







C++对象的内存模型
类是创建对象的模板,不占用内存空间,不存在于编译后的可执行文件中;而对象是实实在在的数据,需要内存来存储。对象被创建时会在栈区或者堆区分配内存。
直观的认识是,如果创建了 10 个对象,就要分别为这 10 个对象的成员变量和成员函数分配内存,如下图所示:
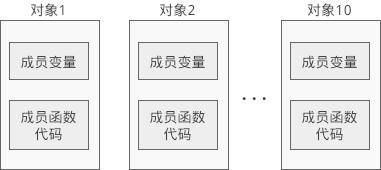
不同对象的成员变量的值可能不同,需要单独分配内存来存储。但是不同对象的成员函数的代码是一样的,上面的内存模型保存了 10 份相同的代码片段,浪费了不少空间,可以将这些代码片段压缩成一份。
事实上编译器也是这样做的,编译器会将成员变量和成员函数分开存储:分别为每个对象的成员变量分配内存,但是所有对象都共享同一段函数代码。如下图所示:
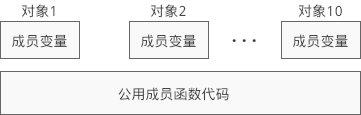
成员变量在堆区或栈区分配内存,成员函数在代码区分配内存。如果你对 C/C++ 程序的内存分区不了解,请阅读《C语言内存精讲》专题。
【示例】使用 sizeof 获取对象所占内存的大小:
#include <iostream>
using namespace std;
class Student{
private:
char *m_name;
int m_age;
float m_score;
public:
void setname(char *name);
void setage(int age);
void setscore(float score);
void show();
};
void Student::setname(char *name){
m_name = name;
}
void Student::setage(int age){
m_age = age;
}
void Student::setscore(float score){
m_score = score;
}
void Student::show(){
cout<<m_name<<"的年龄是"<<m_age<<",成绩是"<<m_score<<endl;
}
int main(){
//在栈上创建对象
Student stu;
cout<<sizeof(stu)<<endl;
//在堆上创建对象
Student *pstu = new Student();
cout<<sizeof(*pstu)<<endl;
//类的大小
cout<<sizeof(Student)<<endl;
return 0;
}
运行结果:
12
12
12
Student 类包含三个成员变量,它们的类型分别是 char *、int、float,都占用 4 个字节的内存,加起来共占用 12 个字节的内存。通过 sizeof 求得的结果等于 12,恰好说明对象所占用的内存仅仅包含了成员变量。
类可以看做是一种复杂的数据类型,也可以使用 sizeof 求得该类型的大小。从运行结果可以看出,在计算类这种类型的大小时,只计算了成员变量的大小,并没有把成员函数也包含在内。
对象的大小只受成员变量的影响,和成员函数没有关系。
假设 stu 的起始地址为 0X1000,那么该对象的内存分布如下图所示:
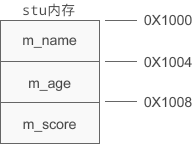
m_name、m_age、m_score 按照声明的顺序依次排列,和结构体非常类似,也会有内存对齐的问题。
C++继承时的对象内存模型
在《C++对象的内存模型》一节中我们讲解了没有继承时对象内存的分布情况。这时的内存模型很简单,成员变量和成员函数会分开存储:
- 对象的内存中只包含成员变量,存储在栈区或堆区(使用 new 创建对象);
- 成员函数与对象内存分离,存储在代码区。
当存在继承关系时,内存模型会稍微复杂一些。
继承时的内存模型
有继承关系时,派生类的内存模型可以看成是基类成员变量和新增成员变量的总和,而所有成员函数仍然存储在另外一个区域——代码区,由所有对象共享。请看下面的代码:
在《C++对象的内存模型》一节中我们讲解了没有继承时对象内存的分布情况。这时的内存模型很简单,成员变量和成员函数会分开存储:
对象的内存中只包含成员变量,存储在栈区或堆区(使用 new 创建对象);
成员函数与对象内存分离,存储在代码区。
当存在继承关系时,内存模型会稍微复杂一些。
继承时的内存模型
有继承关系时,派生类的内存模型可以看成是基类成员变量和新增成员变量的总和,而所有成员函数仍然存储在另外一个区域——代码区,由所有对象共享。请看下面的代码:
