




初学调试技术,记录一下X64位模式下4-kbyte虚拟地址转换到物理地址的验证流程,该模式下虚拟地址包含了4个表的索引以及一个地址偏移,其中的47到0这个48个位分段对应了PML4E,PDPE,PDE,PTE这4个表的索引值,以及地址偏移,对应的位置和位数下图:
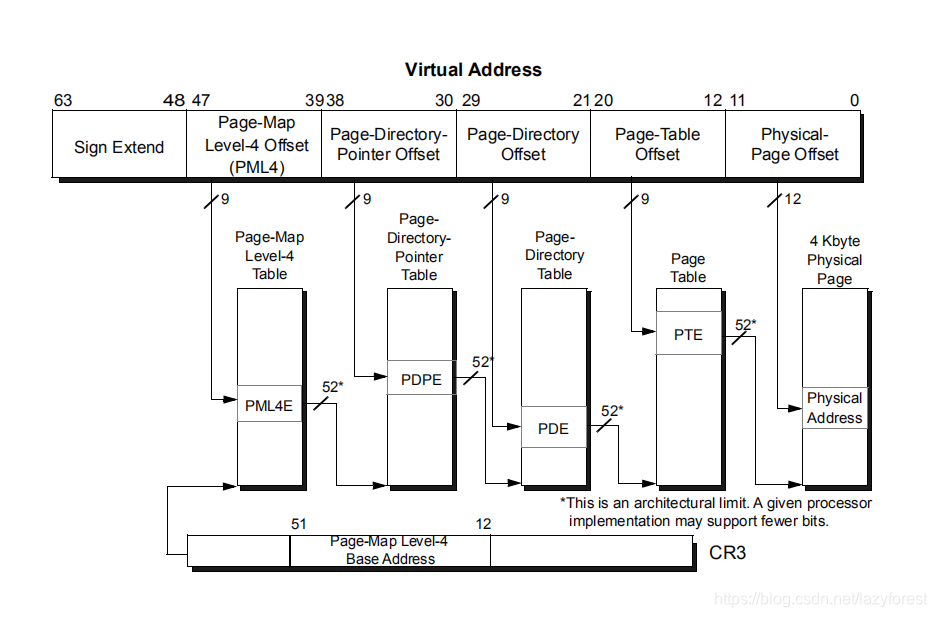
这里只是示意一下,我是看了AMD64 Architecture Programmer’s Manual Volume 2 System Programming这本手册中的Page Translation and Protection 这一章才对相关的模式的细节有所了解,需要说明的是Intel和AMD的CPU的实现是不同的所以如果你和我一样是AMD的CPU,要想搞懂在没有其它的资料的情况下是需要看一遍的,欢迎各位同学推荐其它相关资料。
我的环境是windows10 , CPU 是AMD Ryzen 7 1700X,工具用到了vc++,windbg,livekd。
首先用vc++写个小程序用来调试代码如下:
#include<Windows.h>
#include<stdio.h>
int main()
{
Sleep(1);
char c[10] = "123456789";
return 0;
}
调用Sleep(1) 这个函数用来在windbg调试的时候下断点确定代码位置,用于定位语句char c[10] = "123456789";的位置。c[10] = "123456789"这个变量的数字可以稍微长点有规律点,这样容易在内存中识别出来。
然后用windbg 在用户模式打开这个这个小程序进行调试,下断点:
0:000> bp KERNELBASE!Sleep
运行遇到断点停下,跳出sleep函数,在我的环境下再走几步就到了这句:
00007ff7`95b41812 f3a4 rep movs byte ptr [rdi],byte ptr [rsi]
这句应该是char c[10] = "123456789"; 的汇编语句,这时查看了rdi的包含的地址
是7ff795b49bb0,然后执行赋值的语句,接着用命令查看这个位置:
0:000> dd 7ff795b49bb0
00007ff7`95b49bb0 34333231 38373635 00000039 00000000
00007ff7`95b49bc0 00000000 00000000 00000000 00000000
00007ff7`95b49bd0 00000000 00000000 00000000 00000000
00007ff7`95b49be0 00000000 00000000 00000000 00000000
00007ff7`95b49bf0 00000000 00000000 00000000 00000000
00007ff7`95b49c00 00000000 00000000 00000000 00000000
00007ff7`95b49c10 00000000 00000000 00000000 00000000
00007ff7`95b49c20 00000000 00000000 00000000 00000000
这个地址中值已经赋上了,接下来把这个地址翻译成二进制格式,以便获取索引值和偏移:
0:000> .formats 00007ff7`95b49bb0
Evaluate expression:
Hex: 00007ff7`95b49bb0
Decimal: 140701345291184
Octal: 0000003777362555115660
Binary: 00000000 00000000 01111111 11110111 10010101 10110100 10011011 10110000
Chars: .......
