







 本文对ChatGPT进行基础科普,从语言本质出发,介绍了从图灵测试到ChatGPT的发展历程,包括自然语言处理、词向量等内容。还阐述了ChatGPT相关的LM、Transformer、GPT、RLHF、LLM等技术原理,帮助外行人士了解其基本原理,以便更好地使用。
本文对ChatGPT进行基础科普,从语言本质出发,介绍了从图灵测试到ChatGPT的发展历程,包括自然语言处理、词向量等内容。还阐述了ChatGPT相关的LM、Transformer、GPT、RLHF、LLM等技术原理,帮助外行人士了解其基本原理,以便更好地使用。
ChatGPT基础科普
1、语言的本质
在这个星球上,每个生物都有自己独特的交流方式,但是无法理解其他生物的语言,没有办法与其他种类的生物进行有效沟通。而我们人类的交流方式就是语言。人类迅速掌握了语言的基本知识,还能够不断地创造新的词汇和表达方式。最终开始利用语言建立起复杂的社会体系,发展科学技术,创作美丽的艺术作品。语言成为了人类独特的本能,让他们在这个星球上独树一帜。正是因为掌握了语言这一强大的工具,人类得以在漫长的历史进程中不断发展和创新。无论是在社会交往、科学探索还是艺术创作方面,语言都发挥着至关重要的作用,成为人类独特的精神象征。而语言也自然而然成为了人类区别与其他物种的标志性特征,换句话说如果哪个物种掌握了语言,也就意味着这个物种诞生了智能。因此从人工智能的概念建立伊始,机器能否具备使用自然语言同人类沟通交流的能力,就成为了机器是否具有类人智能的一条重要标准。
2、从图灵测试到ChatGPT
2.1 图灵测试
1950年,艾伦•图灵(Alan Turing)发表论文《计算机器与智能》( Computing Machinery and Intelligence),提出并尝试回答“机器能否思考”这一关键问题。在论文中,图灵提出了“模仿游戏”(即图灵测试)的概念,用来检测机器智能水平。
图灵测试的核心思想:如果一台机器能够在与人类的对话中表现得足够自然,以至于人类无法区分它与真正的人类之间的区别,那么这台机器就可以被认为是具有智能的。换句话说,图灵测试试图通过模拟人类的语言交流能力来评估机器的智能水平。
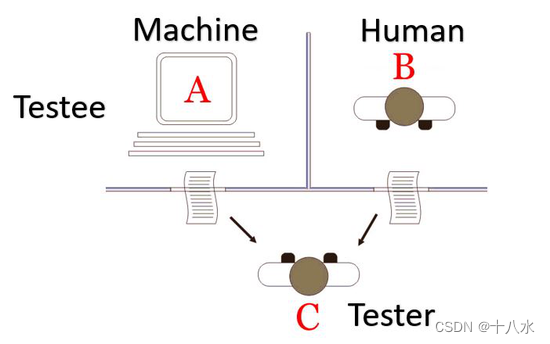
图灵测试的具体操作方法是:将一台机器和一名人类分别置于两个不同的房间,然后通过一个中介与他们进行对话。如果中介无法通过对话来判断哪个是人类,哪个是机器,那么这台机器就通过了图灵测试,可以被认为是具有智能的。
2.2 自然语言处理
1956年,人工智能正式成为了一个科学上的概念,而后涌现了很多新的研究目标与方向。虽然,图灵测试只是一个启发性的思想实验,而非可以具体执行的判断方法,但他却通过这个假设,阐明了“智能”判断的模糊性与主观性。从此图灵测试成为了 自然语言处理(Natural Language Processing,NLP) 任务的一个重要评测标准。图灵测试提供了一个客观和直观的方式来评估机器是否具有智能,即通过让机器与人类进行对话来判断其智能水平。这种方式可以避免对智能本质的哲学争论,也可以避免对智能具体表现形式的技术细节。因此,很多自然语言处理任务都可以用图灵测试来进行评测,例如对话系统、问答系统、文本生成等。
自然语言处理(Natural Language Processing,NLP)是计算机科学,人工智能,语言学关注计算机和人类(自然)语言之间的相互作用的领域。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理包括很多不同的任务,如分词、词性标注、句法分析、语义分析、信息抽取、文本分类、文本摘要、机器翻译、问答系统、对话系统等。
图灵测试与自然语言处理任务有着密切而复杂的关系,可以从以下两个方面来概括:
- 一方面,图灵测试是自然语言处理任务的一个重要驱动力。图灵测试提出了一个具有挑战性和吸引力的目标,即让机器能够用自然语言与人类进行流畅、智能、多样化的对话。为了达到这个目标,自然语言处理领域不断地发展和创新各种技术和方法,以提高机器对自然语言的理解和生成能力。例如,为了让机器能够回答用户提出的问题,就需要研究问答系统这一自然语言处理任务;为了让机器能够根据用户提供的信息生成合适的文本,就需要研究文本生成这一自然语言处理任务;为了让机器能够适应不同领域和场景的对话,就需要研究领域适应和情境感知这一自然语言处理任务等等。