#include <cstdio>
using namespace std;
//基类A
class A{
public:
A(int a, int b);
public:
void display();
protected:
int m_a;
int m_b;
};
A::A(int a, int b): m_a(a), m_b(b){}
void A::display(){
printf("m_a=%d, m_b=%d\n", m_a, m_b);
}
//派生类B
class B: public A{
public:
B(int a, int b, int c);
void display();
protected:
int m_c;
};
B::B(int a, int b, int c): A(a, b), m_c(c){ }
void B::display(){
printf("m_a=%d, m_b=%d, m_c=%d\n", m_a, m_b, m_c);
}
int main(){
A obj_a(99, 10);
B obj_b(84, 23, 95);
obj_a.display();
obj_b.display();
return 0;
}
obj_a 是基类对象,obj_b 是派生类对象。假设 obj_a 的起始地址为 0X1000,那么它的内存分布如下图所示:
假设 obj_b 的起始地址为 0X1100,那么它的内存分布如下图所示:
可以发现,基类的成员变量排在前面,派生类的排在后面。
为了让大家理解更加透彻,我们不妨再由 B 类派生出一个 C 类:
//声明并定义派生类C
class C: public B{
public:
C(char a, int b, int c, int d);
public:
void display();
private:
int m_d;
};
C::C(char a, int b, int c, int d): B(a, b, c), m_d(d){ }
void C::display(){
printf("m_a=%d, m_b=%d, m_c=%d, m_d=%d\n", m_a, m_b, m_c, m_d);
}
//创建C类对象obj_c
C obj_c(84, 23, 95, 60);
obj_c.display();
假设 obj_c 的起始地址为 0X1200,那么它的内存分布如下图所示:
成员变量按照派生的层级依次排列,新增成员变量始终在最后。
有成员变量遮蔽时的内存分布
更改上面的 C 类,让它的成员变量遮蔽 A 类和 B 类的成员变量:
//声明并定义派生类C
class C: public B{
public:
C(char a, int b, int c, int d);
public:
void display();
private:
int m_b; //遮蔽A类的成员变量
int m_c; //遮蔽B类的成员变量
int m_d; //新增成员变量
};
C::C(char a, int b, int c, int d): B(a, b, c), m_b(b), m_c(c), m_d(d){ }
void C::display(){
printf("A::m_a=%d, A::m_b=%d, B::m_c=%d\n", m_a, A::m_b, B::m_c);
printf("C::m_b=%d, C::m_c=%d, C::m_d=%d\n", m_b, m_c, m_d);
}
//创建C类对象obj_c
C obj_c(84, 23, 95, 60);
obj_c.display();
假设 obj_c 的起始地址为 0X1300,那么它的内存分布如下图所示:
当基类 A、B 的成员变量被遮蔽时,仍然会留在派生类对象 obj_c 的内存中,C 类新增的成员变量始终排在基类 A、B 的后面。
总结:在派生类的对象模型中,会包含所有基类的成员变量。这种设计方案的优点是访问效率高,能够在派生类对象中直接访问基类变量,无需经过好几层间接计算。obj_a 是基类对象,obj_b 是派生类对象。假设 obj_a 的起始地址为 0X1000,那么它的内存分布如下图所示:
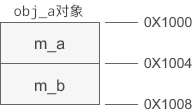
假设 obj_b 的起始地址为 0X1100,那么它的内存分布如下图所示:
