据很大的时候不适合用in,因为它最多会将order表数据全部遍历一次。
如:user表有10000条记录,order表有1000000条记录,那么最多有可能遍历10000*1000000次,效率很差.
再如:user表有10000条记录,order表有100条记录,那么最多有可能遍历10000*100次,遍历次数大大减少,效率大大提升.
exists关键字原理
SELECT * FROM `user`
WHERE exists (SELECT * FROM `order` WHERE user.id = order.user_id)在这里,exists语句会执行user.length次,它并不会去缓存exists的结果集,因为这个结果集并不重要,你只需要返回真假即可。
exists的查询过程类似于以下过程
$result = [];
$users = "SELECT * FROM `user`";
for($i=0;$i<$users.length;$i++){
if(exists($users[$i].id)){// 执行SELECT * FROM `order` WHERE user.id = order.user_id
$result[] = $users[$i];
}
}你看到了吧,当order表比user表大很多的时候,使用exists是再恰当不过了,它没有那么多遍历操作,只需要再执行一次查询就行。
如:user表有10000条记录,order表有1000000条记录,那么exists()会执行10000次去判断user表中的id是否与order表中的user_id相等.
如:user表有10000条记录,order表有100000000条记录,那么exists()还是执行10000次,因为它只执行user.length次,可见B表数据越多,越适合exists()发挥效果.
但是:user表有10000条记录,order表有100条记录,那么exists()还是执行10000次,还不如使用in()遍历10000*100次,因为in()是在内存里遍历,而exists()需要查询数据库,我们都知道查询数据库所消耗的性能更高,而内存比较很快.
因此我们只需要记住口诀:“外层查询表小于子查询表,则用exists,外层查询表大于子查询表,则用in,如果外层和子查询表差不多,则爱用哪个用哪个。”
MySQL中In与Exists的区别
1 例子
2 EXISTS和IN的介绍
2.1 exists
2.2 in
2.3 使用上的区别
3 EXISTS和IN的性能分析
4 总结
1 例子
有两个表需要关联查询,表的情况如下:
# 2759174行数据
SELECT COUNT(*) FROM tb_data t1;
# 7262行数据
SELECT COUNT(*) FROM tb_task t2;
# 执行时间为44.88s
SELECT SQL_NO_CACHE t1.id FROM tb_data t1 WHERE t1.task_id IN (SELECT t2.id FROM tb_task t2);
# 执行时间为28.93s
SELECT SQL_NO_CACHE t1.id FROM tb_data t1 WHERE EXISTS (SELECT * FROM tb_task t2 WHERE t1.task_id = t2.id);
有些地方会说:如果两个表中一个表大,另一个是表小,那么IN适合于外表大而子查询表小的情况;EXISTS适合于外表小而子查询表大的情况。
但是我们根据上面的例子可以发现并不满足这个规律。 t1表有两百多万行数据,t2表只有7千行数据。它们关联关系为t1.task_id = t2.id,我在使用IN时,t2表是子查询表,并且是小表,按理来说在这种情况下使用IN应该是更加合理的方式。
然后实际情况是使用IN需要44.88s,使用EXISTS需要28.93s
2 EXISTS和IN的介绍
2.1 exists
exists对外表用loop逐条查询,每次查询都会查看exists的条件语句,当exists里的条件语句能够返回记录行时(无论记录行是的多少,只要能返回),条件就为真,返回当前loop到的这条记录;反之,如果exists里的条件语句不能返回记录行,则当前loop到的这条记录被丢弃,exists的条件就像一个bool条件,当能返回结果集则为true,不能返回结果集则为false
如下:
select * from user where exists (select 1);
对user表的记录逐条取出,由于子条件中的select 1永远能返回记录行,那么user表的所有记录都将被加入结果集,所以与select * from user;是一样的。
又如下:
select * from user where exists (select * from user where user_id = 0);
可以知道对user表进行loop时,检查条件语句(select * from user where user_id = 0),由于user_id永远不为0,所以条件语句永远返回空集,条件永远为false,那么user表的所有记录都将被丢弃。、
总结:如果A表有n条记录,那么exists查询就是将这n条记录逐条取出,然后判断n遍exists条件。
2.2 in
in查询相当于多个or条件的叠加,这个比较好理解,比如下面的查询:
select * from user where user_id in (1, 2, 3);
等效于
select * from user where user_id = 1 or user_id = 2 or user_id = 3;
总结:in查询就是先将子查询条件的记录全都查出来,假设结果集为B,共有m条记录,然后再将子查询条件的结果集分解成m个,再进行m次查询。
2.3 使用上的区别
in查询的子条件返回结果必须只有一个字段,例如
select * from user where user_id in (select id from B);
不能是
select * from user where user_id in (select id, age from B);
而exists就没有这个限制。
3 EXISTS和IN的性能分析
为了便于分析,我把实际上的例子简化一下。
实际:
