



本文通过教育孩子与训练AI的比喻,详细介绍了大模型微调的全流程。作者使用魔搭平台和LLaMa Factory工具,从环境搭建、模型下载、数据准备、模型训练到本地测试和模型导出,手把手指导读者完成微调过程。即使是零基础小白,也能按照文章步骤体验微调全过程,了解预训练、微调和RLHF三个阶段,并成功训练自己的大模型。
1、什么是“微调”?
首先,我们先大致了解一下,什么是微调?常规大模型语言模型的训练路径分为以下几个阶段:
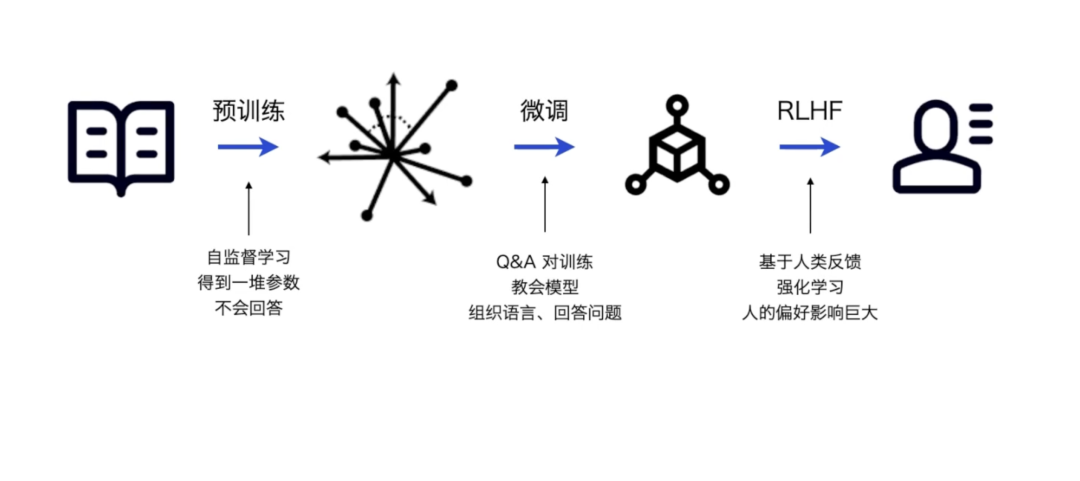
简单的说,以我们养娃来打个比方:
1. 预训练(通识教育)
- 模型:通过自监督学习(如阅读海量文本),掌握基础语言规则,但还不会针对具体问题回答。
- 比喻:就像孩子上学前大量听大人说话、读绘本,积累了词汇和常识,但还不会完整表达观点。
2. 微调(专项训练)
- 模型:用Q&A对训练,教会它如何组织语言、精准回答问题。
- 比喻:类似家长或老师通过“问答练习”教孩子:
- 问:“天空为什么是蓝色的?”
- 教:“因为阳光散射…”。
→ 孩子会使用专业的术语,清晰高效的表达。
3. RLHF(品德教育)
- 模型:根据人类反馈调整回答,符合社会偏好(如更友善、更严谨)。
- 比喻:当孩子说“因为天空喜欢蓝色!”,家长纠正:
- “答案要有科学依据哦!”
→ 孩子学会“不仅回答,还要回答得靠谱”。
那么,聪明的你,一定会明白了,大模型什么时候需要微调呢?一般会在输出要求严格的垂直场景,或者希望更效率的任务,快速输出结果。在企业的 Ai 落地过程中,还是较为广泛,那么,我们如何微调呢?下面跟着我们的步骤开始吧!