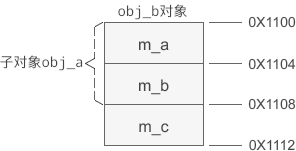
可以发现,基类的成员变量排在前面,派生类的排在后面。
为了让大家理解更加透彻,我们不妨再由 B 类派生出一个 C 类:
//声明并定义派生类C
class C: public B{
public:
C(char a, int b, int c, int d);
public:
void display();
private:
int m_d;
};
C::C(char a, int b, int c, int d): B(a, b, c), m_d(d){ }
void C::display(){
printf("m_a=%d, m_b=%d, m_c=%d, m_d=%d\n", m_a, m_b, m_c, m_d);
}
//创建C类对象obj_c
C obj_c(84, 23, 95, 60);
obj_c.display();假设 obj_c 的起始地址为 0X1200,那么它的内存分布如下图所示:
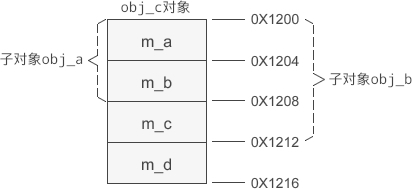
成员变量按照派生的层级依次排列,新增成员变量始终在最后。
有成员变量遮蔽时的内存分布
更改上面的 C 类,让它的成员变量遮蔽 A 类和 B 类的成员变量:
//声明并定义派生类C
class C: public B{
public:
C(char a, int b, int c, int d);
public:
void display();
private:
int m_b; //遮蔽A类的成员变量
int m_c; //遮蔽B类的成员变量
int m_d; //新增成员变量
};
C::C(char a, int b, int c, int d): B(a, b, c), m_b(b), m_c(c), m_d(d){ }
void C::display(){
printf("A::m_a=%d, A::m_b=%d, B::m_c=%d\n", m_a, A::m_b, B::m_c);
printf("C::m_b=%d, C::m_c=%d, C::m_d=%d\n", m_b, m_c, m_d);
}
//创建C类对象obj_c
C obj_c(84, 23, 95, 60);
obj_c.display();假设 obj_c 的起始地址为 0X1300,那么它的内存分布如下图所示:
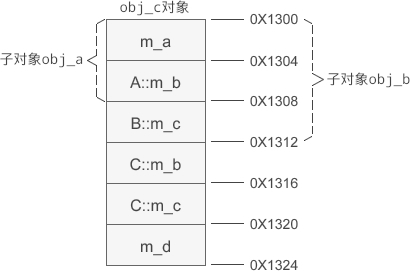
当基类 A、B 的成员变量被遮蔽时,仍然会留在派生类对象 obj_c 的内存中,C 类新增的成员变量始终排在基类 A、B 的后面。
总结:在派生类的对象模型中,会包含所有基类的成员变量。这种设计方案的优点是访问效率高,能够在派生类对象中直接访问基类变量,无需经过好几层间接计算。
C++多继承时的对象内存模型
在《C++继承时的对象模型》一节中我们讲解了单继承时对象的内存模型,这节我们来分析一下多继承时对象的内存模型。请读者先看下面的例子:
#include <cstdio>
using namespace std;
//基类A
class A{
public:
A(int a, int b);
protected:
int m_a;
int m_b;
};
A::A(int a, int b): m_a(a), m_b(b){ }
//基类B
class B{
public:
B(int b, int c);
protected:
int m_b;
int m_c;
};
B::B(int b, int c): m_b(b), m_c(c){ }
//派生类C
class C: public A, public B{
public:
C(int a, int b, int c, int d);
public:
void display();
private:
int m_a;
int m_c;
int m_d;
};
C::C(int a, int b, int c, int d): A(a, b), B(b, c), m_a(a), m_c(c), m_d(d){ }
void C::display(){
printf("A::m_a=%d, A::m_b=%d\n", A::m_a, A::m_b);
printf("B::m_b=%d, B::m_c=%d\n", B::m_b, B::m_c);