SELECT t1.id FROM tb_data t1 WHERE t1.task_id IN (SELECT t2.id FROM tb_task t2);
SELECT t1.id FROM tb_data t1 WHERE EXISTS (SELECT * FROM tb_task t2 WHERE t1.task_id = t2.id);
简化后:
SELECT * FROM A WHERE A.id IN (SELECT id FROM B);
SELECT * FROM A WHERE EXISTS (SELECT * from B WHERE B.id = A.id);
(1) in
假设B表的所有id为(1,2,3),查询1可以转换为:
SELECT * FROM A WHERE A.id = 1 OR A.id = 2 OR A.id = 3;
这里主要是用到了A的索引,B表如何对查询影响不大。
(2)exists
查询2可以转化以下伪代码:
for (i = 0; i < count(A); i++) {
a = get_record(A, i); #从A表逐条获取记录
if (B.id = a[id]) { #如果子条件成立
result[] = a;
}
}
return result;
这里主要用到了B表的索引,A表如何对查询的效率影响不大。
(3)实际情况
1)SELECT t1.id FROM tb_data t1 WHERE t1.task_id IN (SELECT t2.id FROM tb_task t2);
它使用的索引情况如下:
使用了t1(A)表索引
2)SELECT t1.id FROM tb_data t1 WHERE EXISTS (SELECT * FROM tb_task t2 WHERE t1.task_id = t2.id);
使用了t2(B)表索引
4 总结
《高性能MySQL》书上说,MySQL会把in的查询语句改成exists再去执行(实际上我们在没有索引情况下,他们的执行过程确实是一致的)
在《MySQL技术内幕:SQL编程》这本书中说:确实有很多DBA认为EXISTS比IN的执行效率更高,可能是当时优化器还不是很稳定和足够优秀,但是目前绝大数的情况下,IN和EXISTS都具有相同的执行计划。
1)IN查询在内部表和外部表上都可以使用到索引。
2)Exists查询仅在内部表上可以使用到索引。
3)当子查询结果集很大,而外部表较小的时候,Exists的Block Nested Loop(Block 嵌套循环)的作用开始显现,并弥补外部表无法用到索引的缺陷,查询效率会优于IN。
4)当子查询结果集较小,而外部表很大的时候,Exists的Block嵌套循环优化效果不明显,IN 的外表索引优势占主要作用,此时IN的查询效率会优于Exists。
5)表的规模不是看内部表和外部表,而是外部表和子查询结果集。
参考:
https://cloud.tencent.com/developer/article/1144244
https://cloud.tencent.com/developer/article/1144253
参考链接:https://blog.youkuaiyun.com/jinjiniao1/article/details/92666614
https://blog.youkuaiyun.com/lick4050312/article/details/4476333
https://segmentfault.com/a/1190000008709410
oracle in和exist的区别 not in 和not exist的区别

in 是把外表和内表作hash join,而exists是对外表作loop,每次loop再对内表进行查询。一般大家都认为exists比in语句的效率要高,这种说法其实是不准确的,这个是要区分环境的。
exists对外表用loop逐条查询,每次查询都会查看exists的条件语句,当 exists里的条件语句能够返回记录行时(无论记录行是的多少,只要能返回),条件就为真,返回当前loop到的这条记录,反之如果exists里的条件语句不能返回记录行,则当前loop到的这条记录被丢弃,exists的条件就像一个bool条件,当能返回结果集则为true,不能返回结果集则为 false。
例如:
select * from user where exists (select 1);
对user表的记录逐条取出,由于子条件中的select 1永远能返回记录行,那么user表的所有记录都将被加入结果集,所以与 select * from user;是一样的
又如下
select * from user where exists (select * from user where userId = 0);
可以知道对user表进行loop时,检查条件语句(select * from user where userId = 0),由于userId永远不为0,所以条件语句永远返回空集,条件永远为false,那么user表的所有记录都将被丢弃
not exists与exists相反,也就是当exists条件有结果集返回时,loop到的记录将被丢弃,否则将loop到的记录加入结果集
总的来说,如果A表有n条记录,那么exists查询就是将这n条记录逐条取出,然后判断n遍exists条件
in查询相当于多个or条件的叠加,这个比较好理解,比如下面的查询
select * from user where userId in (1, 2, 3);
等效于
select * from user where userId = 1 or userId = 2 or userId = 3;
not in与in相反,如下
select * from user where userId not in (1, 2, 3);
等效于
select * from user where userId != 1 and userId != 2 and userId != 3;
总的来说,in查询就是先将子查询条件的记录全都查出来,假设结果集为B,共有m条记录,然后在将子查询条件的结果集分解成m个,再进行m次查询
值得一提的是,in查询的子条件返回结果必须只有一个字段,例如