2、免费构建微调的实例环境
1. 打开魔搭构建实例
打开:https://modelscope.cn/my/mynotebook/preset
关联你的阿里云账号,选第二个gpu环境👇
注意这个实例免费,但是过一段时间就会释放,别怕搞错什么东西!
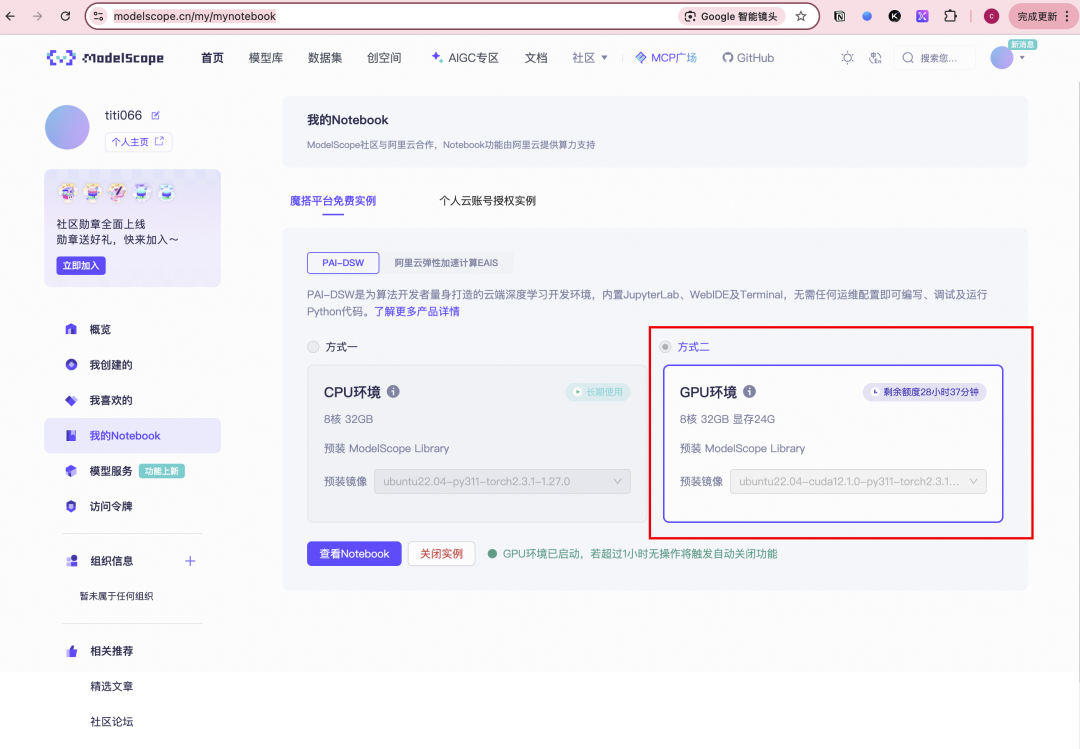
两三分钟后,点击查看notebook
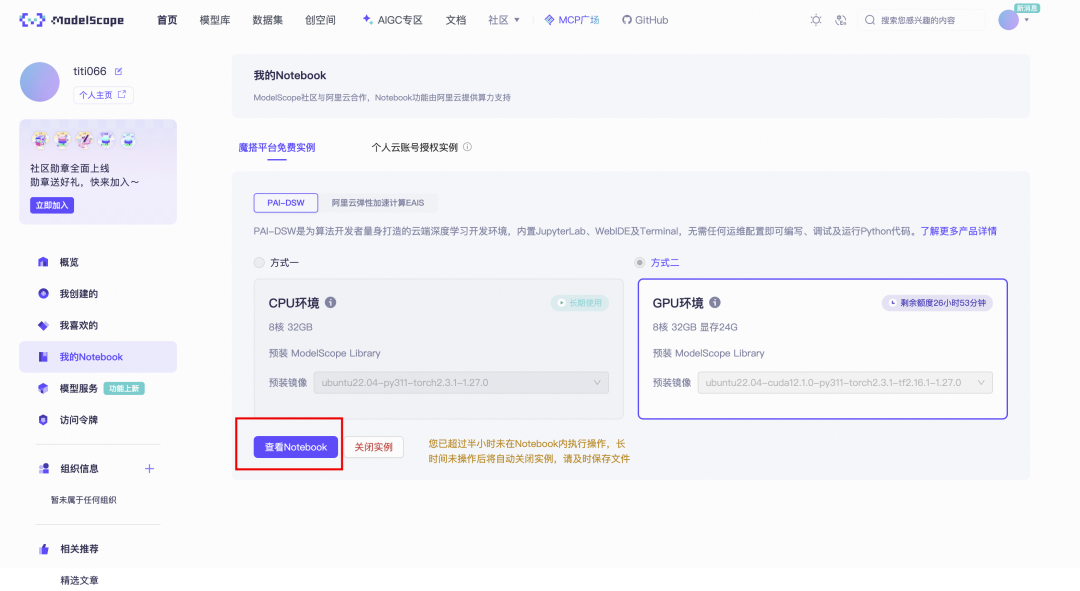
这些大图标就是你的软件,侧边栏就是文件夹,下面的$符号logo,就是终端。相当于在云端给你装了个电脑。
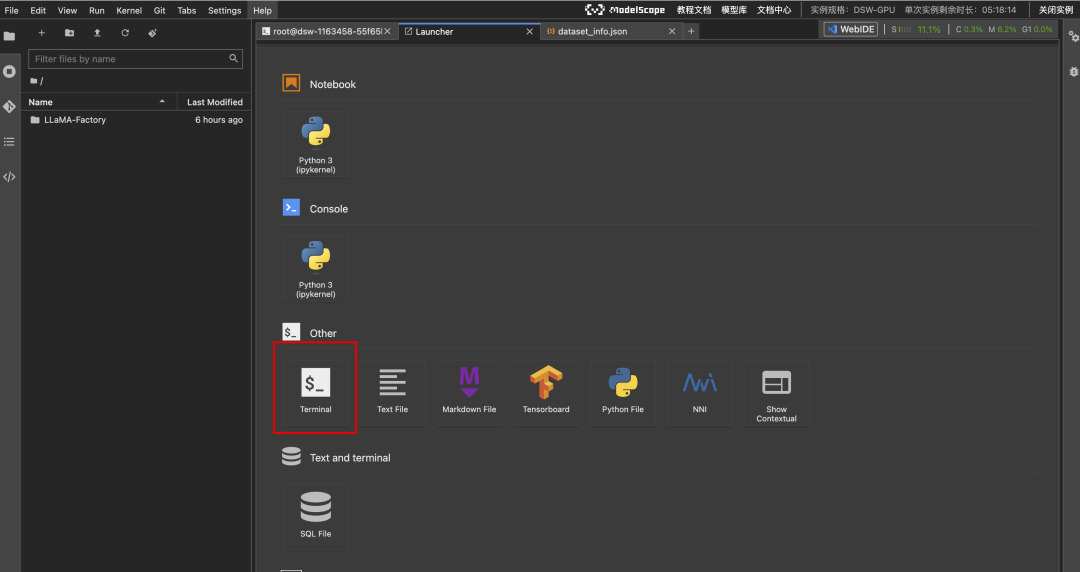
点击终端,进入后,我们就可以开始配置相关的环境啦
2、下载模型、创建模型文件夹
接着下载LLaMA-Factory代码。
我们只用复制不带#的代码就可以了。
安装依赖的环节会等待大概20分钟,不用怀疑,只要输入的指令没有反馈,就耐着性子,继续等待~~千万别急。
# 克隆LLaMA Factory 开源框架
git clone https://github.com/hiyouga/LLaMA-Factory.git
# 进入项目的目录
cd LLaMA-Factory
#创建虚拟环境
python -m venv .venv
#激活虚拟环境
source .venv/bin/activate
# 安装依赖(这一步很漫长,如果出错用下面环境冲突的指令)
pip install -e ".[torch,metrics]"
# 如果报错,环境冲突用改用这个解决
pip install --no-deps -e .