printf("C::m_a=%d, C::m_c=%d, C::m_d=%d\n", C::m_a, C::m_c, m_d);
}
int main(){
C obj_c(10, 20, 30, 40);
obj_c.display();
return 0;
}
运行结果:
A::m_a=10, A::m_b=20
B::m_b=20, B::m_c=30
C::m_a=10, C::m_c=30, C::m_d=40
A、B 是基类,C 是派生类,假设 obj_c 的起始地址是 0X1000,那么 obj_c 的内存分布如下图所示:
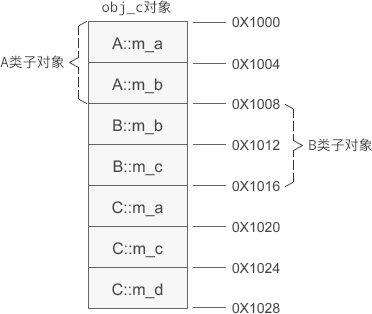
基类对象的排列顺序和继承时声明的顺序相同。
C++虚继承下的内存模型
对于普通继承,基类子对象始终位于派生类对象的前面(也即基类成员变量始终在派生类成员变量的前面),而且不管继承层次有多深,它相对于派生类对象顶部的偏移量是固定的。请看下面的例子:
class A{
protected:
int m_a1;
int m_a2;
};
class B: public A{
protected:
int b1;
int b2;
};
class C: public B{
protected:
int c1;
int c2;
};
class D: public C{
protected:
int d1;
int d2;
};
int main(){
A obj_a;
B obj_b;
C obj_c;
D obj_d;
return 0;
}obj_a、obj_b、obj_c、obj_d 的内存模型如下所示:
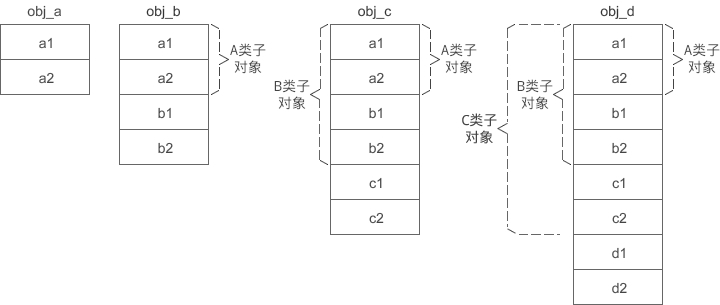
A 是最顶层的基类,在派生类 B、C、D 的对象中,A 类子对象始终位于最前面,偏移量是固定的,为 0。b1、b2 是派生类 B 的新增成员变量,它们的偏移量也是固定的,分别为 8 和 12。c1、c2、d1、d2 也是同样的道理。
前面我们说过,编译器在知道对象首地址的情况下,通过计算偏移来存取成员变量。对于普通继承,基类成员变量的偏移是固定的,不会随着继承层级的增加而改变,存取起来非常方便。
而对于虚继承,恰恰和普通继承相反,大部分编译器会把基类成员变量放在派生类成员变量的后面,这样随着继承层级的增加,基类成员变量的偏移就会改变,就得通过其他方案来计算偏移量。
下面我们来一步一步地分析虚继承时的对象内存模型。
1) 修改上面的代码,使得 A 是 B 的虚基类:
class B: virtual public A
此时 obj_b、obj_c、obj_d 的内存模型就会发生变化,如下图所示:
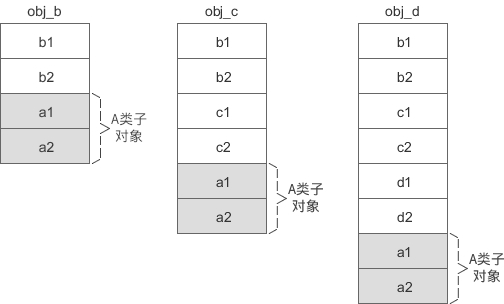
不管是虚基类的直接派生类还是间接派生类,虚基类的子对象始终位于派生类对象的最后面。
2) 再假设 A 是 B 的虚基类,B 又是 C 的虚基类,那么各个对象的内存模型如下图所示:
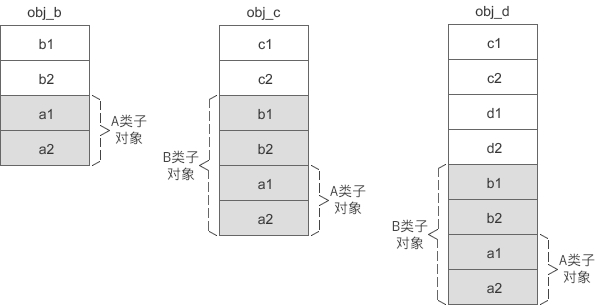
从上面的两张图中可以发现,虚继承时的派生类对象被分成了两部分:
- 不带阴影的一部分偏移量固定,不会随着继承层次的增加而改变,称为固定部分;
- 带有阴影的一部分是虚基类的子对象,偏移量会随着继承层次的增加而改变,称为共享部分。
当要访问对象的成员变量时,需要知道对象的首地址和变量的偏移,对象的首地址很好获得,关键是变量的偏移。对于固定部分,偏移是不变的,很好计算;而对于共享部分,偏移会随着继承层次的增加而改变,这就需要设计一种方案,在偏移不断变化的过程中准确地计算偏移。各个编译器正是在设计这一方案时出现了分歧,不同的编译器设计了不同的方案来计算共享部分的偏移。
对于虚继承,将派生类分为固定部分和共享部分,并把共享部分放在最后,几乎所有的编译器都在这一点上达成了共识。主要的分歧就是如何计算共享部分的偏移,可谓是百花齐放,没有统一标准。
C++将派生类赋值给基类(向上转型)
类其实也是一种数据类型,也可以发生数据类型转换,不过这种转换只有在基类和派生类之间才有意义,并且只能将派生类赋值给基类,包括将派生类对象赋值给基类对象、将派生类指针赋值给基类指针、将派生类引用赋值给基类引用,这在 C++ 中称为向上转型(Upcasting)。相应地,将基类赋值给派生类称为向下转型(Downcasting)。
向上转型非常安全,可以由编译器自动完成;向下转型有风险,需要程序员手动干预。本节只介绍向上转型,向下转型将在后续章节介绍。
