






 本文深入介绍了正则表达式的定义、元字符和不同层次的使用,包括基础正则表达式BRE和扩展表达式。同时,讲解了grep命令的使用及其选项。此外,还详细阐述了文本处理工具sort、uniq、tr和cut的功能和用法,以及paste命令的分隔符设置。这些工具在处理和分析文本时非常实用。
本文深入介绍了正则表达式的定义、元字符和不同层次的使用,包括基础正则表达式BRE和扩展表达式。同时,讲解了grep命令的使用及其选项。此外,还详细阐述了文本处理工具sort、uniq、tr和cut的功能和用法,以及paste命令的分隔符设置。这些工具在处理和分析文本时非常实用。
文章目录
前言
在编写处理字符串的程序或网页时,经常会有查找符合某些复杂规则的字符串的需要。正则表达式就是用于描述这些规则的工具。换句话说,正则表达式就是记录文本规则的代码。
一、正则表达式
1、正则表达式定义
①正则表达式(别称):正规表达式、常规表达式
②使用字符串来描述、匹配一系列符合某个规则的字符串
③正则表达式组成
普通字符
大小写字母、数字、标点符号及一些其他符号
元字符
指在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式
2、正则表达式层次
基础正则表达式BRE
基础正则表达式是常用的正则表达式部分
除了普通字符外,常见到以下元字符
\ :转义字符,用于取消特殊符号的含义,例: \!、\n、\$等
^ :匹配字符串开始的位置,例: ^a、 ^the、 ^#、^[a-z]
$ :匹配字符串结束的位置,例: word$、 ^$匹配空行
. :匹配除\n之外的任意的一个字符,例: go.d、 g..d
* :匹配前面子表达式0次或者多次,例: goo*d、 go.*d
[list] :匹配list列表中的一个字符,例: go[ola]d, [abc]、 [a-z]、 [a-z0-9]、 [0-9]匹配任意一位数字
[^list] :匹配任意非list列表中的一个字符,例: [^0-9]、 [^A-20-9]、 [^a-z]匹配任意一位非小写字母
\{n\} :匹配前面的子表达式n次,例: go\{2\}d、 '[0-9]\{2\} '匹配两位数字
\{n,\} :匹配前而的子表达式不少于n次,例: go\{2,\}d、'[0-9]\{2,\}'匹配两位及两位以上数字
\{n,m\} :匹配前面的子表达式n到m次,例: go\{2,3\}d、 ' [0-9]\{2,3\}'匹配两位到三位数字
#注意: egrep、 awk使用{n}、{n,小、{n, m}匹配时“{}”前不用加“\”

扩展表达式
扩展正则表达式元字符:(支持的工具: egrep、 awk)