过程中如果缺少什么依赖,或者提醒做什么升级,照做就是!
会看到已经开始下载了,左边也多了一个文件夹。

持续安装等待到这个状态:
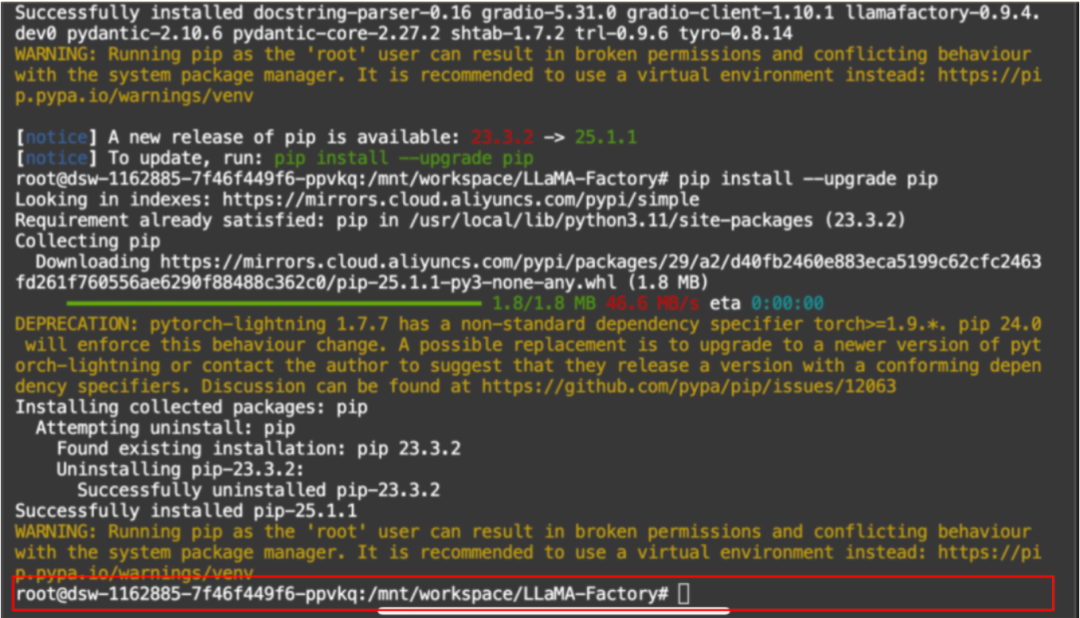
创建一个新的文件夹,命名为 newmodels,并下载模型,为了减少等待时间,以 Qwen2.5-0.5-instruct为例,这是一个最低参数的模型。
git clone https://www.modelscope.cn/Qwen/Qwen2.5-0.5B-Instruct.git
3、训练数据集准备
我们同样前往魔搭的数据集中,随便下载一个不到 300 行的数据集(数量少,速度快)下载:https://modelscope.cn/datasets/meadhu/taobao-positive-sentence/files