select * from user where userId in (select id from B);
而不能是
select * from user where userId in (select id, age from B);
而exists就没有这个限制
下面来考虑exists和in的性能:
对于以上两种情况,in是在内存里遍历比较,而exists需要查询数据库,所以当B表数据量较大时,exists效率优于in。
考虑如下SQL语句
select * from A where exists (select * from B where B.id = A.id);
select * from A where A.id in (select id from B);
1、select * from A where exists (select * from B where B.id = A.id);
exists()会执行A.length次,它并不缓存exists()结果集,因为exists()结果集的内容并不重要,重要的是其内查询语句的结果集空或者非空,空则返回false,非空则返回true。
它的查询过程类似于以下过程:
for ($i = 0; $i < count(A); $i++) {
$a = get_record(A, $i); #从A表逐条获取记录
if (B.id = $a[id]) #如果子条件成立
$result[] = $a;
}
return $result;
当B表比A表数据大时适合使用exists(),因为它没有那么多遍历操作,只需要再执行一次查询就行。
如:A表有10000条记录,B表有1000000条记录,那么exists()会执行10000次去判断A表中的id是否与B表中的id相等。
如:A表有10000条记录,B表有100000000条记录,那么exists()还是执行10000次,因为它只执行A.length次,可见B表数据越多,越适合exists()发挥效果。
再如:A表有10000条记录,B表有100条记录,那么exists()还是执行10000次,还不如使用in()遍历10000*100次,因为in()是在内存里遍历比较,而exists()需要查询数据库,我们都知道查询数据库所消耗的性能更高,而内存比较很快。
结论:exists()适合B表比A表数据大的情况
2、select * from A where id in (select id from B);
in()只执行一次,它查出B表中的所有id字段并缓存起来。之后,检查A表的id是否与B表中的id相等,如果相等则将A表的记录加入结果集中,直到遍历完A表的所有记录。
它的查询过程类似于以下过程:
Array A=(select * from A);
Array B=(select id from B);
for(int i=0;i<a.length;i++) { </a.length;i++) { <>
for(int j=0;j<b.length;j++) { </b.length;j++) { <>
if(A[i].id==B[j].id) {
resultSet.add(A[i]);
break;
}
}
}
return resultSet;
可以看出,当B表数据较大时不适合使用in(),因为它会B表数据全部遍历一次
如:A表有10000条记录,B表有1000000条记录,那么最多有可能遍历10000*1000000次,效率很差。
再如:A表有10000条记录,B表有100条记录,那么最多有可能遍历10000*100次,遍历次数大大减少,效率大大提升。
结论:in()适合B表比A表数据小的情况
当A表数据与B表数据一样大时,in与exists效率差不多,可任选一个使用。
在插入记录前,需要检查这条记录是否已经存在,只有当记录不存在时才执行插入操作,可以通过使用 EXISTS 条件句防止插入重复记录。
insert into A (name,age) select name,age from B where not exists (select 1 from A where A.id=B.id);
EXISTS与IN的使用效率的问题,通常情况下采用exists要比in效率高,因为IN不走索引。但要看实际情况具体使用:IN适合于外表大而内表小的情况;EXISTS适合于外表小而内表大的情况。
下面再看not exists 和 not in
1、select * from A where not exists (select * from B where B.id = A.id);
2、select * from A where A.id not in (select id from B);
看查询1,还是和上面一样,用了B的索引;而对于查询2,可以转化成如下语句
select * from A where A.id != 1 and A.id != 2 and A.id != 3;
可以知道not in是个范围查询,这种!=的范围查询无法使用任何索引,等于说A表的每条记录,都要在B表里遍历一次,查看B表里是否存在这条记录
not in 和not exists:如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;而not extsts 的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快,故not exists比not in效率高。
in 与 =的区别
select name from student where name in ('zhang','wang','li','zhao');
与
select name from student where name='zhang' or name='li' or name='wang' or name='zhao'
的结果是相同的。
在我们一般的观点中,总是认为使用EXISTS(或NOT EXISTS)通常将提高查询的效率,所以一般推荐使用exists来代替in。但实际情况是不是这个样子呢?我们分别在两种不同的优化器模式下用实际的例子来看一下:
SEIANG@seiang11g>create table wjq1 as select * from dba_objects;
Table created.
