




文章目录
前言
新手小白记录第一次刷代码随想录
1.自用 抽取精简的解题思路 方便复盘
2.代码尽量多加注释
3.记录踩坑
4.边刷边记录,更有成就感!
5.解题思路绝大部分来自代码随想录【仅自用 无商用!!!】
深度优先搜索理论基础
代码框架
void dfs(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本节点所连接的其他节点) {
处理节点;
dfs(图,选择的节点); // 递归
回溯,撤销处理结果
}
}
所有可达路径
【题目描述】
给定一个有 n 个节点的有向无环图,节点编号从 1 到 n。请编写一个函数,找出并返回所有从节点 1 到节点 n 的路径。每条路径应以节点编号的列表形式表示。
【输入描述】
第一行包含两个整数 N,M,表示图中拥有 N 个节点,M 条边
后续 M 行,每行包含两个整数 s 和 t,表示图中的 s 节点与 t 节点中有一条路径
【输出描述】
输出所有的可达路径,路径中所有节点的后面跟一个空格,每条路径独占一行,存在多条路径,路径输出的顺序可任意。
如果不存在任何一条路径,则输出 -1。
注意输出的序列中,最后一个节点后面没有空格! 例如正确的答案是 1 3 5,而不是 1 3 5, 5后面没有空格!
【输入示例】
5 5
1 3
3 5
1 2
2 4
4 5
【输出示例】
1 3 5
1 2 4 5
邻接矩阵
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
public class Main {
static List<List<Integer>> result = new ArrayList<>(); // 收集符合条件的路径
static List<Integer> path = new ArrayList<>(); // 1节点到终点的路径
public static void dfs(int[][] graph, int x, int n) {
// 当前遍历的节点x 到达节点n
if (x == n) { // 找到符合条件的一条路径
result.add(new ArrayList<>(path));
return;
}
for (int i = 1; i <= n; i++) { // 遍历节点x链接的所有节点
if (graph[x][i] == 1) { // 找到 x链接的节点
path.add(i); // 遍历到的节点加入到路径中来
dfs(graph, i, n); // 进入下一层递归
path.remove(path.size() - 1); // 回溯,撤销本节点
}
}
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt();
int m = scanner.nextInt();
// 节点编号从1到n,所以申请 n+1 这么大的数组
int[][] graph = new int[n + 1][n + 1];
for (int i = 0; i < m; i++) {
int s = scanner.nextInt();
int t = scanner.nextInt();
// 使用邻接矩阵表示无向图,1 表示 s 与 t 是相连的
graph[s][t] = 1;
}
path.add(1); // 无论什么路径已经是从1节点出发
dfs(graph, 1, n); // 开始遍历
// 输出结果
if (result.isEmpty()) System.out.println(-1);
for (List<Integer> pa : result) {
for (int i = 0; i < pa.size() - 1; i++) {
System.out.print(pa.get(i) + " ");
}
System.out.println(pa.get(pa.size() - 1));
}
}
}
邻接表
import java.util.*;
public class Main {
static List<List<Integer>> res = new ArrayList<>();
static List<Integer> path = new ArrayList<>();
public static void dfs(List<LinkedList<Integer>> graph, int now, int n) {
// 终止条件:找到一条从1到n的路径
if (now == n) {
res.add(new ArrayList<>(path));
return;
}
// 遍历当前节点的所有邻接节点
for (int i : graph.get(now)) {
path.add(i); // 添加当前节点到路径中
dfs(graph, i, n); // 递归探索下一节点
path.remove(path.size() - 1); // 回溯,移除当前节点
}
}
public static void main(String args[]) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt(); // 节点数
int m = sc.nextInt(); // 边数
// 初始化图的邻接表
List<LinkedList<Integer>> graph = new ArrayList<>(n + 1);
for (int i = 0; i <= n; i++) {
graph.add(new LinkedList<>());
}
// 构建图的邻接表
int a, b;
while (m-- > 0) {
a = sc.nextInt();
b = sc.nextInt();
graph.get(a).add(b); // 从a到b的边
}
// 从节点1开始路径搜索
path.add(1); // 初始路径包含节点1
dfs(graph, 1, n);
// 如果没有路径
if (res.isEmpty()) {
System.out.println(-1); // 没有路径
} else {
// 打印所有路径
for (List<Integer> re : res) {
for (int i = 0; i < re.size() - 1; i++) {
System.out.print(re.get(i) + " ");
}
System.out.println(re.get(re.size() - 1)); // 打印路径的最后一个节点
}
}
}
}
岛屿数量
给定一个由 1(陆地)和 0(水)组成的矩阵,你需要计算岛屿的数量。岛屿由水平方向或垂直方向上相邻的陆地连接而成,并且四周都是水域。你可以假设矩阵外均被水包围。
输入描述:
第一行包含两个整数 N, M,表示矩阵的行数和列数。
后续 N 行,每行包含 M 个数字,数字为 1 或者 0。
输出描述:
输出一个整数,表示岛屿的数量。如果不存在岛屿,则输出 0。
输入示例:
4 5
1 1 0 0 0
1 1 0 0 0
0 0 1 0 0
0 0 0 1 1
输出示例:
3
数据范围:
1 <= N, M <= 50
深搜版
import java.util.Scanner;
public class Main {
static int cnt = 0; // 用于计数岛屿数量
static int direct[][] = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}}; // 四个方向的移动
// 深度优先搜索
public static void dfs(int graph[][], int x, int y, boolean visited[][]) {
// 遍历四个方向
for (int i = 0; i < 4; i++) {
int nextX = x + direct[i][0]; // 下一个位置的x坐标
int nextY = y + direct[i][1]; // 下一个位置的y坐标
// 判断是否越界
if (nextX < 0 || nextY < 0 || nextX >= graph.length || nextY >= graph[0].length) {
continue; // 如果越界,跳过
}
// 如果当前位置是陆地并且未访问过,递归搜索
if (!visited[nextX][nextY] && graph[nextX][nextY] == 1) {
visited[nextX][nextY] = true; // 标记为已访问
dfs(graph, nextX, nextY, visited); // 递归搜索
}
}
}
public static void main(String[] args) {
int n, m, a;
Scanner sc = new Scanner(System.in);
n = sc.nextInt(); // 行数
m = sc.nextInt(); // 列数
int[][] graph = new int[n][m]; // 地图
boolean[][] visited = new boolean[n][m]; // 记录每个位置是否已访问
// 读取地图
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
a = sc.nextInt();
graph[i][j] = a; // 1表示陆地,0表示水域
}
}
// 遍历整个图,每当找到一个未访问的陆地,执行深度优先搜索
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
// 找到一个未访问的陆地,开始深度优先搜索
if (!visited[i][j] && graph[i][j] == 1) {
cnt++; // 找到一个岛屿
visited[i][j] = true; // 标记为已访问
dfs(graph, i, j, visited); // 递归搜索整个岛屿
}
}
}
// 输出岛屿的数量
System.out.println(cnt);
}
}
另一种写终止条件的写法
public static void dfs(int[][] grid, boolean[][] visited, int x, int y) {
// 终止条件:访问过的节点 或者 遇到海水(grid[x][y] == 0)
if (visited[x][y] || grid[x][y] == 0) {
return;
}
visited[x][y] = true; // 标记当前位置为已访问
// 遍历四个方向
for (int i = 0; i < 4; i++) {
int nextX = x + dir[i][0];
int nextY = y + dir[i][1];
// 检查是否越界
if (nextX < 0 || nextX >= grid.length || nextY < 0 || nextY >= grid[0].length) {
continue;
}
// 递归调用 DFS
dfs(grid, visited, nextX, nextY);
}
}
广搜版
- 不少同学用广搜做这道题目的时候,超时了。 这里有一个广搜中很重要的细节:
- 根本原因是只要 加入队列就代表 走过,就需要标记,而不是从队列拿出来的时候再去标记走过。
- 很多同学可能感觉这有区别吗?
- 如果从队列拿出节点,再去标记这个节点走过,就会发生下图所示的结果,会导致很多节点重复加入队列。