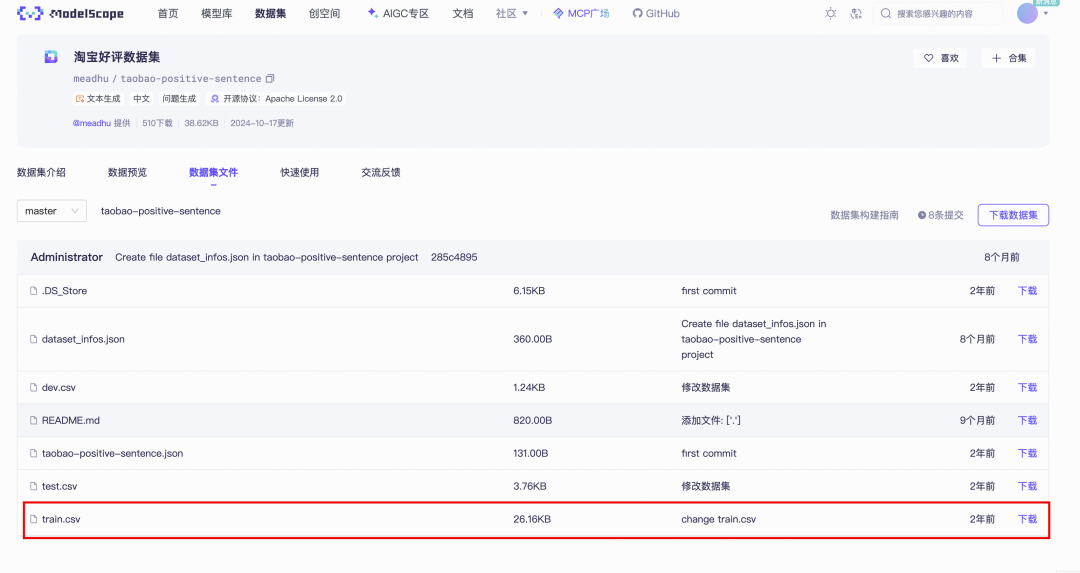
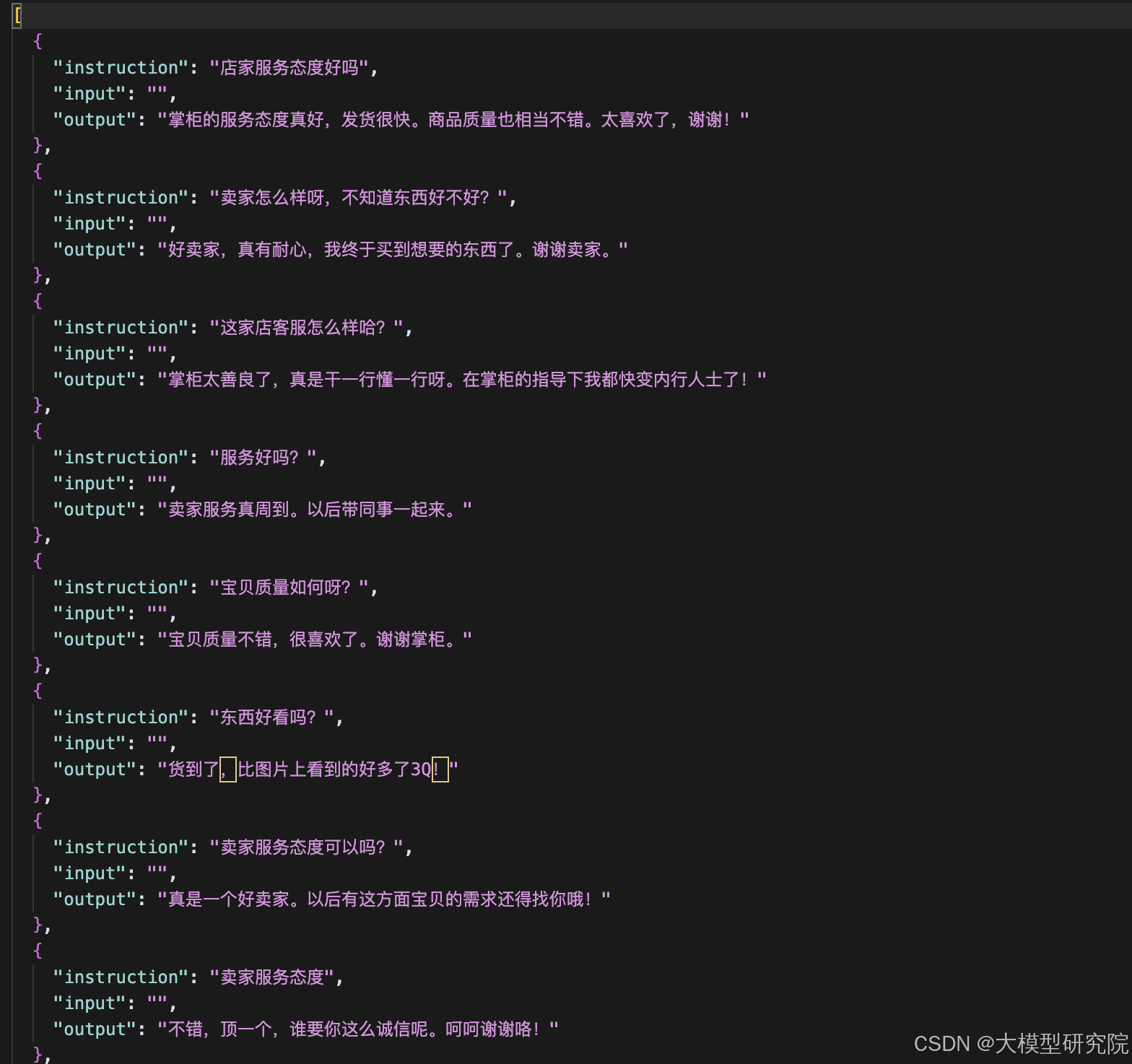
下载后我们注意格式是 csv,用于训练需要是 json格式,这里我们需要预处理,可以让勤劳的ds写一个处理脚本运行即可,保存文件名为train_converted.json 。

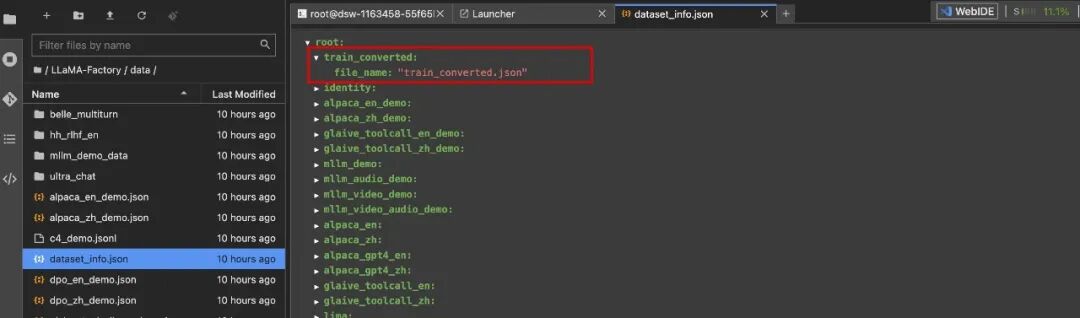
因为系统自带dataset_info.json,从目录中找到它,这是一个数据集的索引。我们需要将新创建好的数据集train_converted.json再此注册,直接把数据集名称写入dataset_info.json文件即可。