- 另一方面,图灵测试是自然语言处理任务的一个重要目标。图灵测试提出了一个具有前瞻性和理想性的愿景,即让机器能够达到与人类相同或者超越人类的智能水平。这个愿景激发了很多自然语言处理领域的研究者和开发者,使他们不断地探索和创新,以期实现真正意义上的自然语言理解和生成。例如,为了让机器能够理解用户提出的问题,就需要研究语义分析、知识表示、逻辑推理;为了让机器能够生成符合用户需求的文本,就需要研究文本规划、文本风格、文本评价;为了让机器能够与用户建立信任和情感的联系,就需要研究情感分析、情感生成、情感对话等等。
2.3 自然语言发展历史
自然语言处理与人工智能发展历史有着密切而复杂的关系。它们相互促进、相互影响、相互依存。自然语言处理在人工智能发展历史上有很多里程碑式的成果,比如:
- 1954年,IBM实现了世界上第一个机器翻译系统,将俄语翻译成英语。
- 1966年,约瑟夫·韦伊岑鲍姆开发了ELIZA,一种模拟心理治疗师的对话系统。
- 1972年,特里·温诺格拉德开发了SHRDLU,一种能够理解和生成自然语言的程序,用于控制一个虚拟的机器人在一个虚拟的世界中进行操作。
- 1988年,杰拉尔德·萨斯曼和詹姆斯·马丁创建了Text Retrieval Conference(TREC),一个旨在推动信息检索和自然语言处理技术发展的国际评测活动。
- 2011年,苹果公司推出了Siri,一种基于自然语言处理技术的智能个人助理。同年,IBM的Watson战胜了《危险边缘》节目的冠军选手,展示了自然语言处理技术在问答领域的强大能力。
- 2013年,谷歌公司推出了Word2Vec,一种基于神经网络的词向量表示方法,开启了自然语言处理领域的深度学习时代。
- 2016年,Facebook发布了FastText的文本分类算法,它可以在处理大规模文本分类任务时取得很好的效果。
- 2017年,Google发布了一篇很可能是AI历史上最重要的一篇论文《Attention is all you need》,在论文中作者提出了Transformer——一个具有多头注意力机制的模型,在文本特征提取方面取得了优异的效果。
- 2018年,Google发布了BERT预训练模型,它在多项NLP任务上取得了最佳效果,引领自然语言处理进入了预训练时代。
- 2020年,OpenAI发布的GPT-3模型有多达1750亿的参数,可以在提供少量样本或不提供样本的前提下完成大多数NLP任务。
以上这些能力成果依赖于自然语言处理技术(NLP)的不断发展。NLP领域涉及到的技术非常广泛,但其中最基础的就是——词嵌入(也叫词向量,Word Embedding),以及与此相关的文本表征技术。它本质上是找到一种编码方式,实现从自然语言中到数学空间的映射。
2.4 词向量 Word Embedding
我们为什么需要词向量呢?当我对计算机说出“我爱你。”的时候,计算机无法真正理解我说了什么。要想让计算机理解我说的话,必须要对“我爱你。”这句话进行编码(Encoding)——比如:我们可以让数字“1”代表“我”,数字“2”代表“爱”,数字“3”代表“你”,数字“0”代表“句号”。经过编码之后,计算机才能理解这句话然后再进行计算和处理。词向量就是以单词为为单位进行编码,那么如何进行编码才是最优的方式呢?从1940年代开始,人们就希望寻找解决这个问题的模型和方法,下面选择最经典的词袋模型和神经网络概率模型,做一些简单一点的介绍。
- 词袋模型(Bag of Words,BOW):从名字来看,词袋模型就像是一个大袋子,把所有的词都装进来。文本中的每个单词都看作是独立的,忽略单词之间的顺序和语法,只关注单词出现的次数。在词袋模型中,每个文本可以表示为一个向量,向量的每个维度对应一个单词,维度的值表示该单词在文本中出现的次数。