向上转型和向下转型是面向对象编程的一种通用概念,它们也存在于 Java、 C# 等编程语言中。
将派生类对象赋值给基类对象
下面的例子演示了如何将派生类对象赋值给基类对象:
#include <iostream>
using namespace std;
//基类
class A{
public:
A(int a);
public:
void display();
public:
int m_a;
};
A::A(int a): m_a(a){ }
void A::display(){
cout<<"Class A: m_a="<<m_a<<endl;
}
//派生类
class B: public A{
public:
B(int a, int b);
public:
void display();
public:
int m_b;
};
B::B(int a, int b): A(a), m_b(b){ }
void B::display(){
cout<<"Class B: m_a="<<m_a<<", m_b="<<m_b<<endl;
}
int main(){
A a(10);
B b(66, 99);
//赋值前
a.display();
b.display();
cout<<"--------------"<<endl;
//赋值后
a = b;
a.display();
b.display();
return 0;
} 运行结果:
Class A: m_a=10
Class B: m_a=66, m_b=99
----------------------------
Class A: m_a=66
Class B: m_a=66, m_b=99
本例中 A 是基类, B 是派生类,a、b 分别是它们的对象,由于派生类 B 包含了从基类 A 继承来的成员,因此可以将派生类对象 b 赋值给基类对象 a。通过运行结果也可以发现,赋值后 a 所包含的成员变量的值已经发生了变化。
赋值的本质是将现有的数据写入已分配好的内存中,对象的内存只包含了成员变量,所以对象之间的赋值是成员变量的赋值,成员函数不存在赋值问题。运行结果也有力地证明了这一点,虽然有a=b;这样的赋值过程,但是 a.display() 始终调用的都是 A 类的 display() 函数。换句话说,对象之间的赋值不会影响成员函数,也不会影响 this 指针。
将派生类对象赋值给基类对象时,会舍弃派生类新增的成员,也就是“大材小用”,如下图所示:
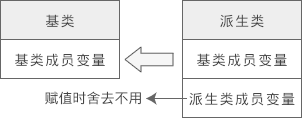
可以发现,即使将派生类对象赋值给基类对象,基类对象也不会包含派生类的成员,所以依然不同通过基类对象来访问派生类的成员。对于上面的例子,a.m_a 是正确的,但 a.m_b 就是错误的,因为 a 不包含成员 m_b。
这种转换关系是不可逆的,只能用派生类对象给基类对象赋值,而不能用基类对象给派生类对象赋值。理由很简单,基类不包含派生类的成员变量,无法对派生类的成员变量赋值。同理,同一基类的不同派生类对象之间也不能赋值。
要理解这个问题,还得从赋值的本质入手。赋值实际上是向内存填充数据,当数据较多时很好处理,舍弃即可;本例中将 b 赋值给 a 时(执行a=b;语句),成员 m_b 是多余的,会被直接丢掉,所以不会发生赋值错误。但当数据较少时,问题就很棘手,编译器不知道如何填充剩下的内存;如果本例中有b= a;这样的语句,编译器就不知道该如何给变量 m_b 赋值,所以会发生错误。
将派生类指针赋值给基类指针
除了可以将派生类对象赋值给基类对象(对象变量之间的赋值),还可以将派生类指针赋值给基类指针(对象指针之间的赋值)。我们先来看一个多继承的例子,继承关系为:
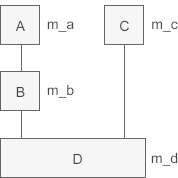
下面的代码实现了这种继承关系:
#include <iostream>
using namespace std;
//基类A
class A{
public:
A(int a);
public:
void display();
protected:
int m_a;
};
A::A(int a): m_a(a){ }
void A::display(){
cout<<"Class A: m_a="<<m_a<<endl;
}
//中间派生类B
class B: public A{
public:
B(int a, int b);
public:
void display();
protected:
int m_b;
};
B::B(int a, int b): A(a), m_b(b){ }
void B::display(){
cout<<"Class B: m_a="<<m_a<<", m_b="<<m_b<<endl;
}
//基类C
class C{
public:
C(int c);
public:
void display();
protected:
int m_c;
};
C::C(int c): m_c(c){ }
void C::display(){
cout<<"Class C: m_c="<<m_c<<endl;
}
//最终派生类D
class D: public B, public C{
public:
D(int a, int b, int c, int d);
public:
void display();
private:
int m_d;
};
D::D(int a, int b, int c, int d): B(a, b), C(c), m_d(d){ }
void D::display(){
cout<<"Class D: m_a="<<m_a<<", m_b="<<m_b<<", m_c="<<m_c<<", m_d="<<m_d<<endl;
}
int main(){
A *pa = new A(1);
B *pb = new B(2, 20);
C *pc = new C(3);
D *pd = new D(4, 40, 400, 4000);
pa = pd;
pa -> display();
pb = pd;
pb -> display();
pc = pd;
pc -> display();
cout<<"-----------------------"<<endl;
cout<<"pa="<<pa<<endl;
cout<<"pb="<<pb<<endl;
cout<<"pc="<<pc<<endl;
cout<<"pd="<<pd<<endl;
return 0;
}运行结果:
Class A: m_a=4
Class B: m_a=4, m_b=40
Class C: m_c=400
-----------------------
pa=0x9b17f8
pb=0x9b17f8
pc=0x9b1800
pd=0x9b17f8
本例中定义了多个对象指针,并尝试将派生类指针赋值给基类指针。与对象变量之间的赋值不同的是,对象指针之间的赋值并没有拷贝对象的成员,也没有修改对象本身的数据,仅仅是改变了指针的指向。
1) 通过基类指针访问派生类的成员
请读者先关注第 68 行代码,我们将派生类指针 pd 赋值给了基类指针 pa,从运行结果可以看出,调用 display() 函数时虽然使用了派生类的成员变量,但是 display() 函数本身却是基类的。也就是说,将派生类指针赋值给基类指针时,通过基类指针只能使用派生类的成员变量,但不能使用派生类的成员函数,这看起来有点不伦不类,究竟是为什么呢?第 71、74 行代码也是类似的情况。
pa 本来是基类 A 的指针,现在指向了派生类 D 的对象,这使得隐式指针 this 发生了变化,也指向了 D 类的对象,所以最终在 display() 内部使用的是 D 类对象的成员变量,相信这一点不难理解。
编译器虽然通过指针的指向来访问成员变量,但是却不通过指针的指向来访问成员函数:编译器通过指针的类型来访问成员函数。对于 pa,它的类型是 A,不管它指向哪个对象,使用的都是 A 类的成员函数,具体原因已在《C++函数编译原理和成员函数的实现》中做了详细讲解。
概括起来说就是:编译器通过指针来访问成员变量,指针指向哪个对象就使用哪个对象的数据;编译器通过指针的类型来访问成员函数,指针属于哪个类的类型就使用哪个类的函数。
2) 赋值后值不一致的情况
本例中我们将最终派生类的指针 pd 分别赋值给了基类指针 pa、pb、pc,按理说它们的值应该相等,都指向同一块内存,但是运行结果却有力地反驳了这种推论,只有 pa、pb、pd 三个指针的值相等,pc 的值比它们都大。也就是说,执行pc = pd;语句后,pc 和 pd 的值并不相等。
这非常出乎我们的意料,按照我们通常的理解,赋值就是将一个变量的值交给另外一个变量,不会出现不相等的情况,究竟是什么导致了 pc 和 pd 不相等呢?