3、一切就绪,开始训练
返回到我们的训练LLaMA-Factory 文件夹
## 回到LLaMA-Factory 文件夹,如果你已经在LLaMA-Factory 文件夹,就不要用这个指令了cd ..
# 打开训练的 webuillamafactory-cli webui
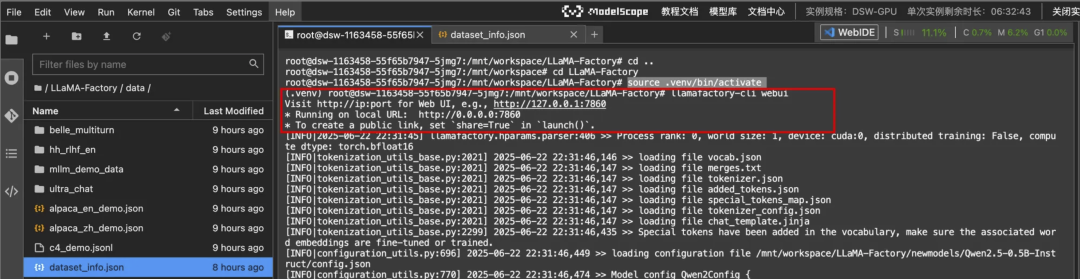
点击这里反馈的网址,即可进入,设置自己的相关信息路径
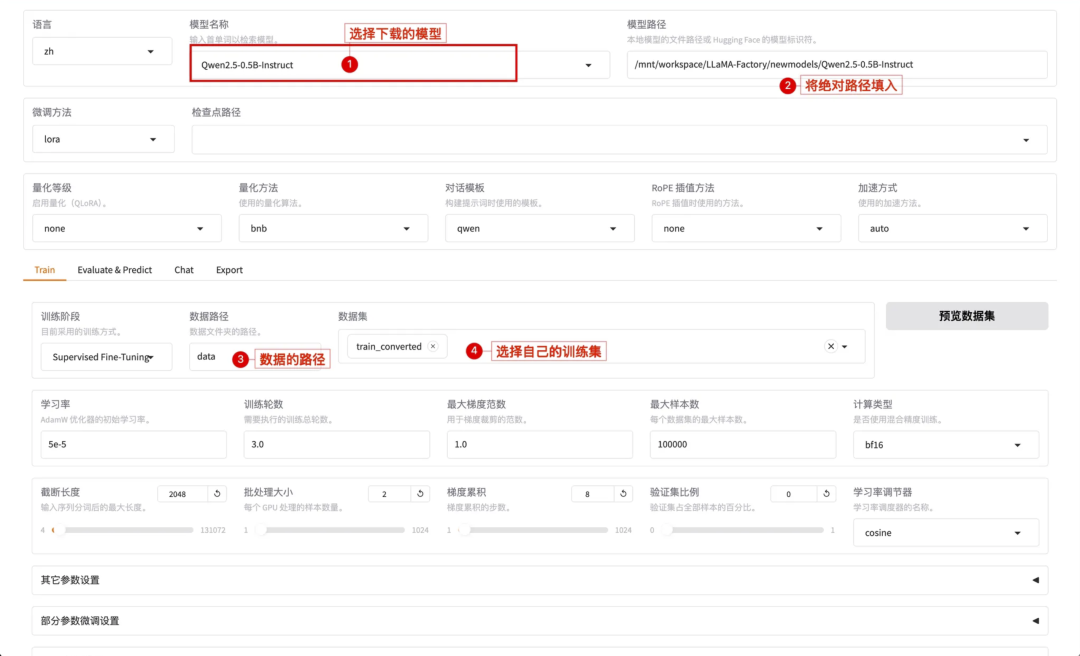
设置好后,就可以开始让它为你训练啦!

一通操作猛如虎,你会看到你的终端咔咔干活儿,
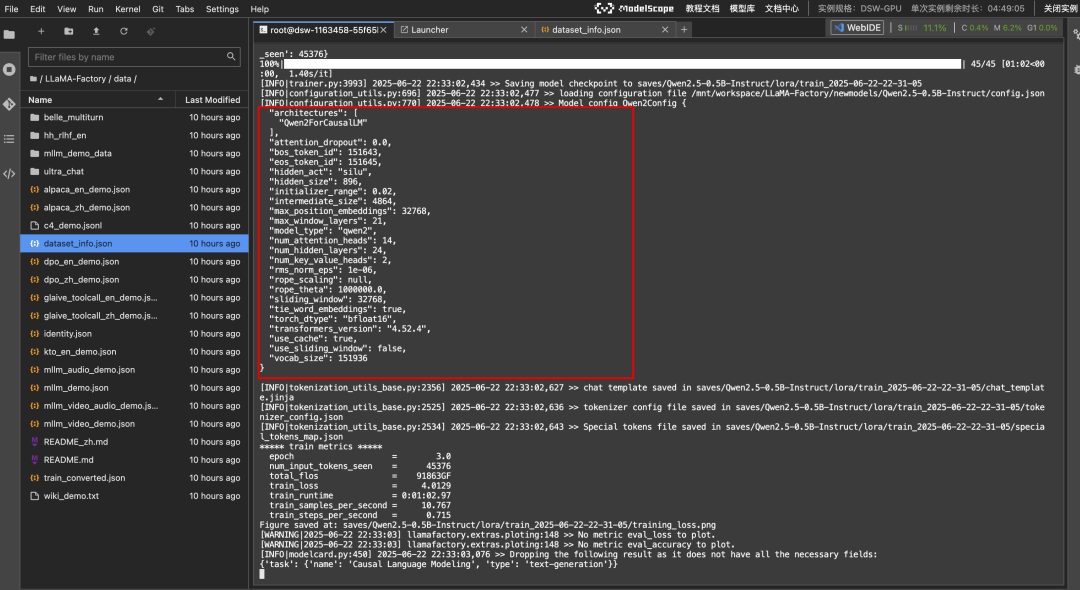
你在自己的 webui 上也可以看到最终的结果:
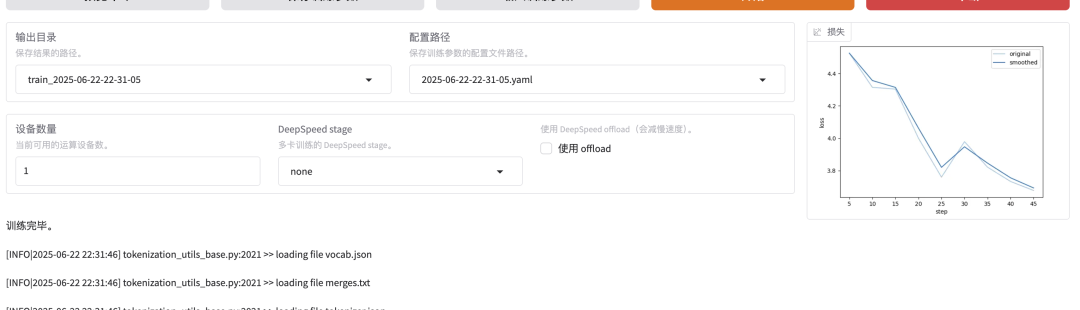
