







文章目录
前言
本文对分布式系统下,强一致性模型(cp)之Raft 算法的实现进行介绍。
一、Raft 是什么:
Raft 是工程上使用较为广泛的 强一致性、去中心化、高可用 的分布式协议,用于管理副本复制(Log Replication)。相比传统的 Paxos 算法,Raft 将大量的计算问题分解成为了一些简单的相对独立的子问题,并有着和 Multi-Paxos 同样的性能。
二、Raft的工作原理:
CP协议raft 实现动画版: http://thesecretlivesofdata.com/raft/
2.1 Raft 节点的3中状态:
- Leader:Leader 会一直工作,直到失败。Leader 节点负责处理所有客户端的请求,定期向集群中的 Follower 节点发送心跳消息,证明自己还健在。
- Follower:Follower 只响应来自其他服务器的请求。Follower 节点不处理 Client 的请求,而是将请求重定向给集群的 Leader 节点,由 Leader 节点进行请求处理。
- Candidate:如果 Follower 长时间没有收到任何通信,它将成为 Candidate 并发起选举。获得多数选票的 Candidate 成为新的 Leader。
2.2 集群启动 leader 节点的选举:
-
集群中的节点一开始都是 fllower 从节点;
-
当集群中接收不到leader 节点的心跳,在选举的超时时间过完后,触发选举,此时从节点变为候选节点
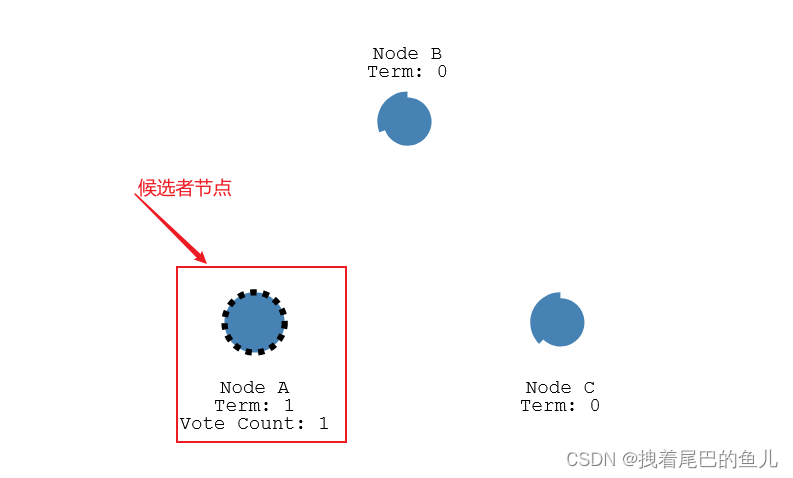
-
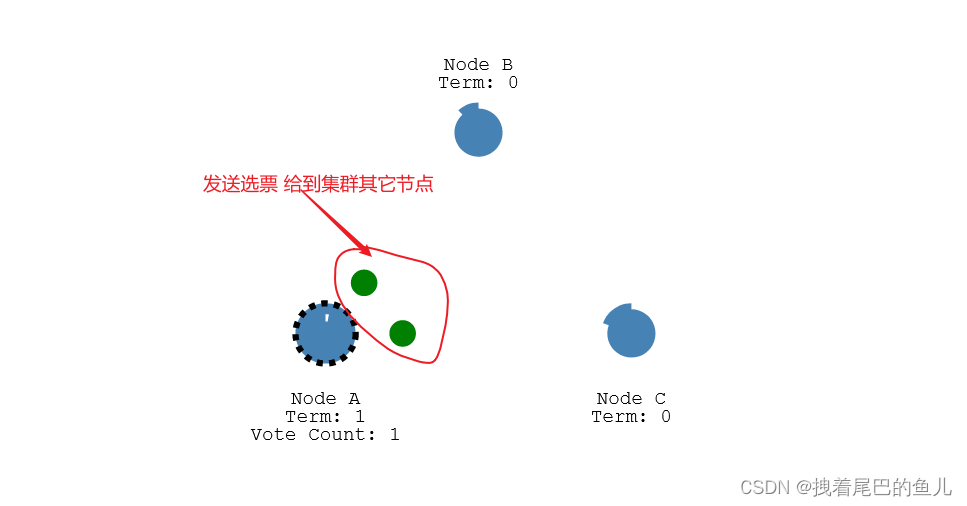
从节点发送选举投票给到其它的节点(自己先投给自己一票),其它节点接到请求并返回值;
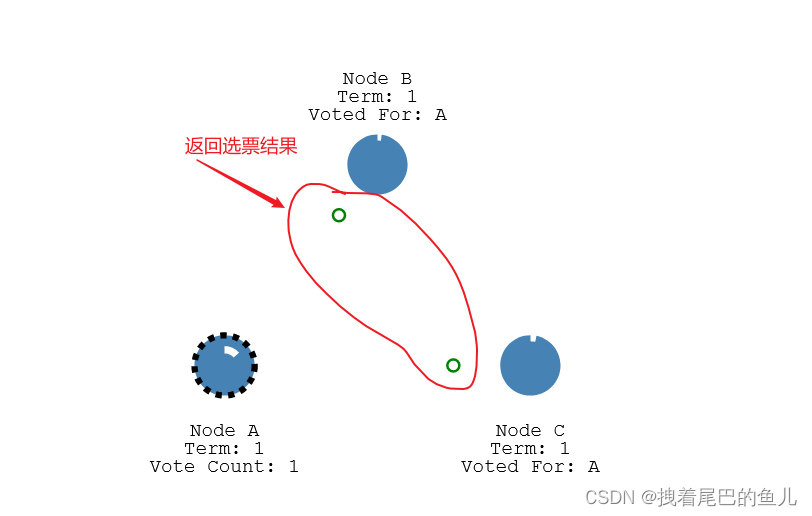
 - - 返回选票结果:
- - 返回选票结果:
投票限制:
1) 在任一任期内,单个节点最多只能投一票;
2) 候选人知道的信息不能比自己的少;
3) first-come-first-served 先来先得;
投票结果:
(1) 收到majority的投票(含自己的一票),则赢得选举,成为leader;
