



java通过jdbc批量add,update,delete数据其实是在使用jdbc的batch相关的API。
但是底层怎么实现的?
mysql新增一张测试用的表:
create table student
(
id bigint not null primary key,
stu_no bigint not null,
name varchar(10) null,
constraint stu_no unique (stu_no)
);
批量插入
代码
Connection conn = null;
@Before
public void beforeClass() throws Exception {
// 注册mysql数据库jdbc连接驱动,
//高版本的mysql底层使用了SSL协议加密,会导致wireshark抓到的数据包不是明文,所以在这配置不加密,方便观察底层文本。
//rewriteBatchedStatements=true,配置后才能真的打开mysql批量操作功能
String url = "jdbc:mysql://localhost:3306/test?useSSL=false&&rewriteBatchedStatements=true";
String user = "root";
String password = "rootroot";
conn = DriverManager.getConnection(url, user, password);
}
@Test
public void testAdd() throws SQLException {
String SQL = "insert into student(id, stu_no, name) VALUES (?,?,?)";
PreparedStatement pstmt = conn.prepareStatement(SQL);
for (int i = 1; i < 20000; i++) {
pstmt.setLong(1, i);
pstmt.setInt(2, i);
pstmt.setString(3, "张三" + i);
pstmt.addBatch();
//每1000个sql执行一次。
if (i % 1000 == 0) {
int[] count = pstmt.executeBatch();
//每个sql执行成功后影响的数据行数。和单个执行的sql的返回意义一样
System.out.println("count:" + Arrays.toString(count));
pstmt.clearBatch();
}
}
}
底层
使用wireshark抓包看看底层数据:
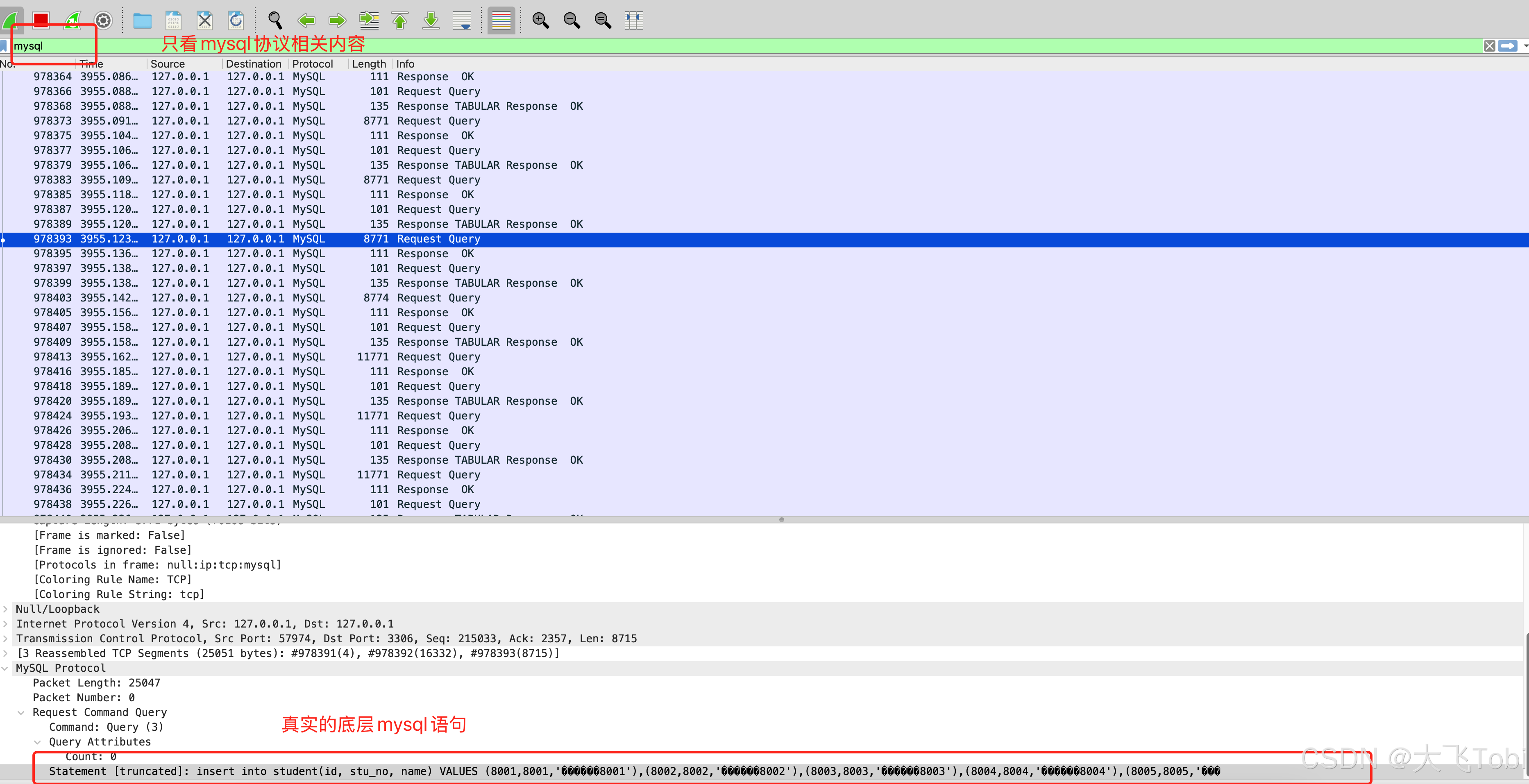
可见mysql的JDBC实现其实是将多个单独的insert语句拼接在了一起,一次性发送给mysql服务器。每批次的数量和我们调用executeBatch的流程吻合,1000个。
形式是insert into table(xx) values (xx),(xx),(xx); 的sql语句 。
返回的结果

执行插入语句的时候,mysql返回的结果是按照顺序匹配的。数组1000个代表着1000个sql的结果。
-2即SUCCESS_NO_INFO。阅读注释可知:代表SQL执行成功。但是服务端不返回影响行数。我想大概原因是因为sql最后变形成了一条合并的sql,没法单独返回了。 这一点也可以通过观察wireshark的RESPONSE得出结论。每个批次一个sql也只有一次返回应答。
批量修改
如果不是批量新增,而是批量修改。而且是独立不同的update语句呢?
代码
@Test
public void testUpdate() throws SQLException {