+:匹配前面子表达式1次以上,例: go+d,将匹配至少一个o,如lgod、good、goood等
? :匹配前面子表达式0次或者1次,例: go?d,将匹配gd或god
()﹔将括号中的字符串作为一个整体,例1: g(oo)+d,将匹配oo整体1次以上,如lgood、gooood等
|:以或的方式匹配字条串,例: g(oo|la)d,将匹配good或者glad
grep命令
格式:
grep 选项 文件
过滤文本中的字符串,
命令产生的字符
选项:
-color=auto 对匹配到的文本着色显示
-m # 匹配 # 次后停止
-v 显示不被 pattern 匹配到的行 , 即取反
-i 忽略字符大小写
-n 显示匹配的行号
-c 统计匹配的行数
-o 仅显示匹配到的字符串
-q 静默模式,不输出任何信息
-A # after, 后 # 行
-B # before, 前 # 行
-C # context, 前后各 # 行
-e 实现多个选项间的逻辑 or 关系
-w 匹配整个单词
-E 使用 ERE ,相当于 egrep
-F 不支持正则表达式,相当于 fgrep
-f file 根据模式文件,处理两个文件相同内容 把第一个文件作为匹配条件
-r 递归目录,但是不处理软链接
-R 递归目录,处理软链接
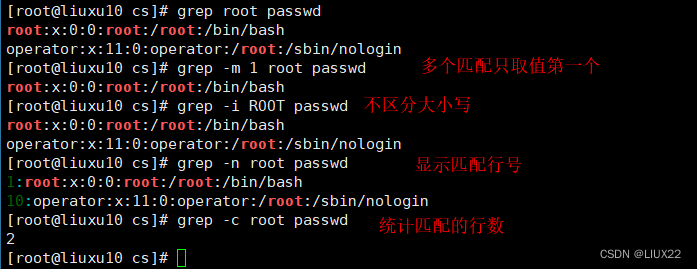
grep -i "^ " 路径 以什么为开头的过滤
grep -i " $" 路径 以什么为结尾的过滤
^$ 表示空行
grep -v "^$" 路径 把空格全部消除
grep "^#" 路径 显示注释
grep -v "^#" 路径
grep -v "^#" /etc/yum.conf | grep -v "^$" 过滤注释和空行
二、文本处理工具
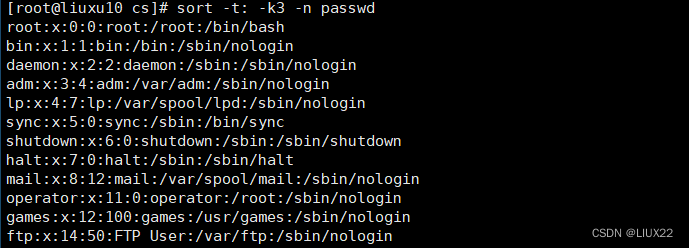
1、sort排序
sort是一个一行为单位对文件进行排序的工具,也可以根据不同的数据类型来排序。例如:数据和字符的排序就是不一样的
sort [选项] 参数
参数如下:
-b 忽略每行前面开始出的空格字符。
#无法读取zn_UTF-8汉字
-k:指定排序区域,在那个区间排序
#可以读取zn_UTF-8汉字
-n 依照数值的大小排序。
-u 意味着是唯一的(unique),输出的结果是去完重了的。
-o<输出文件> 将排序后的结果存入指定的文件。
-r 以相反的顺序来排序。
-t<分隔字符> 指定排序时所用的栏位分隔字符。
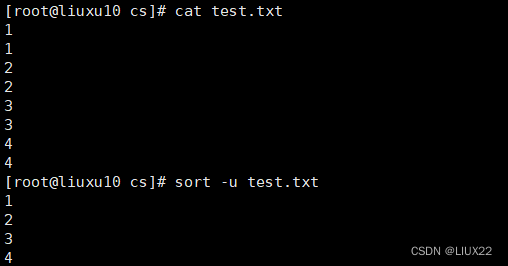
2、uniq去重
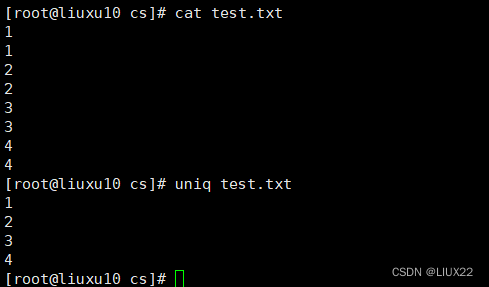
uniq主要是用于去除连续的重复行