将派生类的指针赋值给基类的指针时也是类似的道理,编译器也可能会在赋值前进行处理。要理解这个问题,首先要清楚 D 类对象的内存模型,如下图所示:
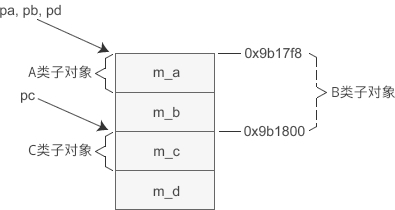
首先要明确的一点是,对象的指针必须要指向对象的起始位置。对于 A 类和 B 类来说,它们的子对象的起始地址和 D 类对象一样,所以将 pd 赋值给 pa、pb 时不需要做任何调整,直接传递现有的值即可;而 C 类子对象距离 D 类对象的开头有一定的偏移,将 pd 赋值给 pc 时要加上这个偏移,这样 pc 才能指向 C 类子对象的起始位置。也就是说,执行pc = pd;语句时编译器对 pd 的值进行了调整,才导致 pc、pd 的值不同。
下面的代码演示了将 pd 赋值给 pc 时编译器的调整过程:
pc = (C*)( (int)pd + sizeof(B) );
如果我们把 B、C 类的继承顺序调整一下,让 C 在 B 前面,如下所示:
class D: public C, public B
那么输出结果就会变为:
pa=0x317fc
pb=0x317fc
pc=0x317f8
pd=0x317f8
将派生类引用赋值给基类引用
既然基类的指针可以指向派生类的对象,那么我们就有理由推断:基类的引用也可以指向派生类的对象,并且它的表现和指针是类似的。
修改上例中 main() 函数内部的代码,用引用取代指针:
int main(){
D d(4, 40, 400, 4000);
A &ra = d;
B &rb = d;
C &rc = d;
ra.display();
rb.display();
rc.display();
return 0;
}运行结果:
Class A: m_a=4
Class B: m_a=4, m_b=40
Class C: m_c=400
ra、rb、rc 是基类的引用,它们都引用了派生类对象 d,并调用了 display() 函数,从运行结果可以发现,虽然使用了派生类对象的成员变量,但是却没有使用派生类的成员函数,这和指针的表现是一样的。
引用和指针的表现之所以如此类似,是因为引用和指针并没有本质上的区别,引用仅仅是对指针进行了简单封装,读者可以猛击《引用在本质上是什么,它和指针到底有什么区别》一文深入了解。
最后需要注意的是,向上转型后通过基类的对象、指针、引用只能访问从基类继承过去的成员(包括成员变量和成员函数),不能访问派生类新增的成员。
C++虚函数表内存
编译器之所以能通过指针指向的对象找到虚函数,是因为在创建对象时额外地增加了虚函数表。
如果一个类包含了虚函数,那么在创建该类的对象时就会额外地增加一个数组,数组中的每一个元素都是虚函数的入口地址。不过数组和对象是分开存储的,为了将对象和数组关联起来,编译器还要在对象中安插一个指针,指向数组的起始位置。这里的数组就是虚函数表(Virtual function table),简写为vtable。
我们以下面的继承关系为例进行讲解:
#include <iostream>
#include <string>
using namespace std;
//People类
class People{
public:
People(string name, int age);
public:
virtual void display();
virtual void eating();
protected:
string m_name;
int m_age;
};
People::People(string name, int age): m_name(name), m_age(age){ }
void People::display(){
cout<<"Class People:"<<m_name<<"今年"<<m_age<<"岁了。"<<endl;
}
void People::eating(){
cout<<"Class People:我正在吃饭,请不要跟我说话..."<<endl;
}
//Student类
class Student: public People{
public:
Student(string name, int age, float score);
public:
virtual void display();
virtual void examing();
protected:
float m_score;
};
Student::Student(string name, int age, float score):
People(name, age), m_score(score){ }
void Student::display(){
cout<<"Class Student:"<<m_name<<"今年"<<m_age<<"岁了,考了"<<m_score<<"分。"<<endl;