(2)被告知别人已当选,那么自行切换到follower;
(3)一段时间内没有收到majority投票,则保持candidate状态,重新发出选举;
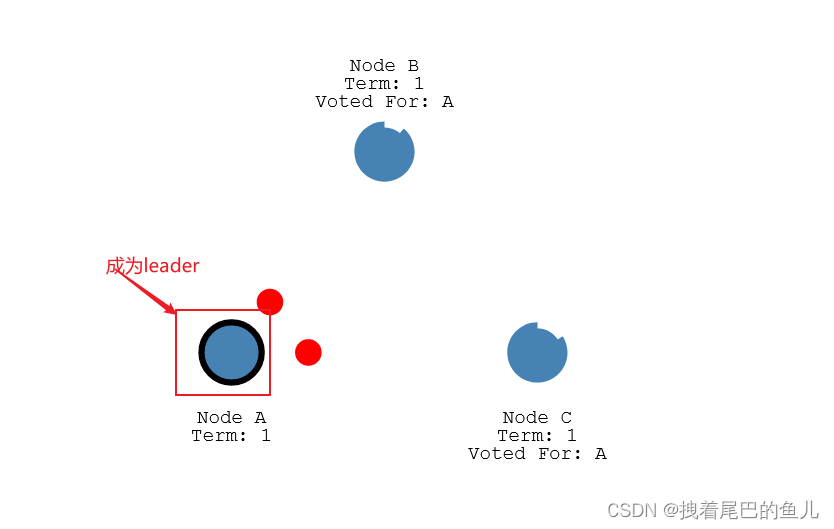
- 改从节点获取到集群内过半节点的投票返回,则晋升为leader 节点,然后发送心心跳给到从节点;
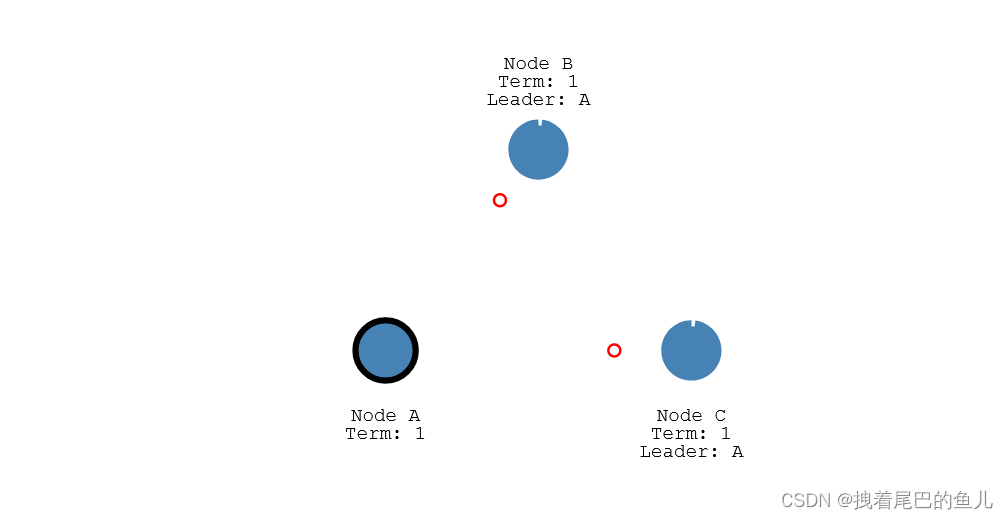
2.3 数据的同步(日志复制):
-
将数据发送到leader节点,leader 节点将数据写入到log 日志中;
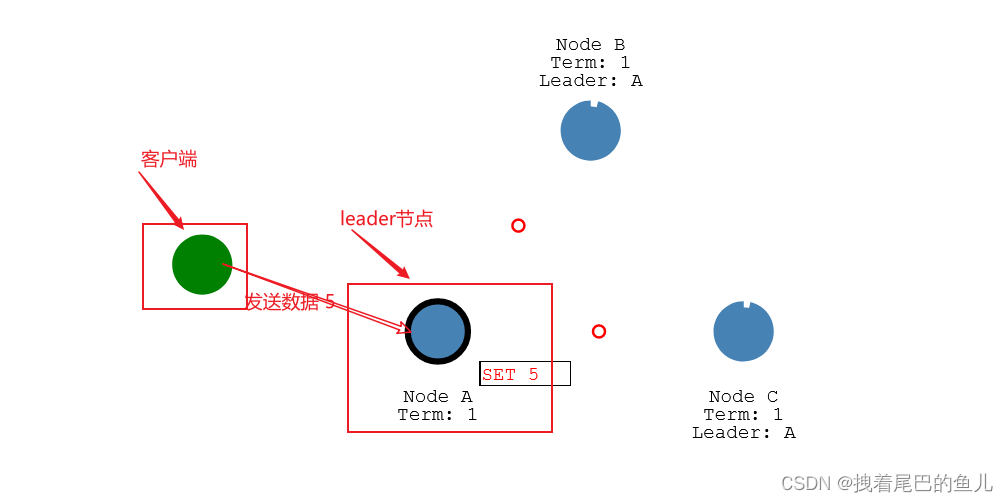
-
日志写入完成,将日志数据发送给到其它的从节点(在心跳中将数据一并传输);
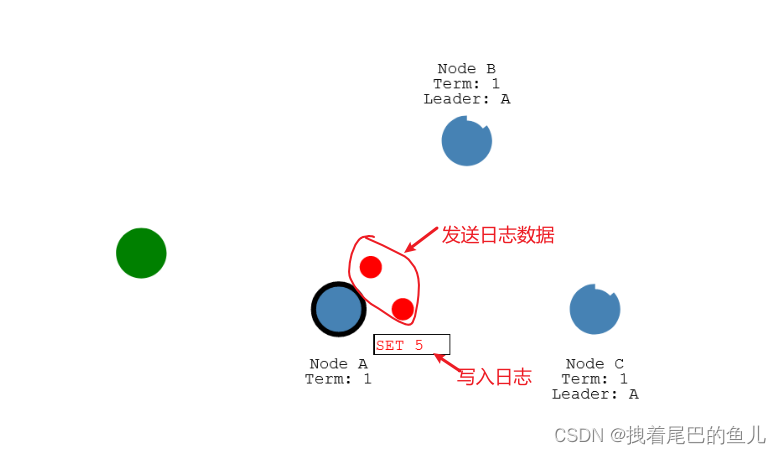
-
从节点写入数据到各自 的日志中,然后返回成功的状态给到leader 节点;
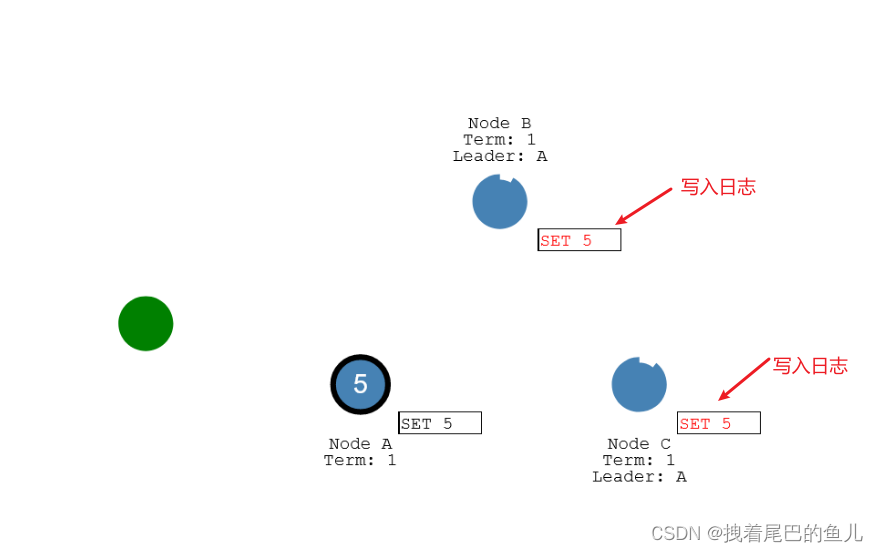
-
leader 接收到集群节点过半都已经成功,则将本机数据进行更新(提交),响应客户端,并发送命令到从节点,各从节点完成数据更新;