Time: Wed Jun 13 04:22:14.529 1601 (UTC + 8:00)
Float: low -7.29471e-026 high 4.59051e-041
Double: 6.95157e-310
进程不要关了,接下来用livekd进入内核模式,首先通过进程id找出前面程序的DirBase目录表的地址,通过这个地址可以找到PML4E,然后结合虚拟地址中获得的索引值找对应项,这里DirBase是3ec228000:
0: kd> !process 22a8
Searching for Process with Cid == 22a8
PROCESS ffffe703ba3cb280
SessionId: 1 Cid: 22a8 Peb: bd605d6000 ParentCid: 4070
FreezeCount 1
DirBase: 3ec228000 ObjectTable: ffff9c85f9b75b40 HandleCount: 42.
下面的命令是找PML4E中对应的项目,其中 0x7f8 是虚拟地址中39到47位二进制表示的数字乘以8字节得出的,因为PML4E中的项目在该模式下是8字节一项,这项的值是0a000002`8ab38867 根据前面手册中的描述,该值二进制12到51位表示下一级表的地址,取得了这个地址再加上虚拟地址中对应的索引值就可以找到下一个表中对应的项目:
0: kd> !dq 3ec228000 + 0x7f8
#3ec2287f8 0a000002`8ab38867 00000000`00000000
#3ec228808 00000000`00000000 00000000`00000000
#3ec228818 00000000`00000000 00000000`00000000
#3ec228828 00000000`00000000 00000000`00000000
#3ec228838 00000000`00000000 00000000`00000000
#3ec228848 00000000`00000000 00000000`00000000
#3ec228858 00000000`00000000 00000000`00000000
#3ec228868 00000000`00000000 00000000`00000000
上一步找到的值取12到51位是028ab38000加上对应的索引值找PDPE中对应的项目:
0: kd> !dq 028ab38000 + 0xef0
#28ab38ef0 0a000003`46d39867 00000000`00000000
#28ab38f00 00000000`00000000 00000000`00000000
#28ab38f10 00000000`00000000 00000000`00000000
#28ab38f20 00000000`00000000 00000000`00000000
#28ab38f30 00000000`00000000 00000000`00000000
#28ab38f40 00000000`00000000 00000000`00000000
#28ab38f50 00000000`00000000 00000000`00000000
#28ab38f60 00000000`00000000 00000000`00000000
同理找PDE中对应的项目:
0: kd> !dq 346d39000 + 0x568
#346d39568 0a000002`6ef3a867 00000000`00000000
#346d39578 00000000`00000000 00000000`00000000
#346d39588 00000000`00000000 00000000`00000000
#346d39598 00000000`00000000 00000000`00000000
#346d395a8 00000000`00000000 00000000`00000000
#346d395b8 00000000`00000000 00000000`00000000
#346d395c8 00000000`00000000 00000000`00000000
#346d395d8 00000000`00000000 00000000`00000000
同理找PTE中对应的项目:
0: kd> !dq 346d39000 + 0x568
#346d39568 0a000002`6ef3a867 00000000`00000000
#346d39578 00000000`00000000 00000000`00000000
#346d39588 00000000`00000000 00000000`00000000
#346d39598 00000000`00000000 00000000`00000000
#346d395a8 00000000`00000000 00000000`00000000
#346d395b8 00000000`00000000 00000000`00000000
#346d395c8 00000000`00000000 00000000`00000000
#346d395d8 00000000`00000000 00000000`00000000
最后加上偏移找到物理内存地址:
0: kd> !dq 26dacb000 + 0xbb0
#26dacbbb0 38373635`34333231 00000000`00000039
#26dacbbc0 00000000`00000000 00000000`00000000
#26dacbbd0 00000000`00000000 00000000`00000000
#26dacbbe0 00000000`00000000 00000000`00000000
#26dacbbf0 00000000`00000000 00000000`00000000
#26dacbc00 00000000`00000000 00000000`00000000
#26dacbc10 00000000`00000000 00000000`00000000
#26dacbc20 00000000`00000000 00000000`00000000
可以看到内核模式下该物理地址的值和用户模式下虚拟地址的值是一致,欢迎各位同学指正,共同进步。

















 9654
9654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