import java.util.*;
public class Main {
// 定义四个方向的偏移量:下、右、上、左
public static int[][] dir = {{0, 1}, {1, 0}, {0, -1}, {-1, 0}};// 下右上左
// 自定义pair类,用于存储坐标
static class pair {
int first, second;
pair(int x, int y) {
this.first = x;
this.second = y;
}
}
// BFS遍历函数
public static void bfs(int[][] grid, boolean[][] visited, int x, int y) {
Queue<pair> queue = new LinkedList<pair>(); // 定义坐标队列
queue.add(new pair(x, y)); // 入队当前坐标
visited[x][y] = true; // 标记当前位置为已访问
while (!queue.isEmpty()) {
int curX = queue.peek().first; // 获取队列头的X坐标
int curY = queue.poll().second; // 获取队列头的Y坐标并出队(poll是把对头元素出队了)
// 遍历四个方向
for (int i = 0; i < 4; i++) {
// 计算下一个坐标
int nextX = curX + dir[i][0];
int nextY = curY + dir[i][1];
// 检查越界
if (nextX < 0 || nextX >= grid.length || nextY < 0 || nextY >= grid[0].length) {
continue;
}
// 如果没有访问过并且该点是陆地(值为1),则入队
if (!visited[nextX][nextY] && grid[nextX][nextY] == 1) {
queue.add(new pair(nextX, nextY));
visited[nextX][nextY] = true; // 标记为已访问
}
}
}
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
// 输入网格的行数和列数
int m = sc.nextInt();
int n = sc.nextInt();
int[][] grid = new int[m][n];
boolean[][] visited = new boolean[m][n];
int ans = 0;
// 输入网格的每个值(0为水域,1为陆地)
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
grid[i][j] = sc.nextInt();
}
}
// 遍历网格,查找所有的岛屿
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
// 如果该点是陆地并且未访问过,则说明发现一个新的岛屿
if (!visited[i][j] && grid[i][j] == 1) {
ans++; // 岛屿数量加一
bfs(grid, visited, i, j); // 通过BFS将该岛屿所有的陆地标记为已访问
}
}
}
// 输出岛屿数量
System.out.println(ans);
}
}
岛屿最大面积
题目描述
给定一个由 1(陆地)和 0(水)组成的矩阵,计算岛屿的最大面积。岛屿面积的计算方式为组成岛屿的陆地的总数。岛屿由水平方向或垂直方向上相邻的陆地连接而成,并且四周都是水域。你可以假设矩阵外均被水包围。
输入描述
第一行包含两个整数 N, M,表示矩阵的行数和列数。后续 N 行,每行包含 M 个数字,数字为 1 或者 0,表示岛屿的单元格。
输出描述
输出一个整数,表示岛屿的最大面积。如果不存在岛屿,则输出 0。
输入示例
4 5
1 1 0 0 0
1 1 0 0 0
0 0 1 0 0
0 0 0 1 1
输出示例
4
写在前面
- count是类成员变量,如果不加 static,它们将被视为实例变量,只有通过实例化 Main 类才能访问它们。
- bfs 方法是静态方法,它可以直接通过类名 Main.bfs() 调用。如果不将其设为 static,它就需要依赖于一个 Main 类的实例来调用。
- 如果不加 static,访问count 以及调用 bfs 会出现问题,因为:count 是实例变量,而 bfs 是静态方法。静态方法只能访问静态变量和静态方法。
- 即使你没有实例化 Main 类,你也希望在 main 方法中访问它们,这就要求count 也必须是静态的。
dfs
写法一,dfs只处理下一个节点,即在主函数遇到岛屿就计数为1,dfs处理接下来的相邻陆地
import java.util.*;
public class Main {
// 定义四个方向的偏移量:右、下、左、上
public static int[][] dir = {{0, 1}, {1, 0}, {0, -1}, {-1, 0}};
static int count; // 记录每次DFS访问的陆地数量
// 深度优先搜索 (DFS) 函数
public static void dfs(int[][] grid, boolean[][] visited, int x, int y) {
for (int i = 0; i < 4; i++) {
int nextX = x + dir[i][0];
int nextY = y + dir[i][1];
// 检查越界
if (nextX < 0 || nextX >= grid.length || nextY < 0 || nextY >= grid[0].length) {
continue;
}
// 如果该位置没有访问过且是陆地,则继续DFS
if (!visited[nextX][nextY] && grid[nextX][nextY] == 1) {
visited[nextX][nextY] = true;
count++; // 增加当前岛屿的陆地数量
dfs(grid, visited, nextX, nextY); // 递归访问相邻的陆地
}
}
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
// 输入网格的行数n和列数m
int n = sc.nextInt();
int m = sc.nextInt();
// 创建网格并填充输入数据
int[][] grid = new int[n][m];
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
grid[i][j] = sc.nextInt();
}
}
// 创建一个visited数组,用来标记访问过的位置
boolean[][] visited = new boolean[n][m];
int result = 0; // 最终记录最大岛屿面积
// 遍历每一个格子
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
// 如果当前格子是陆地并且未被访问过,进行DFS
if (!visited[i][j] && grid[i][j] == 1) {
count = 1; // 这里遇到陆地了,先计数1
visited[i][j] = true;
dfs(grid, visited, i, j); // 递归访问与当前陆地相连的陆地
result = Math.max(result, count); // 更新最大岛屿面积
}
}
}
// 输出结果
System.out.println(result);
}
}
写法二,dfs处理当前节点,即在主函数遇到岛屿就计数为0,dfs处理接下来的全部陆地
// 版本二
import java.util.Scanner;
public class Main {
// 定义四个方向的偏移量:右、下、左、上
public static int[][] dir = {{0, 1}, {1, 0}, {0, -1}, {-1, 0}};
static int count; // 记录每次DFS访问的陆地数量
// 深度优先搜索 (DFS) 函数
public static void dfs(int[][] grid, boolean[][] visited, int x, int y) {
// 终止条件:访问过的节点 或者 遇到海水
if (visited[x][y] || grid[x][y] == 0) return;
visited[x][y] = true; // 标记当前位置为已访问
count++; // 每访问到一个陆地,计数+1
// 遍历四个方向
for (int i = 0; i < 4; i++) {
int nextX = x + dir[i][0];
int nextY = y + dir[i][1];
// 检查越界
if (nextX < 0 || nextX >= grid.length || nextY < 0 || nextY >= grid[0].length) {
continue;
}
// 递归调用 DFS
dfs(grid, visited, nextX, nextY);
}
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
// 输入网格的行数n和列数m
int n = sc.nextInt();
int m = sc.nextInt();
// 创建网格并填充输入数据
int[][] grid = new int[n][m];
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
grid[i][j] = sc.nextInt();
}
}
// 创建一个visited数组,用来标记访问过的位置
boolean[][] visited = new boolean[n][m];
int result = 0; // 最终记录最大岛屿面积
// 遍历每一个格子
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
// 如果当前格子是陆地并且未被访问过,进行DFS
if (!visited[i][j] && grid[i][j] == 1) {
count = 0; // 遇到陆地时先计数为0,进入DFS后开始从1计数
dfs(grid, visited, i, j); // 递归访问与当前陆地相连的陆地
result = Math.max(result, count); // 更新最大岛屿面积
}
}
}
// 输出结果
System.out.println(result);
}
}
大家通过注释可以发现,两种写法,版本一,在主函数遇到陆地就计数为1,接下来的相邻陆地都在dfs中计算。
版本二 在主函数遇到陆地 计数为0,也就是不计数,陆地数量都去dfs里做计算。
bfs的代码省略
孤岛的总面积
目描述
给定一个由 1(陆地)和 0(水)组成的矩阵,岛屿指的是由水平或垂直方向上相邻的陆地单元格组成的区域,且完全被水域单元格包围。孤岛是那些位于矩阵内部、所有单元格都不接触边缘的岛屿。
现在你需要计算所有孤岛的总面积,岛屿面积的计算方式为组成岛屿的陆地的总数。
输入描述
第一行包含两个整数 N, M,表示矩阵的行数和列数。之后 N 行,每行包含 M 个数字,数字为 1 或者 0。
输出描述
输出一个整数,表示所有孤岛的总面积,如果不存在孤岛,则输出 0。
输入示例
4 5
1 1 0 0 0
1 1 0 0 0
0 0 1 0 0
0 0 0 1 1
输出示例:
import java.util.*;
public class Main {
private static int count = 0;
private static final int[][] dir = {{0, 1}, {1, 0}, {-1, 0}, {0, -1}}; // 四个方向
private static void bfs(int[][] grid, int x, int y) {
Queue<int[]> que = new LinkedList<>();
que.add(new int[]{x, y});
grid[x][y] = 0; // 只要加入队列,立刻标记
count++;
while (!que.isEmpty()) {
int[] cur = que.poll();
int curx = cur[0];
int cury = cur[1];
for (int i = 0; i < 4; i++) {
int nextx = curx + dir[i][0];
int nexty = cury + dir[i][1];
if (nextx < 0 || nextx >= grid.length || nexty < 0 || nexty >= grid[0].length) continue; // 越界了,直接跳过
if (grid[nextx][nexty] == 1) {
que.add(new int[]{nextx, nexty});
count++;
grid[nextx][nexty] = 0; // 只要加入队列立刻标记
}
}
}
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt();
int m = scanner.nextInt();
int[][] grid = new int[n][m];
// 读取网格
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
grid[i][j] = scanner.nextInt();
}
}
// 从左侧边,和右侧边向中间遍历
for (int i = 0; i < n; i++) {
if (grid[i][0] == 1) bfs(grid, i, 0);
if (grid[i][m - 1] == 1) bfs(grid, i, m - 1);
}
// 从上边和下边向中间遍历
for (int j = 0; j < m; j++) {
if (grid[0][j] == 1) bfs(grid, 0, j);
if (grid[n - 1][j] == 1) bfs(grid, n - 1, j);
}
count = 0;
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
if (grid[i][j] == 1) bfs(grid, i, j);
}
}
System.out.println(count);
}
}
沉没孤岛
题目描述:
给定一个由 1(陆地)和 0(水)组成的矩阵,岛屿指的是由水平或垂直方向上相邻的陆地单元格组成的区域,且完全被水域单元格包围。孤岛是那些位于矩阵内部、所有单元格都不接触边缘的岛屿。
现在你需要将所有孤岛“沉没”,即将孤岛中的所有陆地单元格(1)转变为水域单元格(0)。
输入描述:
第一行包含两个整数 N, M,表示矩阵的行数和列数。
之后 N 行,每行包含 M 个数字,数字为 1 或者 0,表示岛屿的单元格。
输出描述
输出将孤岛“沉没”之后的岛屿矩阵。
输入示例:
4 5
1 1 0 0 0
1 1 0 0 0
0 0 1 0 0
0 0 0 1 1
输出示例:
1 1 0 0 0
1 1 0 0 0
0 0 0 0 0
0 0 0 1 1
思路
1.从边界遍历 把接壤陆地的岛屿标记为2
2. 再遍历一遍 把孤岛变为0
3. 最后再遍历一遍 把孤岛变为2
import java.util.Scanner;
public class Main{
static int[][] dir = { {-1, 0}, {0, -1}, {1, 0}, {0, 1} }; // 保存四个方向
public static int n,m;
public static void dfs(int grid[][],int x,int y){
grid[x][y]=2;
for(int i=0;i<4;i++){
int nextX=x+dir[i][0];
int nextY=y+dir[i][1];
if(nextY<0||nextY>=m||nextX<0||nextX>=n) continue;//这里是continue 不是return
if (grid[nextX][nextY] == 0 || grid[nextX][nextY] == 2) continue;
dfs(grid,nextX,nextY);
}
}
public static void main (String[] args) {
Scanner scanner = new Scanner(System.in);
n = scanner.nextInt();
m = scanner.nextInt();
int[][] grid = new int[n][m];
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
grid[i][j] = scanner.nextInt();
}
}
//从左右向中间便利 把半岛变为2
for(int i=0;i<n;i++){
if(grid[i][0]==1) dfs(grid,i,0);
if(grid[i][m-1]==1) dfs(grid,i,m-1);
}
//从上下 向中间便利 把半岛变为2
for(int i=0;i<m;i++){
if(grid[0][i]==1) dfs(grid,0,i);
if(grid[n-1][i]==1) dfs(grid,n-1,i);
}
//把孤岛变为0 把半岛变回1
for(int i=0;i<n;i++){
for(int j=0;j<m;j++){
if(grid[i][j]==1) grid[i][j]=0;
if(grid[i][j]==2) grid[i][j]=1;
System.out.print(grid[i][j] + " ");
}
System.out.println();
}
scanner.close();
}
}
水流问题
【题目描述】:
现有一个 N × M 的矩阵,每个单元格包含一个数值,这个数值代表该位置的相对高度。矩阵的左边界和上边界被认为是第一组边界,而矩阵的右边界和下边界被视为第二组边界。
矩阵模拟了一个地形,当雨水落在上面时,水会根据地形的倾斜向低处流动,但只能从较高或等高的地点流向较低或等高并且相邻(上下左右方向)的地点。我们的目标是确定那些单元格,从这些单元格出发的水可以达到第一组边界和第二组边界。
【输入描述】:
第一行包含两个整数 N 和 M,分别表示矩阵的行数和列数。
后续 N 行,每行包含 M 个整数,表示矩阵中的每个单元格的高度。
【输出描述】:
输出共有多行,每行输出两个整数,用一个空格隔开,表示可达第一组边界和第二组边界的单元格的坐标,输出顺序任意。
【输入示例】:
5 5
1 3 1 2 4
1 2 1 3 2
2 4 7 2 1
4 5 6 1 1
1 4 1 2 1
【输出示例】:
0 4
1 3
2 2
3 0
3 1
3 2
4 0
4 1
【提示信息】:

图中的蓝色方块上的雨水既能流向第一组边界,也能流向第二组边界。所以最终答案为所有蓝色方块的坐标。
【数据范围】:
1 <= M, N <= 50
思路
那么我们可以 反过来想,从第一组边界上的节点 逆流而上,将遍历过的节点都标记上。
同样从第二组边界的边上节点 逆流而上,将遍历过的节点也标记上。
然后两方都标记过的节点就是所求。
import java.util.Scanner;
public class Main {
// 定义四个方向
public static int[][] dir = { {-1, 0}, {0, -1}, {1, 0}, {0, 1} };
// DFS搜索函数
public static void dfs(int[][] heights, int x, int y, boolean[][] visited) {
// 如果已经访问过,则返回
if (visited[x][y]) return;
// 标记为已访问
visited[x][y] = true;
// 遍历四个方向
for (int i = 0; i < 4; i++) {
int nextx = x + dir[i][0];
int nexty = y + dir[i][1];
// 判断边界
if (nextx < 0 || nextx >= heights.length || nexty < 0 || nexty >= heights[0].length) continue;
// 判断是否可以流动(水只能从低向高流动)
if (heights[x][y] > heights[nextx][nexty]) continue;
// 递归调用DFS
dfs(heights, nextx, nexty, visited);
}
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int m = sc.nextInt(); // 行数
int n = sc.nextInt(); // 列数
// 读取矩阵
int[][] heights = new int[m][n];
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
heights[i][j] = sc.nextInt();
}
}
// 初始化两个boolean数组,代表两个边界
boolean[][] border1 = new boolean[m][n]; // 第一个边界
boolean[][] border2 = new boolean[m][n]; // 第二个边界
// 从上下边界开始DFS
for (int i = 0; i < n; i++) {
dfs(heights, 0, i, border1); // 从上边界开始
dfs(heights, m - 1, i, border2); // 从下边界开始
}
// 从左右边界开始DFS
for (int i = 0; i < m; i++) {
dfs(heights, i, 0, border1); // 从左边界开始
dfs(heights, i, n - 1, border2); // 从右边界开始
}
// 输出符合条件的坐标
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
// 如果该位置能同时从两个边界到达
if (border1[i][j] && border2[i][j]) {
System.out.println(i + " " + j);
}
}
}
sc.close();
}
}
建造最大人工岛
【题目描述】:
给定一个由 1(陆地)和 0(水)组成的矩阵,你最多可以将矩阵中的一格水变为一块陆地,在执行了此操作之后,矩阵中最大的岛屿面积是多少。
岛屿面积的计算方式为组成岛屿的陆地的总数。岛屿是被水包围,并且通过水平方向或垂直方向上相邻的陆地连接而成的。你可以假设矩阵外均被水包围。
【输入描述】:
第一行包含两个整数 N, M,表示矩阵的行数和列数。之后 N 行,每行包含 M 个数字,数字为 1 或者 0,表示岛屿的单元格。
【输出描述】:
输出一个整数,表示最大的岛屿面积。
【输入示例】:
4 5
1 1 0 0 0
1 1 0 0 0
0 0 1 0 0
0 0 0 1 1
【输出示例】
6
思路
- 用Map来记录岛屿的面积,key为岛屿编号,value为岛屿面积。
- 然后再遍历一遍海洋,比较当哪一块海洋变为陆地的时候,周边相邻的岛屿面积最大。
public class Main {
// 该方法采用 DFS
// 定义全局变量
// 记录每次每个岛屿的面积
static int count;
// 对每个岛屿进行标记
static int mark;
// 定义二维数组表示四个方位
static int[][] dirs = {{0, 1}, {0, -1}, {1, 0}, {-1, 0}};
// DFS 进行搜索,将每个岛屿标记为不同的数字
public static void dfs(int[][] grid, int x, int y, boolean[][] visited) {
// 当遇到边界,直接return
if (x < 0 || x >= grid.length || y < 0 || y >= grid[0].length) return;
// 遇到已经访问过的或者遇到海水,直接返回
if (visited[x][y] || grid[x][y] == 0) return;
visited[x][y] = true;
count++;
grid[x][y] = mark;
// 继续向下层搜索
dfs(grid, x, y + 1, visited);
dfs(grid, x, y - 1, visited);
dfs(grid, x + 1, y, visited);
dfs(grid, x - 1, y, visited);
}
public static void main (String[] args) {
// 接收输入
Scanner sc = new Scanner(System.in);
int m = sc.nextInt();
int n = sc.nextInt();
int[][] grid = new int[m][n];
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
grid[i][j] = sc.nextInt();
}
}
// 初始化mark变量,从2开始(区别于0水,1岛屿)
mark = 2;
// 定义二位boolean数组记录该位置是否被访问
boolean[][] visited = new boolean[m][n];
// 定义一个HashMap,记录某片岛屿的标记号和面积
HashMap<Integer, Integer> getSize = new HashMap<>();
// 定义一个HashSet,用来判断某一位置水四周是否存在不同标记编号的岛屿
HashSet<Integer> set = new HashSet<>();
// 定义一个boolean变量,看看DFS之后,是否全是岛屿
boolean isAllIsland = true;
// 遍历二维数组进行DFS搜索,标记每片岛屿的编号,记录对应的面积
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (grid[i][j] == 0) isAllIsland = false;
if (grid[i][j] == 1) {
count = 0;
dfs(grid, i, j, visited);
getSize.put(mark, count);
mark++;
}
}
}
int result = 0;
if (isAllIsland) result = m * n;
// 对标记完的grid继续遍历,判断每个水位置四周是否有岛屿,并记录下四周不同相邻岛屿面积之和
// 每次计算完一个水位置周围可能存在的岛屿面积之和,更新下result变量
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (grid[i][j] == 0) {
set.clear();
// 当前水位置变更为岛屿,所以初始化为1
int curSize = 1;
for (int[] dir : dirs) {
int curRow = i + dir[0];
int curCol = j + dir[1];
if (curRow < 0 || curRow >= m || curCol < 0 || curCol >= n) continue;
int curMark = grid[curRow][curCol];
// 如果当前相邻的岛屿已经遍历过或者HashMap中不存在这个编号,继续搜索
if (set.contains(curMark) || !getSize.containsKey(curMark)) continue;
set.add(curMark);
curSize += getSize.get(curMark);
}
result = Math.max(result, curSize);
}
}
}
// 打印结果
System.out.println(result);
}
}
字符串接龙
【题目描述】
字典 strList 中从字符串 beginStr 和 endStr 的转换序列是一个按下述规格形成的序列:
序列中第一个字符串是 beginStr。
序列中最后一个字符串是 endStr。
每次转换只能改变一个字符。
转换过程中的中间字符串必须是字典 strList 中的字符串。
给你两个字符串 beginStr 和 endStr 和一个字典 strList,找到从 beginStr 到 endStr 的最短转换序列中的字符串数目。如果不存在这样的转换序列,返回 0。
【输入描述】
第一行包含一个整数 N,表示字典 strList 中的字符串数量。 第二行包含两个字符串,用空格隔开,分别代表 beginStr 和 endStr。 后续 N 行,每行一个字符串,代表 strList 中的字符串。
【输出描述】
输出一个整数,代表从 beginStr 转换到 endStr 需要的最短转换序列中的字符串数量。如果不存在这样的转换序列,则输出 0。
【输入示例】
6
abc def
efc
dbc
ebc
dec
dfc
yhn
【输出示例】
4
提示信息
从 startStr 到 endStr,在 strList 中最短的路径为 abc -> dbc -> dec -> def,所以输出结果为 4
数据范围:
2 <= N <= 500
思路
以示例1为例,从这个图中可以看出 abc 到 def的路线 不止一条,但最短的一条路径上是4个节点。