String SQL = "update student set name=? where id=?";
PreparedStatement pstmt = conn.prepareStatement(SQL);
for (int i = 1; i < 11; i++) {
pstmt.setString(1, "李四");
pstmt.setLong(2, i);
pstmt.addBatch();
}
int[] count = pstmt.executeBatch();
System.out.println("count:" + Arrays.toString(count));
}底层
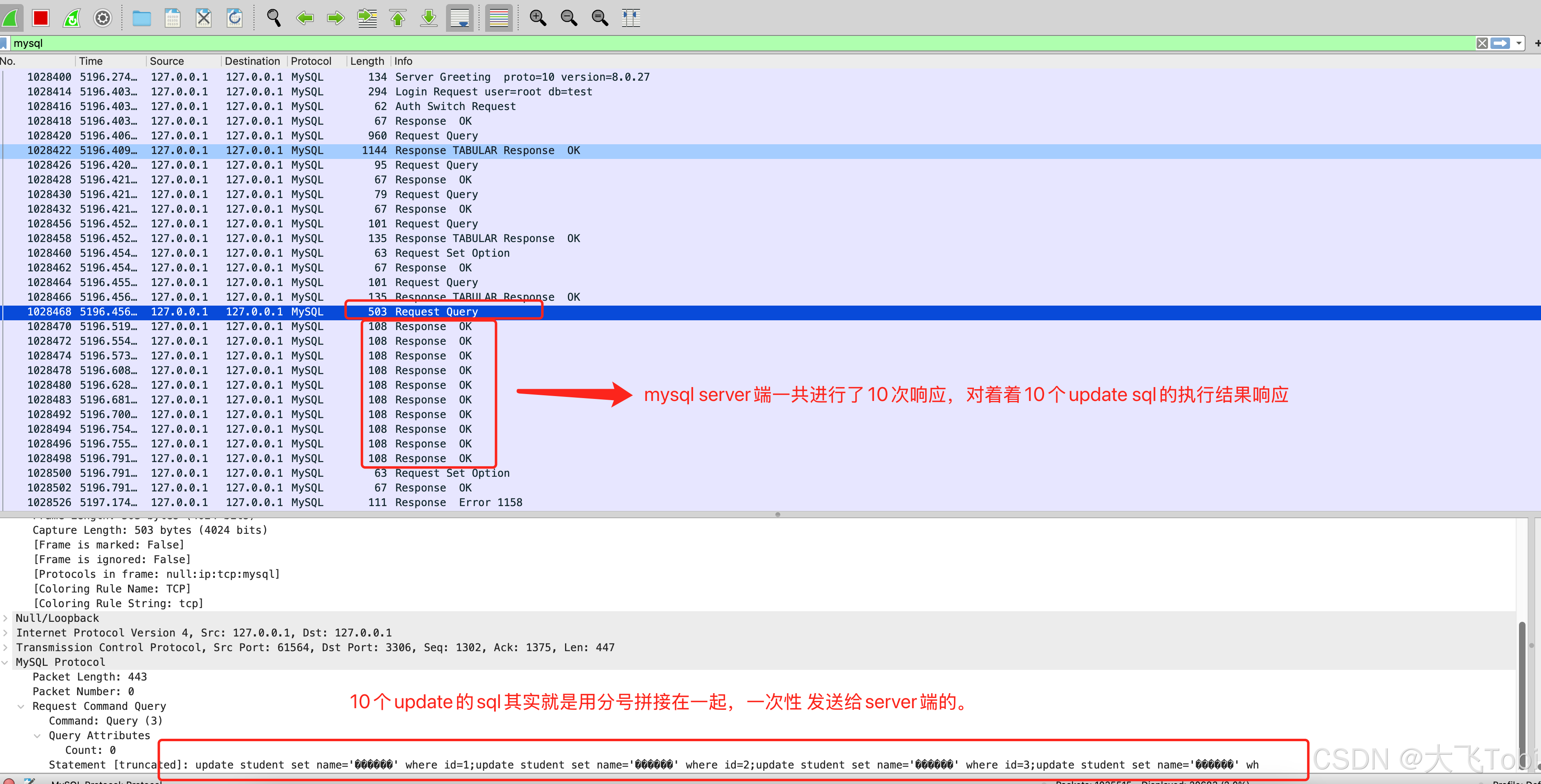
10个update的sql都是独立的,所以并不能简单像insert一样拼接成一个SQL。直接就是所有update sql用分号拼接上一次性发给server端。但是Server端的Response却是10次,不像刚才insert一样只有一次。
返回的结果

每个SQL对应的影响数据行数都正确返回了。
批量操作里有异常
如果一批次操作里有一条sql执行失败呢?
代码
@Test
public void testUpdateException() {
try {
String SQL = "update student set name=? where id=?";
PreparedStatement pstmt = conn.prepareStatement(SQL);
for (int i = 1; i < 11; i++) {
if (i == 5) {
//第五个SQL的时候name长度11,过长,会导致sql报错。
pstmt.setString(1, "张三张三张三张三张三张");
} else {
pstmt.setString(1, "张三");