}
void Student::examing(){
cout<<"Class Student:"<<m_name<<"正在考试,请不要打扰T啊!"<<endl;
}
//Senior类
class Senior: public Student{
public:
Senior(string name, int age, float score, bool hasJob);
public:
virtual void display();
virtual void partying();
private:
bool m_hasJob;
};
Senior::Senior(string name, int age, float score, bool hasJob):
Student(name, age, score), m_hasJob(hasJob){ }
void Senior::display(){
if(m_hasJob){
cout<<"Class Senior:"<<m_name<<"以"<<m_score<<"的成绩从大学毕业了,并且顺利找到了工作,Ta今年"<<m_age<<"岁。"<<endl;
}else{
cout<<"Class Senior:"<<m_name<<"以"<<m_score<<"的成绩从大学毕业了,不过找工作不顺利,Ta今年"<<m_age<<"岁。"<<endl;
}
}
void Senior::partying(){
cout<<"Class Senior:快毕业了,大家都在吃散伙饭..."<<endl;
}
int main(){
People *p = new People("赵红", 29);
p -> display();
p = new Student("王刚", 16, 84.5);
p -> display();
p = new Senior("李智", 22, 92.0, true);
p -> display();
return 0;
} 运行结果:
Class People:赵红今年29岁了。
Class Student:王刚今年16岁了,考了84.5分。
Class Senior:李智以92的成绩从大学毕业了,并且顺利找到了工作,Ta今年22岁。
各个类的对象内存模型如下所示:
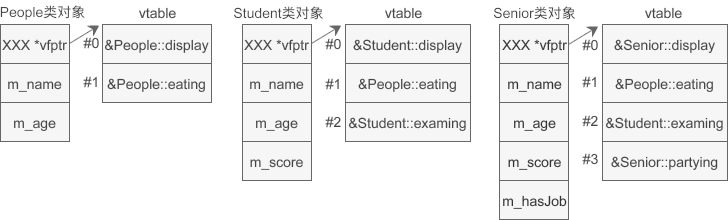
图中左半部分是对象占用的内存,右半部分是虚函数表 vtable。在对象的开头位置有一个指针 vfptr,指向虚函数表,并且这个指针始终位于对象的开头位置。
仔细观察虚函数表,发现基类的虚函数在 vtable 中的索引(下标)是固定的,不会随着继承层次的增加而改变,派生类新增的虚函数放在 vtable 的最后;如果派生类有同名的虚函数遮蔽(覆盖)了基类的虚函数,那么将使用派生类的虚函数替换基类的虚函数,这样具有遮蔽关系的虚函数在 vtable 中只会出现一次。
当通过指针调用虚函数时,先根据指针找到 vfptr,再根据 vfptr 找到虚函数的入口地址。以虚函数 display() 为例,它在 vtable 中的索引为 0,通过 p 调用时:
p -> display();
编译器内部会发生类似下面的转换:
( *( *(p+0) + 0 ) )(p);
下面我们一步一步来分析这个表达式:
0是 vfptr 在对象中的偏移,p+0是 vfptr 的地址;*(p+0)是 vfptr 的值,而 vfptr 是指向 vtable虚函数表地址的指针,所以*(p+0)也就是 vtable 的地址;- display() 在 vtable 中的索引(下标)是 0,所以
( *(p+0) + 0 )也就是 display() 的地址; - 知道了 display() 的地址,
( *( *(p+0) + 0 ) )(p)也就是对 display() 的调用了,这里的 p 就是传递的实参,它会赋值给 this 指针。
可以看到,转换后的表达式是固定的,只要调用 display() 函数,不管它是哪个类的,都会使用这个表达式。换句话说,编译器不管 p 指向哪里,一律转换为相同的表达式。
转换后的表达式没有用到与 p 的类型有关的信息,只要知道 p 的指向就可以调用函数。
再来看一下 eating() 函数,它在 vtable 中的索引为 1,通过 p 调用时:
p -> eating();
编译器内部会发生类似下面的转换:
( *( *(p+0) + 1 ) )(p);
对于不同的虚函数,仅仅改变索引(下标)即可。
以上是针对单继承进行的讲解。当存在多继承时,虚函数表的结构就会变得复杂,尤其是有虚继承时,还会增加虚基类表。
参考文献:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