本题只需要求出最短路径的长度就可以了,不用找出具体路径。
所以这道题要解决两个问题:
图中的线是如何连在一起的
起点和终点的最短路径长度
首先题目中并没有给出点与点之间的连线,而是要我们自己去连,条件是字符只能差一个。
所以判断点与点之间的关系,需要判断是不是差一个字符,如果差一个字符,那就是有链接。
然后就是求起点和终点的最短路径长度,这里无向图求最短路,广搜最为合适,广搜只要搜到了终点,那么一定是最短的路径。因为广搜就是以起点中心向四周扩散的搜索。
本题如果用深搜,会比较麻烦,要在到达终点的不同路径中选则一条最短路。 而广搜只要达到终点,一定是最短路。
广搜的逐层扩展特性
- BFS 从起点开始,将所有与起点直接相连的节点加入到第一层队列,然后从第一层队列中的节点依次扩展到下一层。
- 换句话说,BFS 按距离的顺序逐层扩展:先处理与起点距离为 1 的节点,然后是距离为 2 的节点,依此类推。
最先访问到某节点时路径必然最短
- 对于无权图,每条边的代价是相同的(等于 1)。因此,从起点扩展到某个节点的路径长度直接对应 BFS 的层数。
- 当 BFS 搜索到某个节点时,这是第一次到达该节点,且此时路径长度必然是最短的。
- 一旦到达终点(目标节点),BFS 会立即返回路径长度,因为广搜的特性保证了这是首次到达终点,也即最短路径。
与深搜的对比
- 深度优先搜索(DFS)沿着一条路径深入探索,可能需要遍历完整张图后才能找到所有路径,然后再从中比较出最短路径。
注意:
本题是一个无向图,需要用标记位,标记着节点是否走过,否则就会死循环!(visitMap 可以同时记录路径长度)
使用set来检查字符串是否出现在字符串集合里更快一些
import java.util.*;
public class Main {
public static int ladderLength(String beginWord,String endWord,List<String>strList){
//用ste来查询你换的每个字符串在不在字典strList中
HashSet<String> set = new HashSet<>(strList);
//bfs所以需要一个队列
//存储每次变更一个字符得到的且存在容器中的新字符
Queue<String> queue = new LinkedList<>();
//用hashMap存储遍历到的字符串以及所走过的路径
HashMap<String,Integer> visitMap = new HashMap<>();
queue.offer(beginWord);
visitMap.put(beginWord,1);
while(!queue.isEmpty()){
String curWord = queue.poll();
int path=visitMap.get(curWord);
for(int i=0;i<curWord.length();i++){
char[] ch =curWord.toCharArray();
//每个位置尝试26个字母
for(char k ='a';k<='z';k++){
ch[i]=k;
String newWord=new String(ch);
if(newWord.equals(endWord)) return path+1;
//如果这个字符 存在于strLust字典中
//并且还没有被访问到
if(set.contains(newWord)&&!visitMap.containsKey(newWord)){
visitMap.put(newWord,path+1);
queue.offer(newWord);
}
}
}
}
return 0;
}
public static void main (String[] args) {
Scanner sc = new Scanner(System.in);
int N = sc.nextInt();
sc.nextLine(); //接收的是换行符?
String[] strs = sc.nextLine().split(" "); //放入beginStr 和 endStr
List<String> strList = new ArrayList<>();//输入字典strList
for (int i = 0; i < N; i++) {
strList.add(sc.nextLine());
}
int result = ladderLength(strs[0], strs[1], strList);
System.out.println(result);
}
}
有向图的完全可达性
【题目描述】
给定一个有向图,包含 N 个节点,节点编号分别为 1,2,…,N。现从 1 号节点开始,如果可以从 1 号节点的边可以到达任何节点,则输出 1,否则输出 -1。
【输入描述】
第一行包含两个正整数,表示节点数量 N 和边的数量 K。 后续 K 行,每行两个正整数 s 和 t,表示从 s 节点有一条边单向连接到 t 节点。
【输出描述】
如果可以从 1 号节点的边可以到达任何节点,则输出 1,否则输出 -1。
【输入示例】
4 4
1 2
2 1
1 3
2 4
【输出示例】
1
思路
所以本题是一个有向图搜索全路径的问题。 只能用深搜(DFS)或者广搜(BFS)来搜。
用邻接矩阵还是邻接表?
邻接表。因为邻接表可以直观地表示每个节点的出边集合。
以下dfs分析 大家一定要仔细看,本题有两种dfs的解法。
深搜三部曲:
1.确认递归函数,参数
需要传入地图,需要知道当前我们拿到的key,以至于去下一个房间。
同时还需要一个数组,用来记录我们都走过了哪些房间,这样好知道最后有没有把所有房间都遍历的,可以定义一个一维数组。
所以 递归函数参数如下:
// key 当前得到的可以
// visited 记录访问过的房间
void dfs(const vector<list<int>>& graph, int key, vector<bool>& visited) {
2.确认终止条件
遍历的时候,什么时候终止呢?
这里有一个很重要的逻辑,就是在递归中,我们是处理当前访问的节点,还是处理下一个要访问的节点。
这决定 终止条件怎么写。
首先明确,本题中什么叫做处理,就是 visited数组来记录访问过的节点,该节点默认 数组里元素都是false,把元素标记为true就是处理 本节点了。
如果我们是处理当前访问的节点,当前访问的节点如果是 true ,说明是访问过的节点,那就终止本层递归,如果不是true,我们就把它赋值为true,因为这是我们处理本层递归的节点。
代码就是这样:
写法一:处理当前访问的节点
在处理当前节点时标记为已访问:
import java.util.*;
public class Main {
public static void dfs(List<List<Integer>> graph, int key, boolean[] visited) {
if (visited[key]) {
return;
}
visited[key] = true; // 标记当前节点已访问
List<Integer> neighbors = graph.get(key);
for (int neighbor : neighbors) {
dfs(graph, neighbor, visited); // 继续递归
}
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt(); // 节点数
int m = scanner.nextInt(); // 边数
List<List<Integer>> graph = new ArrayList<>();
for (int i = 0; i <= n; i++) {
graph.add(new ArrayList<>());
}
for (int i = 0; i < m; i++) {
int s = scanner.nextInt();
int t = scanner.nextInt();
graph.get(s).add(t); // 构建邻接表
}
boolean[] visited = new boolean[n + 1];
dfs(graph, 1, visited);
for (int i = 1; i <= n; i++) {
if (!visited[i]) {
System.out.println(-1);
return;
}
}
System.out.println(1);
}
}
写法二:处理下一个要访问的节点
在遍历当前节点的邻接节点时直接判断并标记下一个节点:
import java.util.*;
public class Main {
public static void dfs(List<List<Integer>> graph, int key, boolean[] visited) {
List<Integer> neighbors = graph.get(key);
for (int neighbor : neighbors) {
if (!visited[neighbor]) { // 如果未访问
visited[neighbor] = true; // 立即标记
dfs(graph, neighbor, visited); // 继续递归
}
}
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt(); // 节点数
int m = scanner.nextInt(); // 边数
List<List<Integer>> graph = new ArrayList<>();
for (int i = 0; i <= n; i++) {
graph.add(new ArrayList<>());
}
for (int i = 0; i < m; i++) {
int s = scanner.nextInt();
int t = scanner.nextInt();
graph.get(s).add(t); // 构建邻接表
}
boolean[] visited = new boolean[n + 1];
visited[1] = true; // 预先标记起点为访问
dfs(graph, 1, visited);
for (int i = 1; i <= n; i++) {
if (!visited[i]) {
System.out.println(-1);
return;
}
}
System.out.println(1);
}
}
可以看出,如何看待 我们要访问的节点,直接决定了两种不一样的写法,很多录友对这一块很模糊,可能做过这道题,但没有思考到这个维度上。
处理目前搜索节点出发的路径
其实在上面,深搜三部曲 第二部,就已经讲了,因为终止条件的两种写法, 直接决定了两种不一样的递归写法。
这里还有细节:
看上面两个版本的写法中, 好像没有发现回溯的逻辑。
我们都知道,有递归就有回溯,回溯就在递归函数的下面, 那么之前我们做的dfs题目,都需要回溯操作, 为什么本题就没有回溯呢?
代码中可以看到dfs函数下面并没有回溯的操作。
此时就要在思考本题的要求了,本题是需要判断 1节点 是否能到所有节点,那么我们就没有必要回溯去撤销操作了,只要遍历过的节点一律都标记上。
那什么时候需要回溯操作呢?
当我们需要搜索一条可行路径的时候,就需要回溯操作了,因为没有回溯,就没法“调头”, 如果不理解的话,去看我写的 0098.所有可达路径 的题解。
import java.util.*;
public class Main {
public static List<List<Integer>> adjList = new ArrayList<>();
// 深度优先搜索
public static void dfs(boolean[] visited, int key) {
if (visited[key]) return;
visited[key] = true;
List<Integer> neighbors = adjList.get(key);
for (int neighbor : neighbors) {
dfs(visited, neighbor);
}
}
// 广度优先搜索
public static void bfs(boolean[] visited, int key) {
Queue<Integer> que = new LinkedList<>(); // 注意正确实例化 Queue
que.add(key);
visited[key] = true;
while (!que.isEmpty()) {
int now = que.poll();
List<Integer> neighbors = adjList.get(now);
for (int neighbor : neighbors) {
if (!visited[neighbor]) {
visited[neighbor] = true;
que.add(neighbor);
}
}
}
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int vertices_num = sc.nextInt(); // 节点数量
int line_num = sc.nextInt(); // 边数量
// 初始化邻接表
for (int i = 0; i <= vertices_num; i++) { // 节点编号从 1 开始,预留 0 位置
adjList.add(new LinkedList<>());
}
// 构造邻接表
for (int i = 0; i < line_num; i++) {
int s = sc.nextInt();
int t = sc.nextInt();
adjList.get(s).add(t);
}
// 检查连通性
boolean[] visited = new boolean[vertices_num + 1];
// bfs(visited, 1); // 可以切换为
dfs(visited, 1);
// 判断所有节点是否可达
for (int i = 1; i <= vertices_num; i++) { // 从 1 开始检查
if (!visited[i]) {
System.out.println(-1);
return;
}
}
System.out.println(1);
}
}
岛屿的周长
【题目描述】
给定一个由 1(陆地)和 0(水)组成的矩阵,岛屿是被水包围,并且通过水平方向或垂直方向上相邻的陆地连接而成的。
你可以假设矩阵外均被水包围。在矩阵中恰好拥有一个岛屿,假设组成岛屿的陆地边长都为 1,请计算岛屿的周长。岛屿内部没有水域。
【输入描述】
第一行包含两个整数 N, M,表示矩阵的行数和列数。之后 N 行,每行包含 M 个数字,数字为 1 或者 0,表示岛屿的单元格。
【输出描述】
输出一个整数,表示岛屿的周长。
【输入示例】
5 5
0 0 0 0 0
0 1 0 1 0
0 1 1 1 0
0 1 1 1 0
0 0 0 0 0
【输出示例】
14
思路
岛屿问题最容易让人想到BFS或者DFS,但本题确实还用不上。
遍历每一个空格,遇到岛屿则计算其上下左右的空格情况。
如果该陆地上下左右的空格是有水域,则说明是一条边,如图:
import java.util.*;
public class Main {
// 每次遍历到1,探索其周围4个方向,并记录周长,最终合计
// 声明全局变量,dirs表示4个方向
static int[][] dirs = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}};
// 统计每单个1的周长
static int count;
// 探索其周围4个方向,并记录周长
public static void helper(int[][] grid, int x, int y) {
for (int[] dir : dirs) {
int nx = x + dir[0];
int ny = y + dir[1];
// 遇到边界或者水,周长加一
if (nx < 0 || nx >= grid.length || ny < 0 || ny >= grid[0].length
|| grid[nx][ny] == 0) {
count++;
}
}
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
// 接收输入
int M = sc.nextInt();
int N = sc.nextInt();
int[][] grid = new int[M][N];
for (int i = 0; i < M; i++) {
for (int j = 0; j < N; j++) {
grid[i][j] = sc.nextInt();
}
}
int result = 0; // 总周长
for (int i = 0; i < M; i++) {
for (int j = 0; j < N; j++) {
if (grid[i][j] == 1) {
count = 0;
helper(grid, i, j);
// 更新总周长
result += count;
}
}
}
// 打印结果
System.out.println(result);
}
}
寻找存在的路径
【题目描述】
给定一个包含 n 个节点的无向图中,节点编号从 1 到 n (含 1 和 n )。
你的任务是判断是否有一条从节点 source 出发到节点 destination 的路径存在。
【输入描述】
第一行包含两个正整数 N 和 M,N 代表节点的个数,M 代表边的个数。
后续 M 行,每行两个正整数 s 和 t,代表从节点 s 与节点 t 之间有一条边。
最后一行包含两个正整数,代表起始节点 source 和目标节点 destination。
【输出描述】
输出一个整数,代表是否存在从节点 source 到节点 destination 的路径。如果存在,输出 1;否则,输出 0。
【输入示例】
5 4
1 2
1 3
2 4
3 4
1 4
【输出示例】
1
import java.util.*;
public class Main {
public static void main(String[] args) {
int N, M;
Scanner scanner = new Scanner(System.in);
N = scanner.nextInt();
M = scanner.nextInt();
DisJoint disJoint = new DisJoint(N + 1);
for (int i = 0; i < M; ++i) {
disJoint.join(scanner.nextInt(), scanner.nextInt());
}
if(disJoint.isSame(scanner.nextInt(), scanner.nextInt())) {
System.out.println("1");
} else {
System.out.println("0");
}
}
}
// 并查集模板
class DisJoint {
private int[] parent;
// 构造函数
public DisJoint(int n) {
parent = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i; // 初始化时每个元素的父节点是自己
}
}
// 查找根节点,并做路径压缩
public int find(int n) {
if (parent[n] != n) {
parent[n] = find(parent[n]); // 路径压缩
}
return parent[n];
}
// 判断两个元素是否在同一集合
public boolean isSame(int n, int m) {
return find(n) == find(m); // 如果根节点相同,则属于同一集合
}
// 合并两个集合
public void join(int n, int m) {
int rootN = find(n);
int rootM = find(m);
if (rootN != rootM) {
parent[rootN] = rootM; // 将rootN的根节点连接到rootM
}
}
}
冗余连接
题目描述
有一个图,它是一棵树,他是拥有 n 个节点(节点编号1到n)和 n - 1 条边的连通无环无向图(其实就是一个线形图),如图:

现在在这棵树上的基础上,添加一条边(依然是n个节点,但有n条边),使这个图变成了有环图,如图

先请你找出冗余边,删除后,使该图可以重新变成一棵树。
输入描述
第一行包含一个整数 N,表示图的节点个数和边的个数。
后续 N 行,每行包含两个整数 s 和 t,表示图中 s 和 t 之间有一条边。
输出描述
输出一条可以删除的边。如果有多个答案,请删除标准输入中最后出现的那条边。
输入示例
3
1 2
2 3
1 3
输出示例
1 3
图中的 1 2,2 3,1 3 等三条边在删除后都能使原图变为一棵合法的树。但是 1 3 由于是标准输出里最后出现的那条边,所以输出结果为 1 3
思路
那么我们就可以从前向后遍历每一条边(因为优先让前面的边连上),边的两个节点如果不在同一个集合,就加入集合(即:同一个根节点)。
如果边的两个节点已经出现在同一个集合里,说明着边的两个节点已经连在一起了,再加入这条边一定就出现环了。
题目要求 “请删除标准输入中最后出现的那条边” ,这代码分明是遇到在同一个根的两个节点立刻就返回了,怎么就求出 最后出现的那条边 了呢。
有这种疑惑的录友是 认为发现一条冗余边后,后面还可能会有一条冗余边。其实并不会。
题目是在 树的基础上 添加一条边,所以冗余边仅仅是一条。到这一条可能靠前出现,可能靠后出现。
import java.util.*;
public class Main {
public static void main(String[] args) {
int N, M;
Scanner scanner = new Scanner(System.in);
N = scanner.nextInt();
DisJoint disJoint = new DisJoint(N + 1);
for (int i = 0; i < N; ++i) {
int a = scanner.nextInt();
int b = scanner.nextInt();
if(disJoint.isSame(a,b)){
System.out.println(a+" "+b);
}
disJoint.join(a,b);
}
scanner.close();
}
}
// 并查集模板
class DisJoint {
private int[] parent;
// 构造函数
public DisJoint(int n) {
parent = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i; // 初始化时每个元素的父节点是自己
}
}
// 查找根节点,并做路径压缩
public int find(int n) {
if (parent[n] != n) {
parent[n] = find(parent[n]); // 路径压缩
}
return parent[n];
}
// 判断两个元素是否在同一集合
public boolean isSame(int n, int m) {
return find(n) == find(m); // 如果根节点相同,则属于同一集合
}
// 合并两个集合
public void join(int n, int m) {
int rootN = find(n);
int rootM = find(m);
if (rootN != rootM) {
parent[rootN] = rootM; // 将rootN的根节点连接到rootM
}
}
}
冗余连接||
有一种有向树,该树只有一个根节点,所有其他节点都是该根节点的后继。该树除了根节点之外的每一个节点都有且只有一个父节点,而根节点没有父节点。有向树拥有 n 个节点和 n - 1 条边。如图:

现在有一个有向图,有向图是在有向树中的两个没有直接链接的节点中间添加一条有向边。

输入一个有向图,该图由一个有着 n 个节点(节点编号 从 1 到 n),n 条边,请返回一条可以删除的边,使得删除该条边之后该有向图可以被当作一颗有向树。
输入描述
第一行输入一个整数 N,表示有向图中节点和边的个数。
后续 N 行,每行输入两个整数 s 和 t,代表这是 s 节点连接并指向 t 节点的单向边
输出描述
输出一条可以删除的边,若有多条边可以删除,请输出标准输入中最后出现的一条边。
输入示例
3
1 2
1 3
2 3
输出示例
2 3
思路
本题的本质是 :有一个有向图,是由一颗有向树 + 一条有向边组成的 (所以此时这个图就不能称之为有向树),现在让我们找到那条边 把这条边删了,让这个图恢复为有向树。
还有“若有多条边可以删除,请输出标准输入中最后出现的一条边”,这说明在两条边都可以删除的情况下,要删顺序靠后的边!
我们来想一下 有向树的性质,如果是有向树的话,只有根节点入度为0,其他节点入度都为1(因为该树除了根节点之外的每一个节点都有且只有一个父节点,而根节点没有父节点)。
所以情况一:如果我们找到入度为2的点,那么删一条指向该节点的边就行了

找到了节点3 的入度为2,删 1 -> 3 或者 2 -> 3 。选择删顺序靠后便可。
但 入度为2 还有一种情况,情况二,只能删特定的一条边,如图:

节点3 的入度为 2,但在删除边的时候,只能删 这条边(节点1 -> 节点3),如果删这条边(节点4 -> 节点3),那么删后本图也不是有向树了(因为找不到根节点)。
综上,如果发现入度为2的节点,我们需要判断 删除哪一条边,删除后本图能成为有向树。如果是删哪个都可以,优先删顺序靠后的边。
情况三: 如果没有入度为2的点,说明 图中有环了(注意是有向环)。