}
pstmt.setLong(2, i);
pstmt.addBatch();
}
int[] count = pstmt.executeBatch();
System.out.println("count:" + Arrays.toString(count));
} catch (BatchUpdateException e) {
System.out.println(e.getMessage());
System.out.println("count:" + Arrays.toString(e.getUpdateCounts()));
} catch (SQLException e) {
throw new RuntimeException(e);
}
}底层
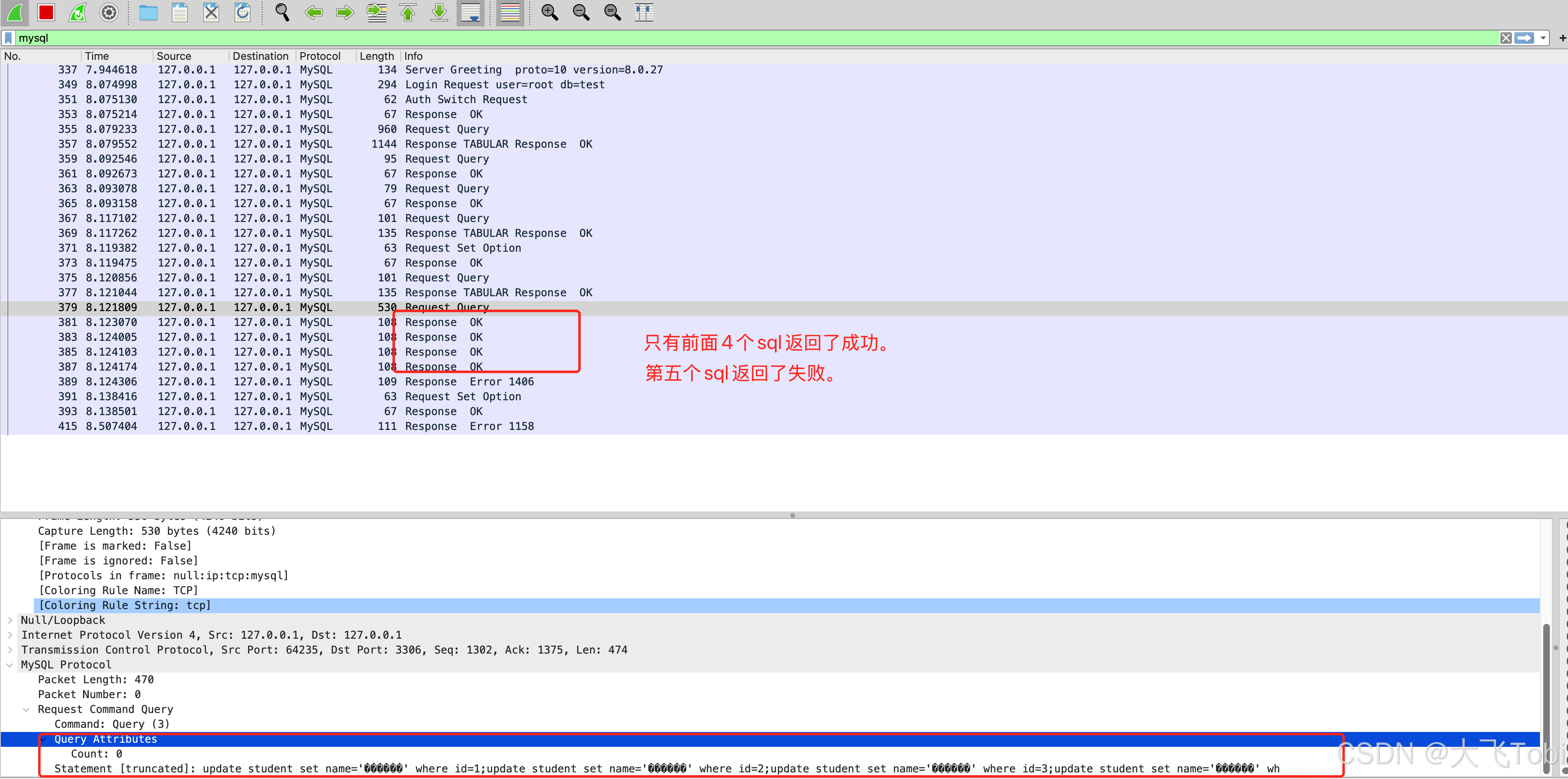
从 java.sql.Statement#executeBatch方法的注释来看,这种情况的结果取决于数据库的驱动实现。
要么从错误的SQL开始全部不执行,要们跳过错误的SQL继续执行后面的SQL。
从底层的数据看,mysql的实现是:从错误的SQL开始全部不执行
返回的结果

这里就非常奇怪。无法理解为什么有-1, -3的个数也不对。感觉是驱动实现的BUG。BatchUpdateException.getUpdateCounts returns unexpected value -1 · Issue #450 · awslabs/aws-mysql-jdbc · GitHub
批量操作和事务的关系
有很多人将批量操作和事务混淆一起说。似乎批量操作的sql都必须放在一个事务里。其实这2件事根本没有任何关系。批量操作的sql既可以是每个都是单独的事务,也可以是放在一个事务里。
至少在网络交互层面,其实没有多大区别。因为批量操作真正提速的关键点是:将多个sql合并到了一次网络交互里!