这里模型损就是失衡量预测与真实值的误差,训练目标是最小化损失;但并非越小越好,太小就会是我们所说的“过拟合”。现在我们这个数据这样的结果就算是不错~
4、 本地测试聊天,看看它的表现如何
我们切换到chat,试试模型有没有记住我们刚才提供的数据。
点击检查点路径👉chat👉加载模型
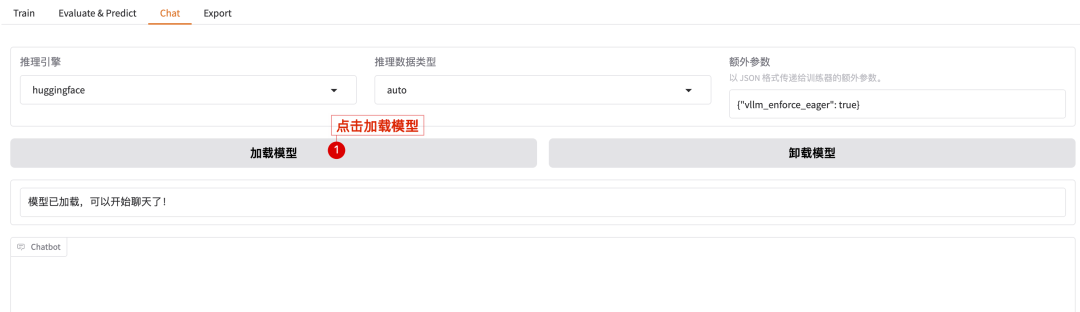
接着我们就可以看到它的回答是基于我们的训练数据的(咱们这个模型因为基础参数小,加上训练的数据集少,所以不怎么聪明的样子,正常会是一个相关的回答,我这个数据集因为写文章训练了多轮,所以它主键走向了魔幻……)
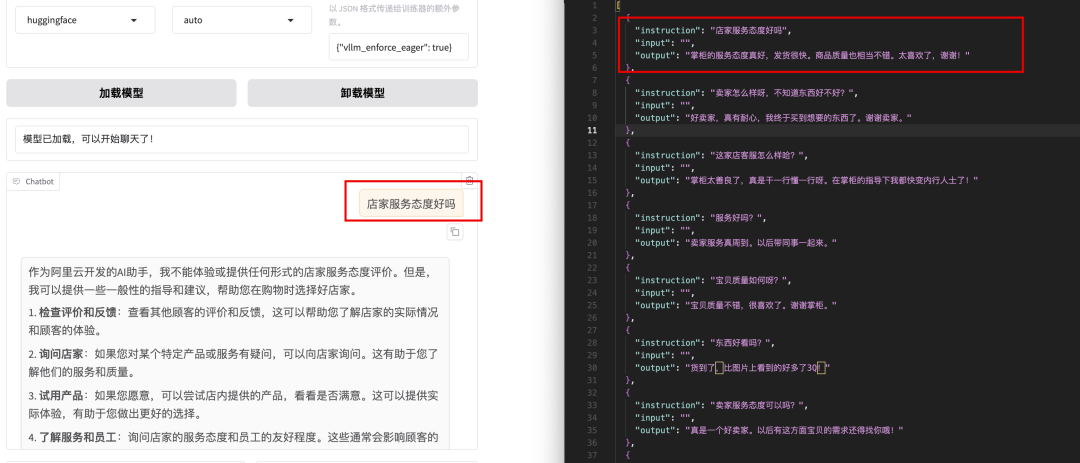
总体上,我们就认为训练成功啦~~
5、 导出模型
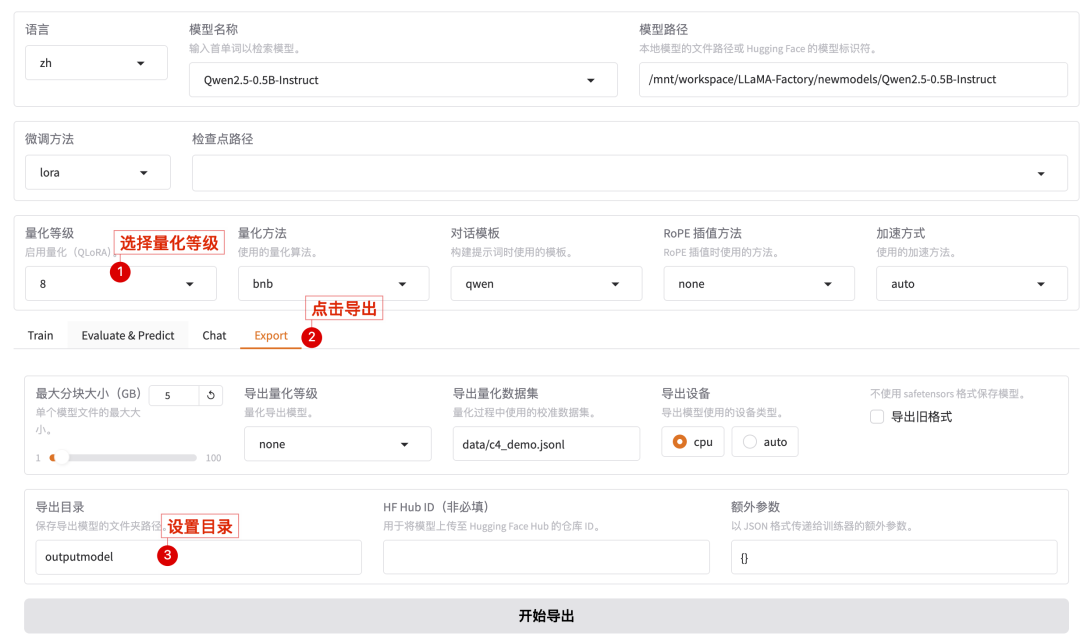
1、 创建导出目录
导出目录命名为outputmodel
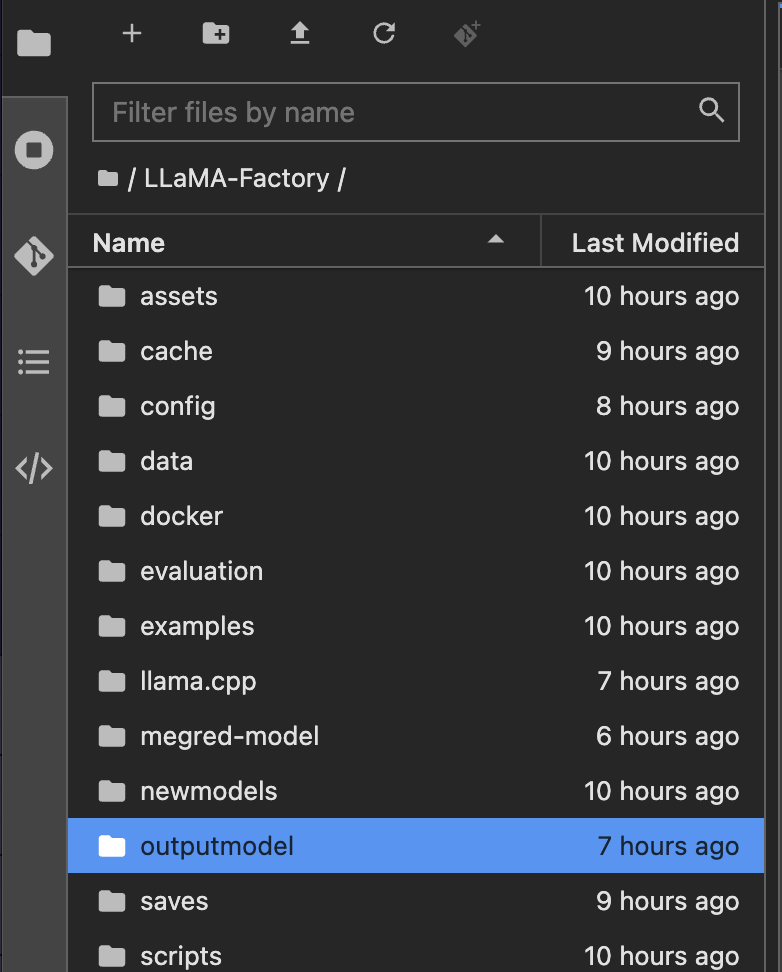
