




文章目录
前言
想要了解一些好的audio to landmark的方法, 还记得有一篇one-shot的方法, 一会去看看。
正文
这篇论文是输入identity image 和audio signal, 输出会说话的人脸, 它会先切割把人脸框出来,然后做视频生成。
方法-aduio to landmarks
下图是它前半部分框架的方法:

下面是我从github作者提供的ppt看到的
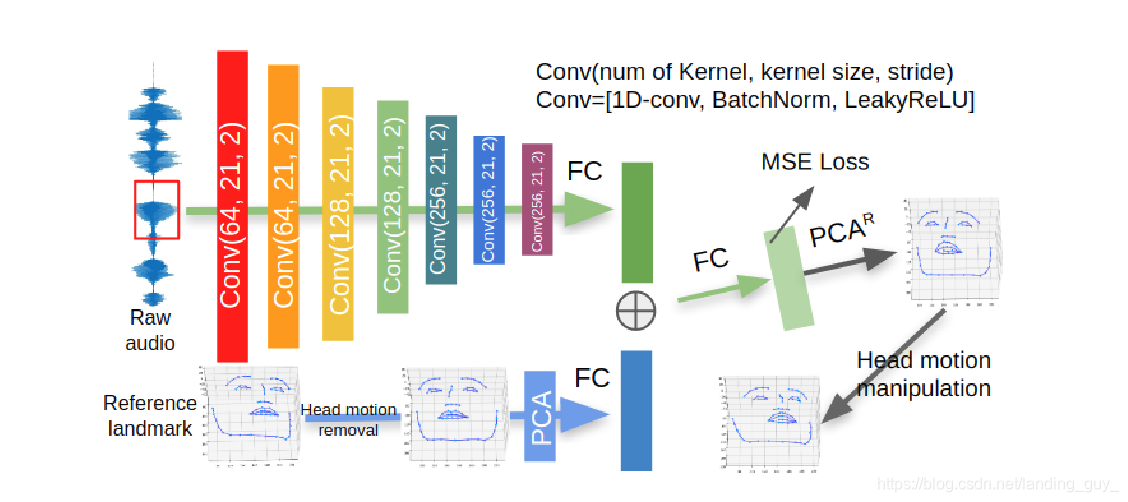
- 注: latex正上箭头是这样
$\hat{}$, 输入\text=可以减小等号长度,\varphi是 φ \varphi φ
整体的公式如下:
p ^ 1 : T = Ψ ( a 1 : T , p p ) \hat{p}_{1:T}\text=\Psi(a_{1:T}, p_p) p^1:T=Ψ(a1:T,pp)
其中 p ^ 1 : T \hat{p}_{1:T} p^1:T 是生成的 landmarks, a 1 : T a_{1:T} a1:T 是音频序列, p p p_p pp 是example frame的landmarks, 就是你输入的那张照片的landmarks.
作者把 Ψ \Psi Ψ 这部分叫做 A T - n e t AT\text-net AT-</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 511
511




 到【灌水乐园】发言
到【灌水乐园】发言