对于情况三,删掉构成环的边就可以了。
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
public class Main {
static int n;
static int[] father = new int[1001]; // 并查集数组
// 并查集初始化
public static void init() {
for (int i = 1; i <= n; ++i) {
father[i] = i;
}
}
// 并查集里寻根的过程
public static int find(int u) {
if (u == father[u]) return u;
return father[u] = find(father[u]); // 路径压缩
}
// 将 v->u 这条边加入并查集
public static void join(int u, int v) {
u = find(u);
v = find(v);
if (u != v) {
father[v] = u; // 合并两棵树
}
}
// 判断 u 和 v 是否有同一个根
public static boolean same(int u, int v) {
return find(u) == find(v);
}
// 在有向图里找到删除的那条边,使其变成树
public static void getRemoveEdge(List<int[]> edges) {
init(); // 初始化并查集
for (int i = 0; i < n; i++) { // 遍历所有的边
if (same(edges.get(i)[0], edges.get(i)[1])) { // 如果构成有向环了,就是要删除的边
System.out.println(edges.get(i)[0] + " " + edges.get(i)[1]);
return;
} else {
join(edges.get(i)[0], edges.get(i)[1]);
}
}
}
// 删一条边之后判断是不是树
public static boolean isTreeAfterRemoveEdge(List<int[]> edges, int deleteEdge) {
init(); // 初始化并查集
for (int i = 0; i < n; i++) {
if (i == deleteEdge) continue;
if (same(edges.get(i)[0], edges.get(i)[1])) { // 如果构成有向环了,一定不是树
return false;
}
join(edges.get(i)[0], edges.get(i)[1]);
}
return true;
}
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
List<int[]> edges = new ArrayList<>(); // 存储所有的边
n = sc.nextInt(); // 顶点数
int[] inDegree = new int[n + 1]; // 记录每个节点的入度
for (int i = 0; i < n; i++) {
int s = sc.nextInt(); // 边的起点
int t = sc.nextInt(); // 边的终点
inDegree[t]++;
edges.add(new int[]{s, t}); // 将边加入列表
}
List<Integer> vec = new ArrayList<>(); // 记录入度为2的边(如果有的话就两条边)
// 找入度为2的节点所对应的边,注意要倒序,因为优先删除最后出现的一条边
for (int i = n - 1; i >= 0; i--) {
if (inDegree[edges.get(i)[1]] == 2) {
vec.add(i);
}
}
// 情况一、情况二
if (vec.size() > 0) {
// vec里的边已经按照倒叙放的,所以优先删 vec.get(0) 这条边
if (isTreeAfterRemoveEdge(edges, vec.get(0))) {
System.out.println(edges.get(vec.get(0))[0] + " " + edges.get(vec.get(0))[1]);
} else {
System.out.println(edges.get(vec.get(1))[0] + " " + edges.get(vec.get(1))[1]);
}
return;
}
// 处理情况三:明确没有入度为2的情况,一定有有向环,找到构成环的边返回即可
getRemoveEdge(edges);
}
}
拓扑排序
题目描述:
某个大型软件项目的构建系统拥有 N 个文件,文件编号从 0 到 N - 1,在这些文件中,某些文件依赖于其他文件的内容,这意味着如果文件 A 依赖于文件 B,则必须在处理文件 A 之前处理文件 B (0 <= A, B <= N - 1)。请编写一个算法,用于确定文件处理的顺序。
输入描述:
第一行输入两个正整数 N, M。表示 N 个文件之间拥有 M 条依赖关系。
后续 M 行,每行两个正整数 S 和 T,表示 T 文件依赖于 S 文件。
输出描述:
输出共一行,如果能处理成功,则输出文件顺序,用空格隔开。
如果不能成功处理(相互依赖),则输出 -1。
输入示例:
5 4
0 1
0 2
1 3
2 4
输出示例:
0 1 2 3 4
拓扑排序的背景
概括来说,给出一个 有向图,把这个有向图转成线性的排序 就叫拓扑排序。
当然拓扑排序也要检测这个有向图 是否有环,即存在循环依赖的情况,因为这种情况是不能做线性排序的。
所以拓扑排序也是图论中判断有向无环图的常用方法。
拓扑排序的思路
拓扑排序指的是一种 解决问题的大体思路, 而具体算法,可能是广搜也可能是深搜。
大家可能发现 各式各样的解法,纠结哪个是拓扑排序?
其实只要能在把 有向无环图 进行线性排序 的算法 都可以叫做 拓扑排序。
实现拓扑排序的算法有两种:BFS和DFS
。一般来说我们只需要掌握 BFS (广度优先搜索)就可以了。
拓扑排序的过程,其实就两步:
找到入度为0 的节点,加入结果集
将该节点从图中移除
循环以上两步,直到 所有节点都在图中被移除了。
结果集的顺序,就是我们想要的拓扑排序顺序 (结果集里顺序可能不唯一)
判断有环
如果我们发现结果集元素个数 不等于 图中节点个数,我们就可以认定图中一定有 有向环。
代码编写
为了每次可以找到所有节点的入度信息,我们要在初始化的时候,就把每个节点的入度 和 每个节点的依赖关系做统计。
找入度为0 的节点,我们需要用一个队列放存放。
因为每次寻找入度为0的节点,不一定只有一个节点,可能很多节点入度都为0,所以要将这些入度为0的节点放到队列里,依次去处理。
如何把这个入度为0的节点从图中移除呢?
该节点作为出发点所连接的节点的 入度 减一
import java.util.*;
public class Main {
// 存放结果的集合
static List<Integer> res = new ArrayList<>(); //作用域问题
// 构建有向图
static List<List<Integer>> graph = new ArrayList<>();
// 入度
static List<Integer> inDegree = new ArrayList<>();
// BFS 队列
static Queue<Integer> que = new LinkedList<>();
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt(); // 顶点数
int m = scanner.nextInt(); // 边数
//如果用数组 就不要初始化为0
//int[] inDegree = new int[n]; // 数组默认每个元素值为 0
// 初始化图和入度表
for (int i = 0; i < n; i++) {
graph.add(new ArrayList<>());
inDegree.add(0); // 每个顶点的入度初始化为 0
}
// 读取边信息
for (int i = 0; i < m; i++) {
int a = scanner.nextInt();
int b = scanner.nextInt();
graph.get(a).add(b); // 添加边 a -> b
inDegree.set(b, inDegree.get(b) + 1); // b 的入度加 1
}
// 初始化队列,将所有入度为 0 的节点入队
for (int i = 0; i < n; i++) {
if (inDegree.get(i) == 0) {
que.offer(i);
}
}
// BFS 拓扑排序
while (!que.isEmpty()) {
int now = que.poll(); // 队头出队
res.add(now); // 记录结果
for (int next : graph.get(now)) {
inDegree.set(next, inDegree.get(next) - 1); // 邻接点入度减 1
if (inDegree.get(next) == 0) {
que.offer(next); // 入度为 0 的点入队
}
}
}
// 检查是否存在回路
if (res.size() == n) {
// 打印拓扑排序结果
for (int i = 0; i < res.size(); i++) {
System.out.print(res.get(i));
if (i < res.size() - 1) {
System.out.print(" ");
}
}
} else {
// 存在回路
System.out.println(-1);
}
scanner.close();
}
}
Bellman_ford 算法精讲
题目描述
某国为促进城市间经济交流,决定对货物运输提供补贴。共有 n 个编号为 1 到 n 的城市,通过道路网络连接,网络中的道路仅允许从某个城市单向通行到另一个城市,不能反向通行。
网络中的道路都有各自的运输成本和政府补贴,道路的权值计算方式为:运输成本 - 政府补贴。
权值为正表示扣除了政府补贴后运输货物仍需支付的费用;权值为负则表示政府的补贴超过了支出的运输成本,实际表现为运输过程中还能赚取一定的收益。
请找出从城市 1 到城市 n 的所有可能路径中,综合政府补贴后的最低运输成本。
如果最低运输成本是一个负数,它表示在遵循最优路径的情况下,运输过程中反而能够实现盈利。
城市 1 到城市 n 之间可能会出现没有路径的情况,同时保证道路网络中不存在任何负权回路。
负权回路是指一系列道路的总权值为负,这样的回路使得通过反复经过回路中的道路,理论上可以无限地减少总成本或无限地增加总收益。
输入描述
第一行包含两个正整数,第一个正整数 n 表示该国一共有 n 个城市,第二个整数 m 表示这些城市中共有 m 条道路。
接下来为 m 行,每行包括三个整数,s、t 和 v,表示 s 号城市运输货物到达 t 号城市,道路权值为 v(单向图)。
输出描述
如果能够从城市 1 到连通到城市 n, 请输出一个整数,表示运输成本。如果该整数是负数,则表示实现了盈利。如果从城市 1 没有路径可达城市 n,请输出 “unconnected”。
输入示例:
6 7
5 6 -2
1 2 1
5 3 1
2 5 2
2 4 -3
4 6 4
1
思路
本题依然是单源最短路问题,求 从 节点1 到节点n 的最小费用。 但本题不同之处在于 边的权值是有负数了。
从 节点1 到节点n 的最小费用也可以是负数,费用如果是负数 则表示 运输的过程中 政府补贴大于运输成本。
在求单源最短路的方法中,使用dijkstra 的话,则要求图中边的权值都为正数。
Bellman_ford算法的核心思想是 对所有边进行松弛n-1次操作(n为节点数量),从而求得目标最短路。
什么叫做松弛
这里我给大家举一个例子,每条边有起点、终点和边的权值。例如一条边,节点A 到 节点B 权值为value,如图:
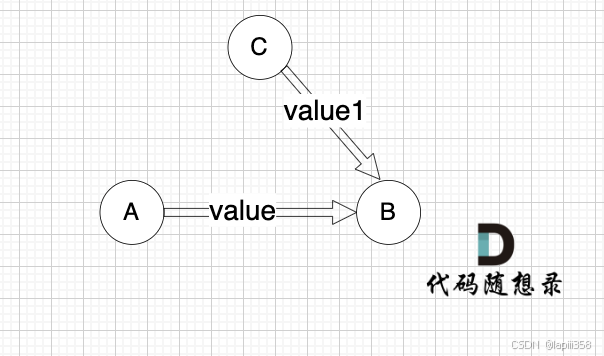 minDist[B] 表示 到达B节点 最小权值,minDist[B] 有哪些状态可以推出来?
minDist[B] 表示 到达B节点 最小权值,minDist[B] 有哪些状态可以推出来?
状态一: minDist[A] + value 可以推出 minDist[B]
状态二: minDist[B]本身就有权值 (可能是其他边链接的节点B 例如节点C,以至于 minDist[B]记录了其他边到minDist[B]的权值)
本题我们要求最小权值,那么 这两个状态我们就取最小的
if (minDist[B] > minDist[A] + value) minDist[B] = minDist[A] + value
如果 通过 A 到 B 这条边可以获得更短的到达B节点的路径,即如果 minDist[B] > minDist[A] + value,那么我们就更新 minDist[B] = minDist[A] + value ,这个过程就叫做 “松弛”
以上代码也可以这么写:minDist[B] = min(minDist[A] + value, minDist[B])
那么为什么是 n - 1次 松弛呢?
我们依然使用minDist数组来表达 起点到各个节点的最短距离,例如minDist[3] = 5 表示起点到达节点3 的最小距离为5
模拟过程
初始化过程。
起点为节点1, 起点到起点的距离为0,所以 minDist[1] 初始化为0
其他节点对应的minDist初始化为max,因为我们要求最小距离,那么还没有计算过的节点 默认是一个最大数,这样才能更新最小距离。
下图是对所有边松弛一次之后的结果:
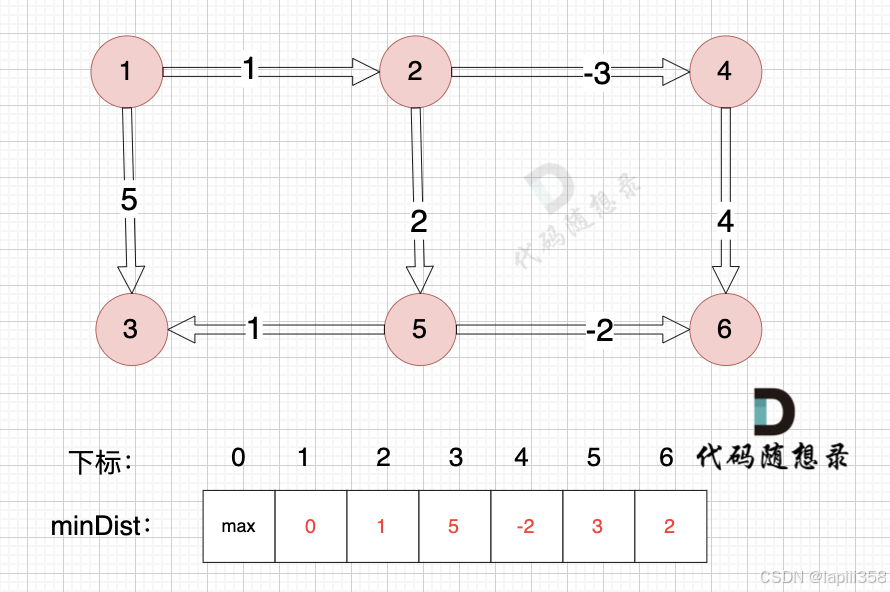
对所有边松弛一次,相当于计算 起点到达 与起点一条边相连的节点 的最短距离。
上面的距离中,我们得到里 起点达到 与起点一条边相邻的节点2 和 节点3 的最短距离,分别是 minDist[2] 和 minDist[3]
这里有录友疑惑了 minDist[3] = 5,分明不是 起点到达 节点3 的最短距离,节点1 -> 节点2 -> 节点5 -> 节点3 这条路线 距离才是4。
注意我上面讲的是 对所有边松弛一次,相当于计算 起点到达 与起点一条边相连的节点 的最短距离,这里 说的是 一条边相连的节点。
所以对所有边松弛一次 能得到 与起点 一条边相连的节点最短距离。
那对所有边松弛两次 可以得到与起点 两条边相连的节点的最短距离。
节点数量为n,那么起点到终点,最多是 n-1 条边相连。
那么无论图是什么样的,边是什么样的顺序,我们对所有边松弛 n-1 次 就一定能得到 起点到达 终点的最短距离。
import java.util.* ;
public class Main{
static class Edge{
int from;
int to;
int val;
public Edge(int from,int to,int val){
this.from=from;
this.to=to;
this.val=val;
}
}
public static void main (String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
int m = sc.nextInt();
List<Edge> edges = new ArrayList<>();
for (int i = 0; i < m; i++) {
int from = sc.nextInt();
int to = sc.nextInt();
int val = sc.nextInt();
edges.add(new Edge(from, to, val));
}
int[] minDist = new int[n+1];
Arrays.fill(minDist,Integer.MAX_VALUE);
minDist[1] = 0;
//数组初始化为最大值
//遍历城市1-n
// 只需要遍历 n-1次
for (int i = 1; i < n; i++) {
//每次松弛 都是对所有边进行松弛
for (Edge edge : edges) {
// 防止从未计算过的节点出发
if (minDist[edge.from] != Integer.MAX_VALUE && (minDist[edge.from] + edge.val) < minDist[edge.to]) {
minDist[edge.to] = minDist[edge.from] + edge.val;
}
}
}
if (minDist[n] == Integer.MAX_VALUE) {
System.out.println("unconnected");
} else {
System.out.println(minDist[n]);
}
}
}
Bellman_ford 队列优化算法(又名SPFA)
题目描述
某国为促进城市间经济交流,决定对货物运输提供补贴。共有 n 个编号为 1 到 n 的城市,通过道路网络连接,网络中的道路仅允许从某个城市单向通行到另一个城市,不能反向通行。
网络中的道路都有各自的运输成本和政府补贴,道路的权值计算方式为:运输成本 - 政府补贴。
权值为正表示扣除了政府补贴后运输货物仍需支付的费用;权值为负则表示政府的补贴超过了支出的运输成本,实际表现为运输过程中还能赚取一定的收益。
请找出从城市 1 到城市 n 的所有可能路径中,综合政府补贴后的最低运输成本。
如果最低运输成本是一个负数,它表示在遵循最优路径的情况下,运输过程中反而能够实现盈利。
城市 1 到城市 n 之间可能会出现没有路径的情况,同时保证道路网络中不存在任何负权回路。
思路
大家可以发现 Bellman_ford 算法每次松弛 都是对所有边进行松弛。
但真正有效的松弛,是基于已经计算过的节点在做的松弛。
只需要对 上一次松弛的时候更新过的节点作为出发节点所连接的边 进行松弛就够了。
基于以上思路,如何记录 上次松弛的时候更新过的节点呢?
用队列来记录。(其实用栈也行,对元素顺序没有要求)
我们在加入队列的过程可以有一个优化,用visited数组记录已经在队列里的元素,已经在队列的元素不用重复加入。
在上面模拟过程中,我们每次都要知道 一个节点作为出发点连接了哪些节点。
如果想方便知道这些数据,就需要使用邻接表来存储这个图。
import java.util.* ;
public class Main{
static class Edge{
int from;
int to;
int val;
public Edge(int from,int to,int val){
this.from=from;
this.to=to;
this.val=val;
}
}
public static void main (String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
int m = sc.nextInt();
List<List<Edge>> edges = new ArrayList<>();
//必不可少的一步!!!
//为什么区间是[0,n]
//如果我们只创建 n 个 ArrayList
//那么就只有edges.get(0) 一直到.get(n-1)
for(int i=0;i<=n;i++){
edges.add(new ArrayList<>());
}
for (int i = 0; i < m; i++) {
int from = sc.nextInt();
int to = sc.nextInt();
int val = sc.nextInt();
edges.get(from).add(new Edge(from,to, val));
}
//1.最短距离数组
int[] minDist = new int[n+1];
Arrays.fill(minDist,Integer.MAX_VALUE);
minDist[1] = 0;
// 2.如果在队列里面就不用处理
boolean[] isInQueue = new boolean[n+1];
isInQueue[1]=true;
// 3.声明一个队列
Queue<Integer> que = new LinkedList<>();
que.offer(1);
while(!que.isEmpty()){
int node = que.poll();
isInQueue[node]=false;
for(Edge edge:edges.get(node)){
if(minDist[edge.to]>minDist[edge.from]+edge.val){
minDist[edge.to]=minDist[edge.from]+edge.val;
if (!isInQueue[edge.to]) {
que.offer(edge.to);
isInQueue[edge.to] = true;
}
}
}
}
if (minDist[n] == Integer.MAX_VALUE) {
System.out.println("unconnected");
} else {
System.out.println(minDist[n]);
}
}
}
bellman_ford之判断负权回路
题目与上两题一样,但是图中可能出现负权回路。
负权回路是指一系列道路的总权值为负,这样的回路使得通过反复经过回路中的道路,理论上可以无限地减少总成本或无限地增加总收益。
为了避免货物运输商采用负权回路这种情况无限的赚取政府补贴,算法还需检测这种特殊情况。
请找出从城市 1 到城市 n 的所有可能路径中,综合政府补贴后的最低运输成本。同时能够检测并适当处理负权回路的存在。
城市 1 到城市 n 之间可能会出现没有路径的情况。
【输出描述】
如果没有发现负权回路,则输出一个整数,表示从城市 1 到城市 n 的最低运输成本(包括政府补贴)。
如果该整数是负数,则表示实现了盈利。如果发现了负权回路的存在,则输出 “circle”。如果从城市 1 无法到达城市 n,则输出 “unconnected”。
思路
如果在这样的图中求最短路的话, 就会在这个环里无限循环 (也是负数+负数 只会越来越小),无法求出最短路径。
第一种思路:
在没有负权回路的图中,松弛 n 次以上 ,结果不会有变化。
但本题有 负权回路,如果松弛 n 次,结果就会有变化了,因为 有负权回路 就是可以无限最短路径(一直绕圈,就可以一直得到无限小的最短距离)。
那么每松弛一次,都会更新最短路径,所以结果会一直有变化。
那么解决本题的 核心思路,就是在SPFA算法的基础上,再多松弛一次,看minDist数组 是否发生变化。
第二种思路:
每个节点最多被松弛 n 次(通过 count 数组记录)。
一旦某个节点的松弛次数达到 n,立即停止,判定存在负权回路。
import java.util.* ;
public class Main{
static class Edge{
int from;
int to;
int val;
public Edge(int from,int to,int val){
this.from=from;
this.to=to;
this.val=val;
}
}
public static void main (String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
int m = sc.nextInt();
List<List<Edge>> edges = new ArrayList<>();
for(int i=0;i<=n;i++){
edges.add(new ArrayList<>());
}
for (int i = 0; i < m; i++) {
int from = sc.nextInt();
int to = sc.nextInt();
int val = sc.nextInt();
edges.get(from).add(new Edge(from,to, val));
}
//1.最短距离数组
int[] minDist = new int[n+1];
Arrays.fill(minDist,Integer.MAX_VALUE);
minDist[1] = 0;
// 2.如果在队列里面就不用处理
boolean[] isInQueue = new boolean[n+1];
isInQueue[1]=true;
// 3.声明一个队列
Queue<Integer> que = new LinkedList<>();
que.offer(1);
//用于判断是否有负权回路
boolean flag = false;
int[] count = new int[n+1];
count[1]=1;
while(!que.isEmpty()){
int node = que.poll();
isInQueue[node]=false;
for(Edge edge:edges.get(node)){
if(minDist[edge.to]>minDist[edge.from]+edge.val){
minDist[edge.to]=minDist[edge.from]+edge.val;
if (!isInQueue[edge.to]) {
que.offer(edge.to);
count[edge.to]++;
isInQueue[edge.to] = true;
}
if(count[edge.to]==n){
flag=true;
que.clear();
break;
}
}
}
}
if(flag){
System.out.println("circle");
}
else if (minDist[n] == Integer.MAX_VALUE) {
System.out.println("unconnected");
} else {
System.out.println(minDist[n]);
}
}
}
bellman_ford之单源有限最短路
在上面几题的基础上,没有负权回路,加一个条件,请计算在最多经过 k 个城市的条件下,从城市 src 到城市 dst 的最低运输成本。
思路
对所有边松弛一次,相当于计算 起点到达 与起点一条边相连的节点 的最短距离。
节点数量为n,起点到终点,最多是 n-1 条边相连。 那么对所有边松弛 n-1 次 就一定能得到 起点到达 终点的最短距离。
本题是最多经过 k 个城市, 那么是 k + 1条边相连的节点。 那么对所有边松弛 k + 1次,就是求 起点到达 与起点k + 1条边相连的节点的 最短距离。
理论上来说,对所有边松弛一次,相当于计算 起点到达 与起点一条边相连的节点 的最短距离。
对所有边松弛两次,相当于计算 起点到达 与起点两条边相连的节点的最短距离。
对所有边松弛三次,以此类推。
但在对所有边松弛第一次的过程中,大家会发现,不仅仅 与起点一条边相连的节点更新了,所有节点都更新了。
而且对所有边的后面几次松弛,同样是更新了所有的节点,说明 至多经过k 个节点 这个限制 根本没有限制住,每个节点的数值都被更新了。
理论上来说节点3 应该在对所有边第二次松弛的时候才更新。 这因为当时是基于已经计算好的 节点2(minDist[2])来做计算了。
minDist[2]在计算边:(节点1 -> 节点2)的时候刚刚被赋值为 -1。
这样就造成了一个情况,即:计算minDist数组的时候,基于了本次松弛的 minDist数值,而不是上一次 松弛时候minDist的数值。
所以在每次计算 minDist 时候,要基于 对所有边上一次松弛的 minDist 数值才行,所以我们要记录上一次松弛的minDist。
import java.util.*;
public class Main {
// 基于Bellman_for一般解法解决单源最短路径问题
// Define an inner class Edge
static class Edge {
int from;
int to;
int val;
public Edge(int from, int to, int val) {
this.from = from;
this.to = to;
this.val = val;
}
}
public static void main(String[] args) {
// Input processing
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
int m = sc.nextInt();
List<Edge> graph = new ArrayList<>();
for (int i = 0; i < m; i++) {
int from = sc.nextInt();
int to = sc.nextInt();
int val = sc.nextInt();
graph.add(new Edge(from, to, val));
}
int src = sc.nextInt();
int dst = sc.nextInt();
int k = sc.nextInt();
int[] minDist = new int[n + 1];
int[] minDistCopy;
Arrays.fill(minDist, Integer.MAX_VALUE);
minDist[src] = 0;
for (int i = 0; i < k + 1; i++) { // Relax all edges k + 1 times
minDistCopy = Arrays.copyOf(minDist, n + 1);
for (Edge edge : graph) {
int from = edge.from;
int to = edge.to;
int val = edge.val;
// Use minDistCopy to calculate minDist
if (minDistCopy[from] != Integer.MAX_VALUE && minDist[to] > minDistCopy[from] + val) {
minDist[to] = minDistCopy[from] + val;
}
}
}
// Output printing
if (minDist[dst] == Integer.MAX_VALUE) {
System.out.println("unreachable");
} else {
System.out.println(minDist[dst]);
}
}
}
最小生成树之prim
题目描述:
在世界的某个区域,有一些分散的神秘岛屿,每个岛屿上都有一种珍稀的资源或者宝藏。国王打算在这些岛屿上建公路,方便运输。
不同岛屿之间,路途距离不同,国王希望你可以规划建公路的方案,如何可以以最短的总公路距离将 所有岛屿联通起来。
给定一张地图,其中包括了所有的岛屿,以及它们之间的距离。以最小化公路建设长度,确保可以链接到所有岛屿。
输入描述:
第一行包含两个整数V 和 E,V代表顶点数,E代表边数 。顶点编号是从1到V。例如:V=2,一个有两个顶点,分别是1和2。
接下来共有 E 行,每行三个整数 v1,v2 和 val,v1 和 v2 为边的起点和终点,val代表边的权值。
输出描述:
输出联通所有岛屿的最小路径总距离
输入示例:
7 11
1 2 1
1 3 1
1 5 2
2 6 1
2 4 2
2 3 2
3 4 1
4 5 1
5 6 2
5 7 1
6 7 1
输出示例:
6
思路
-
第一步,选距离生成树最近节点
-
第二步,最近节点加入生成树
-
第三步,更新非生成树节点到生成树的距离(即更新minDist数组)
-
minDist数组用来记录 每一个节点距离最小生成树的最近距离。
-
示例中节点编号是从1开始,minDist数组下标也从 1 开始计数。
初始状态
minDist 数组 里的数值初始化为 最大数,因为本题 节点距离不会超过 10000,所以 初始化最大数为 10001就可以。
现在 还没有最小生成树,默认每个节点距离最小生成树是最大的,这样后面我们在比较的时候,发现更近的距离,才能更新到 minDist 数组上。