导出成功后再看notebook就会发现多了一个文件夹
2、 转化模型格式,安装GGUF库
回到终端,LLaMA-Factory路径下,执行以下命令
## 新打开一个终端
## 不管你在哪,运行这个指令回到根目录
cd /mnt/workspace/LLaMA-Factory
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp/gguf-py
pip install --editable .
执行完之后,就会发现目录多出一个 cpp 的文件夹
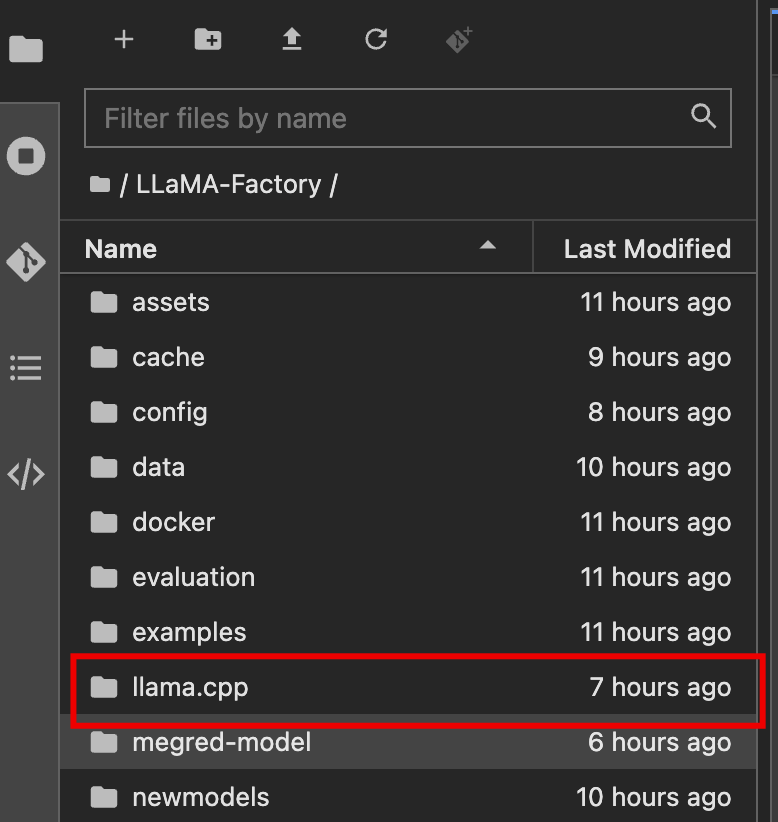
首先会到LLaMA-Factor下面创建一个叫megred-model-path的文件夹
然后回到llma.cpp文件路径下,一次性复制下面三行代码运行转换格式
3、 转换格式
#再回到llama.cpp文件下
cd ..