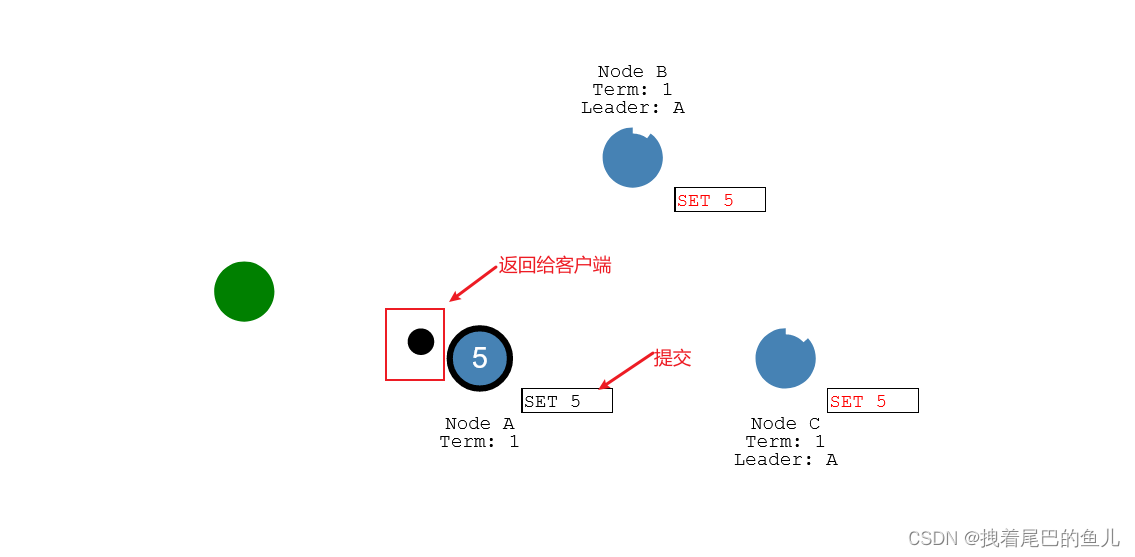
-
如果不是过半成功,则不更数据,并并发送命令到从节点,各从节点不进行数据更新;
2.4 leader 重新选举:
当出现网络故障或者leader 挂掉时,leader和follower 之间的心跳超时,触发leader的重新选举:
- 从节点在重置自己成为候选者的时间到达后,成为候选者;
- 然后发送选举给到集群内其它节点;
- 获取半数投票成为leader 节点,然后发送心心跳给到从节点;
- 从节点接收到leader 心跳,则重置自己成为候选者的时间;
2.5 网络分区故障:
当出现网络分区,A&B,C&D&E,则会出现两个leader节点;
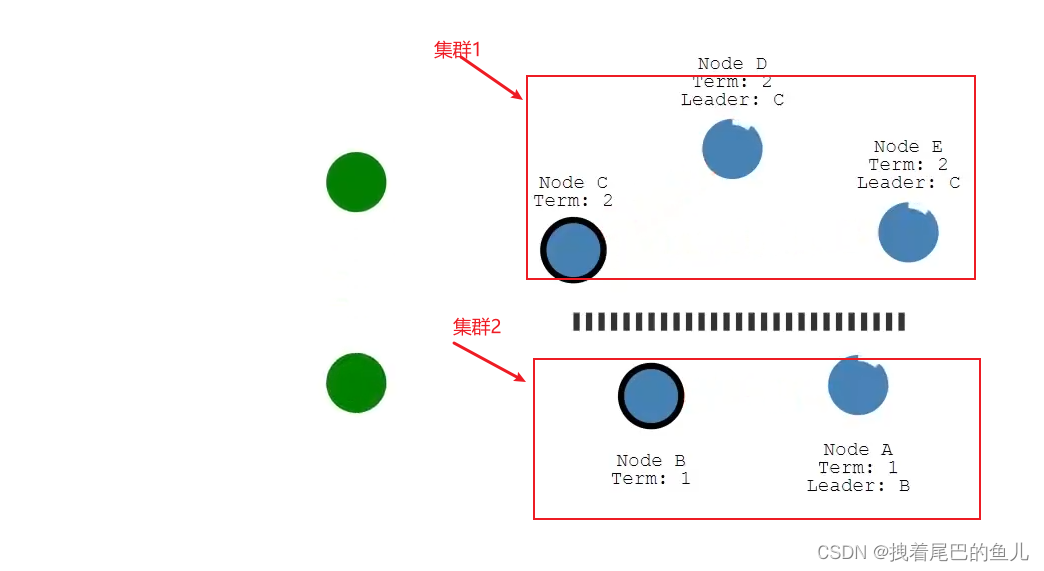
此时如果客户端,发送数据给到 NodeB 不满足过半写入,则数据写入不成功;如果发送给到 NodeC ,有3个节点(5/2 +1 =3)则数据写入成功;
网络分区恢复:
- 则通过一定的规则得到唯一的一个新leader 节点;
- 旧的leader节点数据及旧的从节点,则回滚到没有没有提交的日志;然后接收新的leader 的日志数据;
2.6 超时时间控制:
- 选举的超时时间:每个节点从fllower 变为 候选节点 ,每个节点的时间在150ms 和300 ms 之间;减少多个节点同时进行选举投票,产生候选者获取到投票数量相同 从而触发再次选举进入死循环;
- 如果产生候选者获取到投票数量相同,则等待选举的超时时间之后重新进行投票选举;
总结:
raft 通过投票(过半)当选为leader 节点,只有leader 节点负责对客户端的数据写入操作;leader 在接收到数据之后,现在本地记录日志,然后将日志信息跟随心跳一起发送到集群内的从节点,从节点完成日志数据记录后,返回leader,只有过半的从节点都写入日志成功,则进行数据提交(数据真正的写入成功),否则 进行数据的回滚;当心跳超时时则会重新触发leader 的选举。

















 647
647

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