模拟过程(只模拟两轮)
第一轮
1、prim三部曲,第一步:选距离生成树最近节点
选择距离最小生成树最近的节点,加入到最小生成树,刚开始还没有最小生成树,所以随便选一个节点加入就好(因为每一个节点一定会在最小生成树里,所以随便选一个就好),那我们选择节点1 (符合遍历数组的习惯,第一个遍历的也是节点1)
2、prim三部曲,第二步:最近节点加入生成树
此时 节点1 已经算最小生成树的节点。
3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)

注意图中我标记了 minDist数组里更新的权值,是哪两个节点之间的权值,例如 minDist[2] =1 ,这个 1 是 节点1 与 节点2 之间的连线,清楚这一点对最后我们记录 最小生成树的权值总和很重要。
第二轮
1、prim三部曲,第一步:选距离生成树最近节点
选取一个距离 最小生成树(节点1) 最近的非生成树里的节点,节点2,3,5 距离 最小生成树(节点1) 最近,选节点 2(其实选 节点3或者节点2都可以,距离一样的)加入最小生成树。
2、prim三部曲,第二步:最近节点加入生成树
此时 节点1 和 节点2,已经是最小生成树的节点。
3、prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
接下来,我们要更新节点距离最小生成树的距离,如图:

import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int v = scanner.nextInt();
int e = scanner.nextInt();
// 初始化邻接矩阵,所有值初始化为一个大值,表示无穷大
int[][] grid = new int[v + 1][v + 1];
for (int i = 1; i <= v; i++) {
Arrays.fill(grid[i], 10001);
}
// 读取边的信息并填充邻接矩阵
for (int i = 0; i < e; i++) {
int x = scanner.nextInt();
int y = scanner.nextInt();
int k = scanner.nextInt();
grid[x][y] = k;
grid[y][x] = k;
}
// 所有节点到最小生成树的最小距离
int[] minDist = new int[v + 1];
Arrays.fill(minDist, 10001);
// 记录节点是否在树里
boolean[] isInTree = new boolean[v + 1];
// Prim算法主循环
//// 只需要循环v-1次建立v-1条边
for (int i = 1; i < v; i++) {
int cur = -1;// 用于记录距离生成树最近的节点
int minVal = Integer.MAX_VALUE; // 记录最短距离
// 选择距离生成树最近的节点
for (int j = 1; j <= v; j++) {
// 如果这个点不在生成树里面,且它的距离小于当前最小值
if (!isInTree[j] && minDist[j] < minVal) {
minVal = minDist[j];
cur = j;
}
}
// 将最近的节点加入生成树
isInTree[cur] = true;
// 更新非生成树节点到生成树的距离
for (int j = 1; j <= v; j++) {
//当前cur节点比较
if (!isInTree[j] && grid[cur][j] < minDist[j]) {
minDist[j] = grid[cur][j];
}
}
}
// 统计结果
int result = 0;
for (int i = 2; i <= v; i++) {
result += minDist[i];// 从2开始,跳过起始节点
}
System.out.println(result);
scanner.close();
}
}
kruskal算法
- 题目同上题,找最小生成树。
思路
- prim 算法是维护节点的集合,而 Kruskal 是维护边的集合。
- 边的权值排序,因为要优先选最小的边加入到生成树里
- 遍历排序后的边
- 如果边首尾的两个节点在同一个集合,说明如果连上这条边图中会出现环
- 如果边首尾的两个节点不在同一个集合,加入到最小生成树,并把两个节点加入同一个集合
模拟