- 神经概率语言模型(Neural Probabilistic Language Model,NPLM):它可以通过学习大量的文本数据来预测下一个单词或字符的概率。其中,最早的神经网络语言模型是由Yoshua Bengio等人于2003年发表的《A Neural Probabilistic Language Model》提出的,它在得到语言模型的同时也产生了副产品词向量。
早期的词向量都是静态的,一旦训练完就固定不变了。随着NLP技术的不断发展,词向量技术逐渐演变成基于语言模型的动态表征。语言模型不仅可以表征词,还可以表征任意文本。
时间来到了2022年,终于轮到我们的主角要隆重登场了。2022年11月30日OpenAI发布了一款真正的智能聊天机器人ChatGPT,一经发布立刻就点燃了AI圈。仅仅五天就达到了100万用户。OpenAI不得不紧急扩容,用户发现ChatGPT不仅仅只会插科打诨和人类聊天,它还能写论文,讲笑话,编段子,生成演讲稿,写请假条,模仿导师写推荐信,甚至帮你写代码,写营销策划案等等。拥有了ChatGPT,就像你身边配备了一个功能强大的秘书。到了2023年1月,大量用户开始涌入,仅仅两个月的时间ChatGPT成为了史上最快达到1亿用户的应用。
无论是ChatGPT,还是其他后来的模仿者,它们其实都是语言模型,准确来说——大语言模型。使用时,无论是调用API还是开源项目,总有一些参数可能需要调整。对大部分内行人士来说应该都不成问题,但对外行就有点玄乎了。基于此,本文将简要介绍ChatGPT相关技术基本原理,行文将站在外行人角度,尝试将内容尽量平民化。虽然不能深入细节,但知晓原理足以很好使用了。
2.5 大模型的主要构成
- LM:这是ChatGPT的基石的基石,是一个最基本的概念,绕不开,逃不过,没办法。
- Transformer:这是ChatGPT的基石,准确来说它的一部分是基石。
- GPT:本体,从GPT-1,一直到现在的GPT-4,按OpenAI自己的说法,模型还是那个模型,只是它长大了,变胖了,不过更好看了。关于这点,大家基本都没想到。现在好了,攀不上了。
- RLHF:ChatGPT神兵利器,有此利刃,ChatGPT才是那个ChatGPT,不然就只能是GPT-3。
3、LM
LM,Language Model,语言模型,简单来说就是利用自然语言构建的模型。这个自然语言就是人常说的话,或者记录的文字等等,只要是人生产出来的文字,都可以看做语言。你现在看到的文字也是。模型就是根据特定输入,通过一定计算输出相应结果的一个东西,可以把它当做人的大脑,输入就是你的耳、眼听或看到的文字,输出就是嘴巴说出来或手写出来的文字。总结一下,语言模型就是利用自然语言文本构建的,根据输入的文字,输出相应文字的模型。
3.1 概率语言模型
具体是怎么做的呢,方法有很多种,比如我写好一个模板:「XX喜欢YY」,如果XX=我,YY=你,那就是我喜欢你,反过来就是你喜欢我。我们这里重点要说的是概率语言模型,它的核心:下一个词出现的概率。这种语言模型的过程是通过已经有的词预测接下来的词。我们举个简单的例子,比如你只告诉模型:「我喜欢你」这句话,当你输入「我」的时候,它就知道你接下来要说「喜欢」了。为什么?因为它脑子里就只有这四个字,你没告诉它其他的呀。
好,接下来,我们要升级了。假设你给了模型很多很多句话,多到现在网上能找到的资料都给了它。这时候你再输入「我」,我敢打赌它大概不会说「喜欢」了。为什么?简单,见多了世面,眼里怎么可能只有喜欢你三个字。但因为我们考虑的是最大概率,很有可能它每次都会输出同样的话。对,没错,如果每次都只选择下个最大概率的词,你就是会得到同样的话。这种方法叫做Greedy Search(中文叫贪心搜索),很贪,很短视!所以,语言模型都会在这个地方做一些策略,让模型每一步多看几个可能的词,而不是就看那最高的一个,这样继续往下找的时候,你会发现到下一步时,刚刚最大概率的词,如果加上这一步的词,它的路径(两步概率乘积)概率可能没有刚刚小一点概率的词的路径概率大。举个例子,请看下面这幅图:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