只不过我们在实际的业务中,提前将数据切成小批次的数据后,以每个小批次为一个事务,失败后整体重试。在代码实现上要简单很多。不用去比对到底是哪条sql异常了。
代码
@Test
public void testUpdateExceptionTransaction() {
try {
String SQL = "update student set name=? where id=?";
conn.setAutoCommit(false);
PreparedStatement pstmt = conn.prepareStatement(SQL);
for (int i = 1; i < 11; i++) {
if (i == 5) {
pstmt.setString(1, "张三张三张三张三张三张");
} else {
pstmt.setString(1, "张三");
}
pstmt.setLong(2, i);
pstmt.addBatch();
}
int[] count = pstmt.executeBatch();
conn.commit();
System.out.println("count:" + Arrays.toString(count));
} catch (BatchUpdateException e) {
System.out.println(e.getMessage());
System.out.println("count:" + Arrays.toString(e.getUpdateCounts()));
} catch (SQLException e) {
throw new RuntimeException(e);
}
}底层
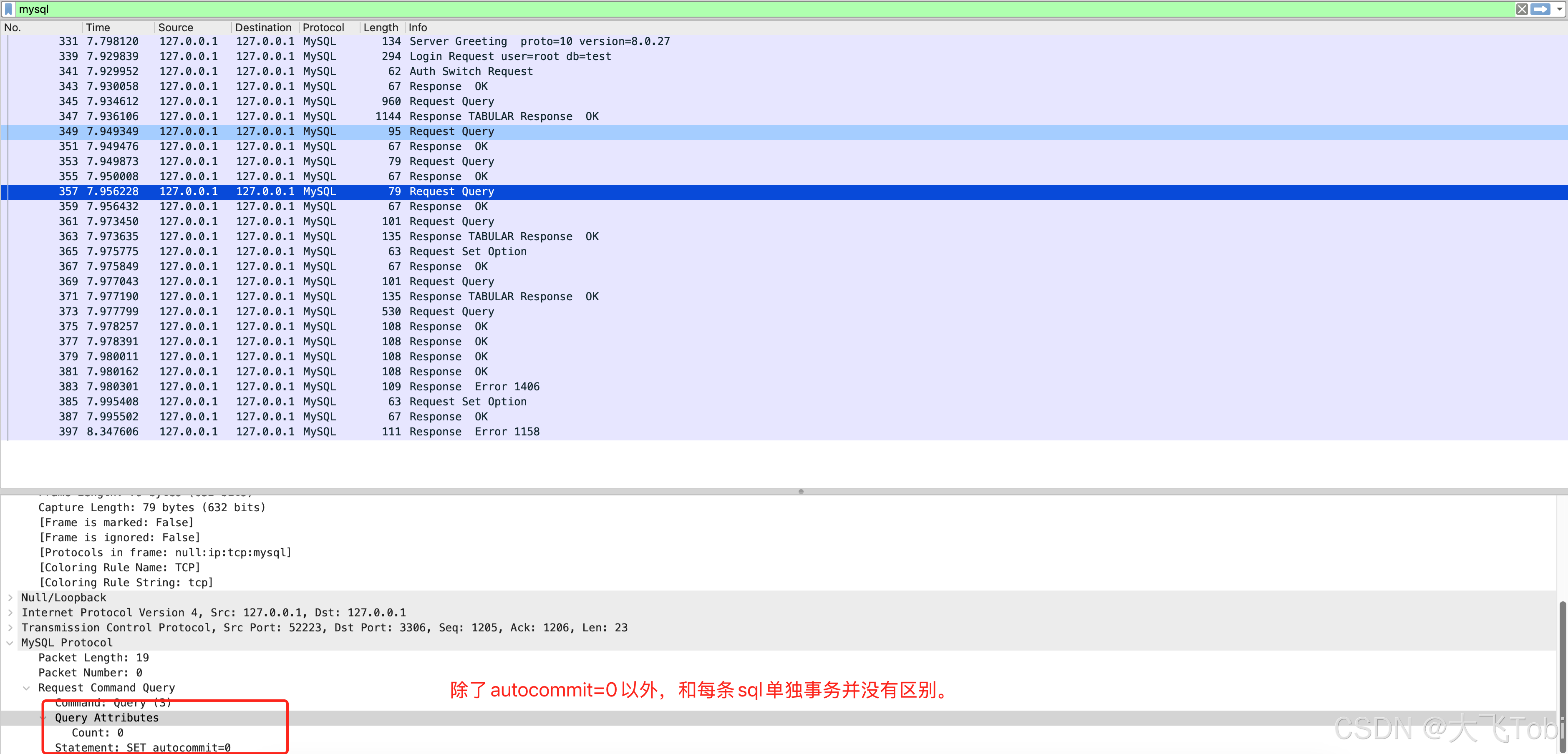
网络交互几乎没有却别。当然数据库因为整体一个事务的原因,其实底层一条sql也没真正执行成功。
返回的结果

和每条sql的单独事务返回的结果一样。但是这里要警觉,其实因为统一一个事务的原因,其实一条都没成功!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