排序后的边顺序为[(1,2) (4,5) (1,3) (2,6) (3,4) (6,7) (5,7) (1,5) (3,2) (2,4) (5,6)]
(1,2) 表示节点1 与 节点2 之间的边。权值相同的边,先后顺序无所谓。
开始从头遍历排序后的边。
选边(1,2),节点1 和 节点2 不在同一个集合,所以生成树可以添加边(1,2),并将 节点1,节点2 放在同一个集合。
 选边(4,5),节点4 和 节点 5 不在同一个集合,生成树可以添加边(4,5) ,并将节点4,节点5 放到同一个集合。
选边(4,5),节点4 和 节点 5 不在同一个集合,生成树可以添加边(4,5) ,并将节点4,节点5 放到同一个集合。

在上面的讲解中,看图的话 大家知道如何判断 两个节点 是否在同一个集合(是否有绿色的线连在一起),以及如何把两个节点加入集合(就在图中把两个节点连上)
- 但在代码中,如果将两个节点加入同一个集合,又如何判断两个节点是否在同一个集合呢?
- 用并查集
import java.util.*;
class Edge {
int l, r, val;
Edge(int l, int r, int val) {
this.l = l;
this.r = r;
this.val = val;
}
}
public class Main {
private static int n = 10001;
private static int[] father = new int[n];
// 并查集初始化
public static void init() {
for (int i = 0; i < n; i++) {
father[i] = i;
}
}
// 并查集的查找操作
public static int find(int u) {
if (u == father[u]) return u;
return father[u] = find(father[u]);
}
public static void join(int u, int v) {
u = find(u);
v = find(v);
if (u == v) return;
father[v] = u;
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int v = scanner.nextInt();
int e = scanner.nextInt();
List<Edge> edges = new ArrayList<>();
int result_val = 0;
for (int i = 0; i < e; i++) {
int v1 = scanner.nextInt();
int v2 = scanner.nextInt();
int val = scanner.nextInt();
edges.add(new Edge(v1, v2, val));
}
//对边进行排序
edges.sort(Comparator.comparingInt(edge -> edge.val));
// 并查集初始化
init();
// 从头开始遍历边
for (Edge edge : edges) {
int x = find(edge.l);
int y = find(edge.r);
if (x != y) {
result_val += edge.val;
join(x, y);
}
}
System.out.println(result_val);
scanner.close();
}
}
Floyd 算法
【题目描述】
小明喜欢去公园散步,公园内布置了许多的景点,相互之间通过小路连接,小明希望在观看景点的同时,能够节省体力,走最短的路径。
给定一个公园景点图,图中有 N 个景点(编号为 1 到 N),以及 M 条双向道路连接着这些景点。每条道路上行走的距离都是已知的。
小明有 Q 个观景计划,每个计划都有一个起点 start 和一个终点 end,表示他想从景点 start 前往景点 end。由于小明希望节省体力,他想知道每个观景计划中从起点到终点的最短路径长度。 请你帮助小明计算出每个观景计划的最短路径长度。
【输入描述】
第一行包含两个整数 N, M, 分别表示景点的数量和道路的数量。
接下来的 M 行,每行包含三个整数 u, v, w,表示景点 u 和景点 v 之间有一条长度为 w 的双向道路。
接下里的一行包含一个整数 Q,表示观景计划的数量。
接下来的 Q 行,每行包含两个整数 start, end,表示一个观景计划的起点和终点。
【输出描述】
对于每个观景计划,输出一行表示从起点到终点的最短路径长度。如果两个景点之间不存在路径,则输出 -1。
【输入示例】
7 3 1 2 4 2 5 6 3 6 8 2 1 2 2 3
【输出示例】
4 -1
【提示信息】
从 1 到 2 的路径长度为 4,2 到 3 之间并没有道路。
1 <= N, M, Q <= 1000.
思路
Floyd算法核心思想是动态规划。
-
例如我们再求节点1 到 节点9 的最短距离,用二维数组来表示即:grid[1][9],如果最短距离是10 ,那就是 grid[1][9] =10。
-
那 节点1 到 节点9 的最短距离 是不是可以由 节点1 到节点5的最短距离 + 节点5到节点9的最短距离组成呢? 即 grid[1][9] = grid[1][5] + grid[5][9]
-
节点1 到节点5的最短距离 是不是可以有 节点1 到 节点3的最短距离 + 节点3 到 节点5 的最短距离组成呢? 即 grid[1][5] = grid[1][3] + grid[3][5]
-
以此类推,节点1 到 节点3的最短距离 可以由更小的区间组成。那么这样我们是不是就找到了,子问题推导求出整体最优方案的递归关系呢。
-
节点1 到 节点9 的最短距离 可以由 节点1 到节点5的最短距离 + 节点5到节点9的最短距离组成, 也可以有 节点1 到节点7的最短距离 + 节点7 到节点9的最短距离的距离组成。
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt(); // 顶点数
int m = sc.nextInt(); // 边数
// 初始化距离矩阵,最大值设置为10005
final int INF = 10005;
int[][] grid = new int[n + 1][n + 1];
// 初始化 grid 数组
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
if (i != j) {
grid[i][j] = INF;
}
}
}
// 输入边信息
for (int i = 0; i < m; i++) {
int p1 = sc.nextInt();
int p2 = sc.nextInt();
int val = sc.nextInt();
grid[p1][p2] = val;
grid[p2][p1] = val; // 双向图
}
// Floyd-Warshall 算法
//注意k要放在最外层
for (int k = 1; k <= n; k++) {
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
if (grid[i][k] + grid[k][j] < grid[i][j]) {
grid[i][j] = grid[i][k] + grid[k][j];
}
}
}
}
// 输出查询结果
int z = sc.nextInt(); // 查询次数
while (z-- > 0) {
int start = sc.nextInt();
int end = sc.nextInt();
if (grid[start][end] == INF) {
System.out.println(-1);
} else {
System.out.println(grid[start][end]);
}
}
sc.close(); // 关闭Scanner
}
}
dijkstra(朴素版)
【题目描述】
小明是一位科学家,他需要参加一场重要的国际科学大会,以展示自己的最新研究成果。
小明的起点是第一个车站,终点是最后一个车站。然而,途中的各个车站之间的道路状况、交通拥堵程度以及可能的自然因素(如天气变化)等不同,这些因素都会影响每条路径的通行时间。
小明希望能选择一条花费时间最少的路线,以确保他能够尽快到达目的地。
【输入描述】
第一行包含两个正整数,第一个正整数 N 表示一共有 N 个公共汽车站,第二个正整数 M 表示有 M 条公路。
接下来为 M 行,每行包括三个整数,S、E 和 V,代表了从 S 车站可以单向直达 E 车站,并且需要花费 V 单位的时间。
【输出描述】
输出一个整数,代表小明从起点到终点所花费的最小时间。
思路
- 第一步,选源点到哪个节点近且该节点未被访问过
- 第二步,该最近节点被标记访问过
- 第三步,更新非访问节点到源点的距离(即更新minDist数组
- minDist数组 用来记录 每一个节点距离源点的最小距离。
- 示例中节点编号是从1开始,所以为了让大家看的不晕,minDist数组下标我也从 1 开始计数,下标0 就不使用了,这样 下标和节点标号就可以对应上了,避免大家搞混
模拟过程
0、初始化
minDist数组数值初始化为int最大值。
这里在强点一下 minDist数组的含义:记录所有节点到源点的最短路径,那么初始化的时候就应该初始为最大值,这样才能在后续出现最短路径的时候及时更新。

源点(节点1) 到自己的距离为0,所以 minDist[1] = 0
此时所有节点都没有被访问过,所以 visited数组都为0
- 模拟过程
以下为dijkstra 三部曲
1.1 第一次模拟
1、选源点到哪个节点近且该节点未被访问过
源点距离源点最近,距离为0,且未被访问。
2、该最近节点被标记访问过
标记源点访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:

更新 minDist数组,即:源点(节点1) 到 节点2 和 节点3的距离。
源点到节点2的最短距离为1,小于原minDist[2]的数值max,更新minDist[2] = 1
源点到节点3的最短距离为4,小于原minDist[3]的数值max,更新minDist[3] = 4
1.2 第二次模拟
1、选源点到哪个节点近且该节点未被访问过
未访问过的节点中,源点到节点2距离最近,选节点2
2、该最近节点被标记访问过
节点2被标记访问过
3、更新非访问节点到源点的距离(即更新minDist数组) ,如图:

更新 minDist数组,即:源点(节点1) 到 节点6 、 节点3 和 节点4的距离。
以后的过程以此类推
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
// 输入节点数 n 和边数 m
int n = sc.nextInt();
int m = sc.nextInt();
// 定义一个邻接矩阵,初始化为一个很大的数
final int INF = Integer.MAX_VALUE;
int[][] grid = new int[n + 1][n + 1];
// 初始化 grid 为 INF,表示没有直接路径
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= n; j++) {
if (i != j) {
grid[i][j] = INF;
}
}
}
// 输入边的信息
for (int i = 0; i < m; i++) {
int p1 = sc.nextInt();
int p2 = sc.nextInt();
int val = sc.nextInt();
grid[p1][p2] = val;
}
// 设置起点和终点
int start = 1;
int end = n;
// 存储从源点到每个节点的最短距离
int[] minDist = new int[n + 1];
// 记录顶点是否被访问过
boolean[] visited = new boolean[n + 1];
// 初始化最短距离数组,起始点到自身的距离为0,其他为INF
for (int i = 1; i <= n; i++) {
minDist[i] = INF;
}
minDist[start] = 0;
// 遍历所有节点,执行Dijkstra算法
for (int i = 1; i <= n; i++) {
int minVal = INF;
int cur = -1;
// 选择距离起点最近且未访问过的节点
for (int v = 1; v <= n; v++) {
if (!visited[v] && minDist[v] < minVal) {
minVal = minDist[v];
cur = v;
}
}
// 如果当前节点无法访问,则跳出循环(即剩下的节点不可达)
if (cur == -1) break;
visited[cur] = true; // 标记该节点已被访问
// 更新非访问节点到源点的最短距离
for (int v = 1; v <= n; v++) {
if (!visited[v] && grid[cur][v] != INF && minDist[cur] + grid[cur][v] < minDist[v]) {
minDist[v] = minDist[cur] + grid[cur][v];
}
}
}
// 输出结果,如果终点不可达,输出 -1
if (minDist[end] == INF) {
System.out.println(-1);
} else {
System.out.println(minDist[end]);
}
sc.close(); // 关闭Scanner
}
}


















 1420
1420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