SEIANG@seiang11g>create table wjq2 as select * from dba_tables ;
Table created.
SEIANG@seiang11g>create index idx_object_name on wjq1(object_name);
Index created.
SEIANG@seiang11g>create index idx_table_name on wjq2(table_name);
Index created.
SEIANG@seiang11g>select count(*) from wjq1;
COUNT(*)
----------
86976
SEIANG@seiang11g>select count(*) from wjq2;
COUNT(*)
----------
2868
一、内查询结果集比较小,而外查询较大的时候的情况
1、在CBO模式下:
SEIANG@seiang11g>select * from wjq1 where object_name in (select table_name from wjq2 where table_name like 'M%');
815 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 1638414738
---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1238 | 270K| 354 (1)| 00:00:05 |
|* 1 | HASH JOIN RIGHT SEMI| | 1238 | 270K| 354 (1)| 00:00:05 |
|* 2 | INDEX RANGE SCAN | IDX_TABLE_NAME | 772 | 13124 | 7 (0)| 00:00:01 |
|* 3 | TABLE ACCESS FULL | WJQ1 | 5503 | 1112K| 347 (1)| 00:00:05 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("OBJECT_NAME"="TABLE_NAME")
2 - access("TABLE_NAME" LIKE 'M%')
filter("TABLE_NAME" LIKE 'M%')
3 - filter("OBJECT_NAME" LIKE 'M%')
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
17 recursive calls
0 db block gets
1462 consistent gets
1256 physical reads
0 redo size
46140 bytes sent via SQL*Net to client
1117 bytes received via SQL*Net from client
56 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
815 rows processed
SEIANG@seiang11g>select * from wjq1 where exists (select 1 from wjq2 where wjq1.object_name=wjq2.table_name and wjq2.table_name like 'M%');
815 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 1638414738
---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1238 | 270K| 354 (1)| 00:00:05 |
|* 1 | HASH JOIN RIGHT SEMI| | 1238 | 270K| 354 (1)| 00:00:05 |
|* 2 | INDEX RANGE SCAN | IDX_TABLE_NAME | 772 | 13124 | 7 (0)| 00:00:01 |
|* 3 | TABLE ACCESS FULL | WJQ1 | 5503 | 1112K| 347 (1)| 00:00:05 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("WJQ1"."OBJECT_NAME"="WJQ2"."TABLE_NAME")
2 - access("WJQ2"."TABLE_NAME" LIKE 'M%')
filter("WJQ2"."TABLE_NAME" LIKE 'M%')
3 - filter("WJQ1"."OBJECT_NAME" LIKE 'M%')
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
13 recursive calls
0 db block gets
1462 consistent gets
1242 physical reads
0 redo size
46140 bytes sent via SQL*Net to client
1117 bytes received via SQL*Net from client
56 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
815 rows processed
通过上面执行计划对比发现:
在CBO模式下,我们可以看到这两者的执行计划完全相同,统计数据也相同。
我们再来看一下RBO模式下的情况,这种情况相对复杂一些。
2、在RBO模式下:
SEIANG@seiang11g>select /*+ rule*/ * from wjq1 where object_name in (select table_name from wjq2 where table_name like 'M%');
815 rows selected.
Elapsed: 00:00:00.01
Execution Plan
----------------------------------------------------------
Plan hash value: 144941173
--------------------------------------------------------
| Id | Operation | Name |
--------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | NESTED LOOPS | |
| 2 | NESTED LOOPS | |
| 3 | VIEW | VW_NSO_1 |
| 4 | SORT UNIQUE | |
|* 5 | INDEX RANGE SCAN | IDX_TABLE_NAME |
|* 6 | INDEX RANGE SCAN | IDX_OBJECT_NAME |
| 7 | TABLE ACCESS BY INDEX ROWID| WJQ1 |
--------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
5 - access("TABLE_NAME" LIKE 'M%')
filter("TABLE_NAME" LIKE 'M%')
6 - access("OBJECT_NAME"="TABLE_NAME")
Note
-----
- rule based optimizer used (consider using cbo)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
698 consistent gets
0 physical reads
0 redo size
55187 bytes sent via SQL*Net to client
1117 bytes received via SQL*Net from client
56 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
815 rows processed
SEIANG@seiang11g>select /*+ rule*/ * from wjq1 where exists (select 1 from wjq2 where wjq1.object_name=wjq2.table_name and wjq2.table_name like 'M%');
815 rows selected.