注意,是连续的行,所以通常和sort命令结合使用先排序使之变成连续的行再执行去重操作,否则不连续的重复行他不能去重。
uniq [选项] 参数
常用参数如下:
-c:在每列旁边显示该行重复出现的次数。
-d:仅显示重复出现的行列。
-f:忽略比较指定的栏位。
-s:忽略比较指定的字符。
-u:仅显示出一次的行列
只能将连续的重复去掉
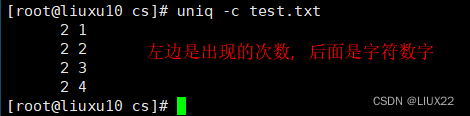
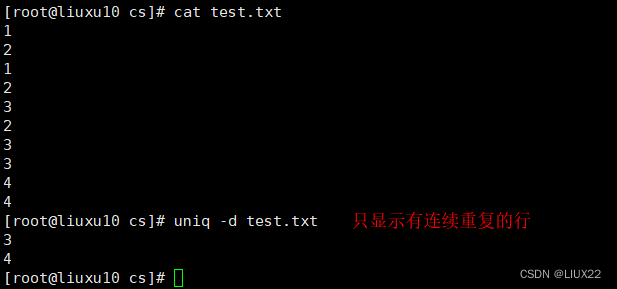
3、tr修改
tr可以用一个字符来替换两一个字符,或者可以完全出去一些字符,也可以用它来出去重复字符
tr [选项]... SET1 SET2
#从标准中替换、缩减和(或)删除字符,并将结果写到标准输出
常用参数如下:
-c:反选设定字符。也就是符合 SET1 的部份不做处理,不符合的剩余部份才进行转换
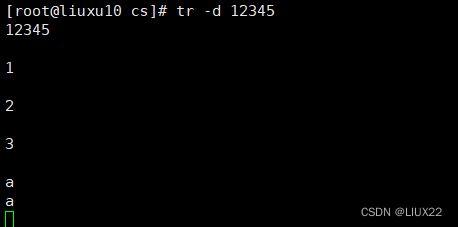
-d:删除指令字符
-s:缩减连续重复的字符成指定的单个字符
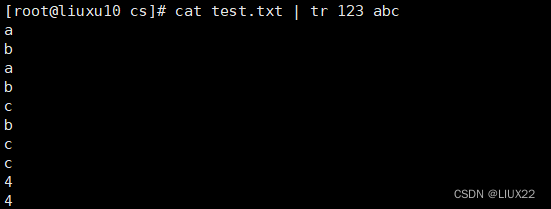
将1 2 3 转换成a b c
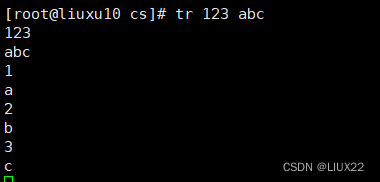
当转换数值不足时,将一直转换成最后一个
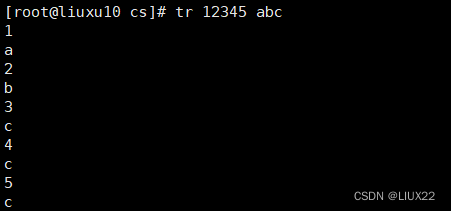
将test.txt文本中的 1 2 3 转换成a b c
删除匹配的字符
4、cut截取
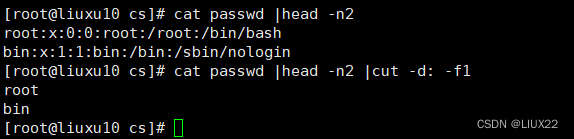
cut是常见的截取工具
cut命令从文件的每一行剪切字节、字符和字段,并将这些字节、字符和字段写至标准输出,如不制定File的参数,cut命令将会读取标准输入,所以必须要指定-b、-c或-f作为其标志
参数说明
-b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。
-c :以字符为单位进行分割。
-d :自定义分隔符,默认为制表符。
-f :与-d一起使用,指定显示哪个区域。
-n :取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的范围之内,该字符将被写出;否则,该字符将被排除
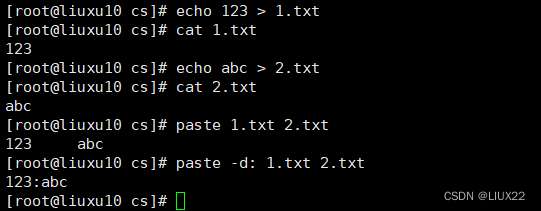
5、paste粘贴
-d 指定分隔符

















 2152
2152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