Elapsed: 00:00:00.15
Execution Plan
----------------------------------------------------------
Plan hash value: 3545670754
---------------------------------------------
| Id | Operation | Name |
---------------------------------------------
| 0 | SELECT STATEMENT | |
|* 1 | FILTER | |
| 2 | TABLE ACCESS FULL| WJQ1 |
|* 3 | INDEX RANGE SCAN | IDX_TABLE_NAME |
---------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter( EXISTS (SELECT 0 FROM "WJQ2" "WJQ2" WHERE
"WJQ2"."TABLE_NAME"=:B1 AND "WJQ2"."TABLE_NAME" LIKE 'M%'))
3 - access("WJQ2"."TABLE_NAME"=:B1)
filter("WJQ2"."TABLE_NAME" LIKE 'M%')
Note
-----
- rule based optimizer used (consider using cbo)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
91002 consistent gets
1242 physical reads
0 redo size
46140 bytes sent via SQL*Net to client
1117 bytes received via SQL*Net from client
56 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
815 rows processed
通过上面两个执行计划的对比发现:
在这里,我们可以看到实际上,使用in效率比exists效率更高。我们可以这样来理解这种情况:
对于in,RBO优化器选择的内存查询的结果作为驱动表来进行nest loops连接,所以当内存查询的结果集比较小的时候,这个in的效率还是比较高的。
对于exists,RBO优化器则是利用外查询表的全表扫描结果集过滤内查询的结果集,当外查询的表比较大的时候,相对效率比较低。
二、内查询结果集比较大,而外查询较小的时候的情况
1、在CBO模式下:
SEIANG@seiang11g>select * from wjq2 where table_name in (select object_name from wjq1 where object_name like 'S%');
278 rows selected.
Elapsed: 00:00:00.03
Execution Plan
----------------------------------------------------------
Plan hash value: 1807911610
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 278 | 164K| 55 (0)| 00:00:01 |
|* 1 | HASH JOIN SEMI | | 278 | 164K| 55 (0)| 00:00:01 |
|* 2 | TABLE ACCESS FULL| WJQ2 | 278 | 146K| 31 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | IDX_OBJECT_NAME | 4435 | 285K| 24 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("TABLE_NAME"="OBJECT_NAME")
2 - filter("TABLE_NAME" LIKE 'S%')
3 - access("OBJECT_NAME" LIKE 'S%')
filter("OBJECT_NAME" LIKE 'S%')
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
67 recursive calls
0 db block gets
403 consistent gets
446 physical reads
0 redo size
22852 bytes sent via SQL*Net to client
721 bytes received via SQL*Net from client
20 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
278 rows processed
SEIANG@seiang11g>
SEIANG@seiang11g>select * from wjq2 where exists (select 1 from wjq1 where wjq1.object_name=wjq2.table_name and wjq1.object_name like 'S%');
278 rows selected.
Elapsed: 00:00:00.02
Execution Plan
----------------------------------------------------------
Plan hash value: 1807911610
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 278 | 164K| 55 (0)| 00:00:01 |
|* 1 | HASH JOIN SEMI | | 278 | 164K| 55 (0)| 00:00:01 |
|* 2 | TABLE ACCESS FULL| WJQ2 | 278 | 146K| 31 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | IDX_OBJECT_NAME | 4435 | 285K| 24 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("WJQ1"."OBJECT_NAME"="WJQ2"."TABLE_NAME")
2 - filter("WJQ2"."TABLE_NAME" LIKE 'S%')
3 - access("WJQ1"."OBJECT_NAME" LIKE 'S%')
filter("WJQ1"."OBJECT_NAME" LIKE 'S%')
Note
-----
- dynamic sampling used for this statement (level=2)
Statistics
----------------------------------------------------------
13 recursive calls
0 db block gets
295 consistent gets
2 physical reads
0 redo size
22852 bytes sent via SQL*Net to client
721 bytes received via SQL*Net from client
20 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
278 rows processed
通过上面两个执行计划的对比发现:
虽然他们的执行计划相同,但是使用exists比使用in的物理读和逻辑读明显小很多,所以使用exists效率更高一下

















 605
605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