#然后运行Python 代码,路径改成你的其中有两个路径:
# 第一个路径`/mnt/workspace/LLaMA-Factory/outputmodel`改成你刚刚导出的模型路径
# 第二个路径`--outfile /mnt/workspace/LLaMA-Factory/megred-model-path`是导出 GGUF 文件的路径,可以提前创建一个
#下面三行全复制,粘贴到终端一次运行
python convert_hf_to_gguf.py /mnt/workspace/LLaMA-Factory/outputmodel \
--outfile /mnt/workspace/LLaMA-Factory/megred-model-path \
--outtype q8_0
他就会直接将训练好的模型,为你保存到/mnt/workspace/LLaMA-Factory/llama.cpp
这个gguf就是常用的大模型格式,你粗略理解成大佬梁文峰老师天天忙的就是gguf这些。点击下载~
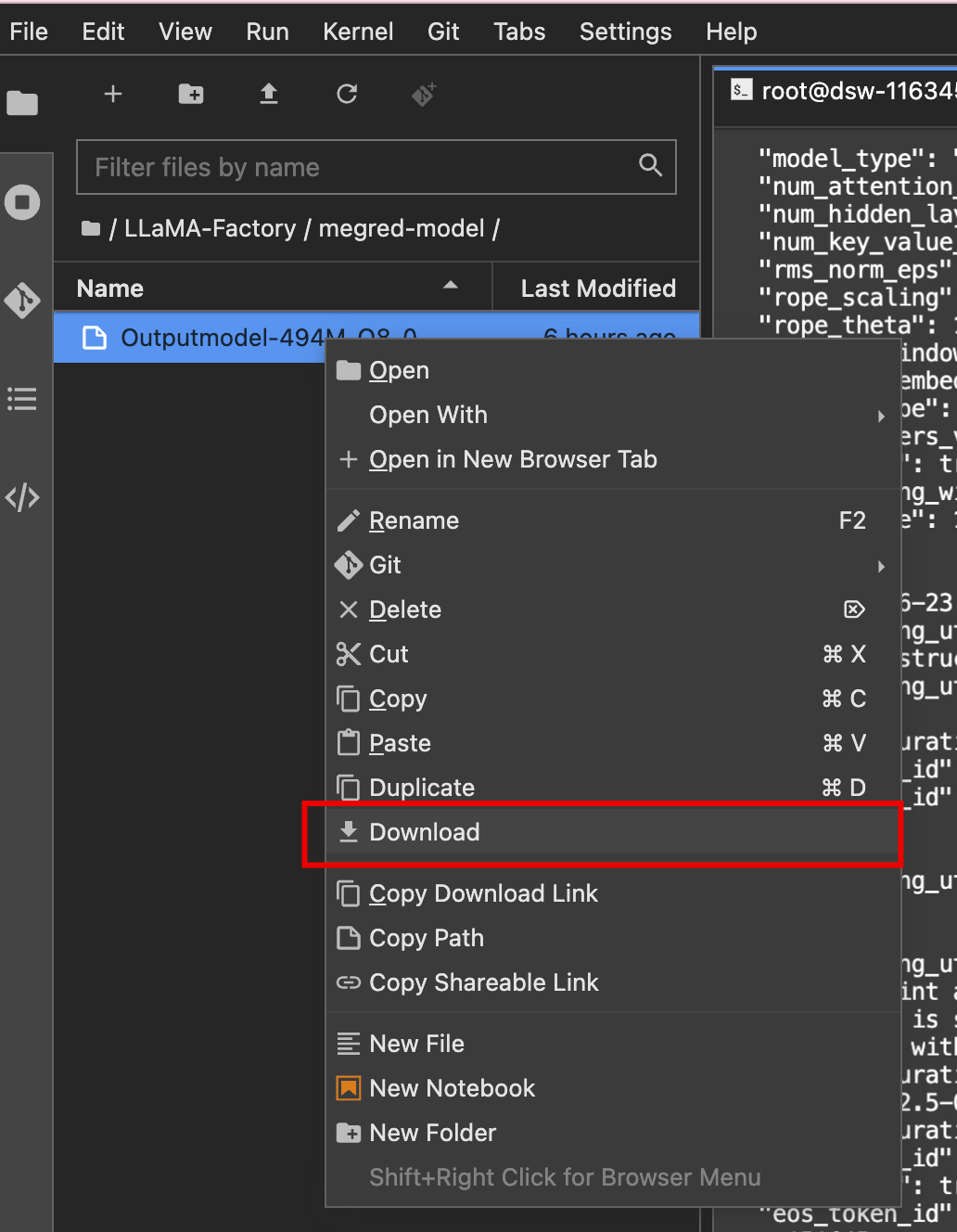
6、 使用模型,检验效果
最方便简单的方式,打开https://jan.ai/,它可以直接使用模型
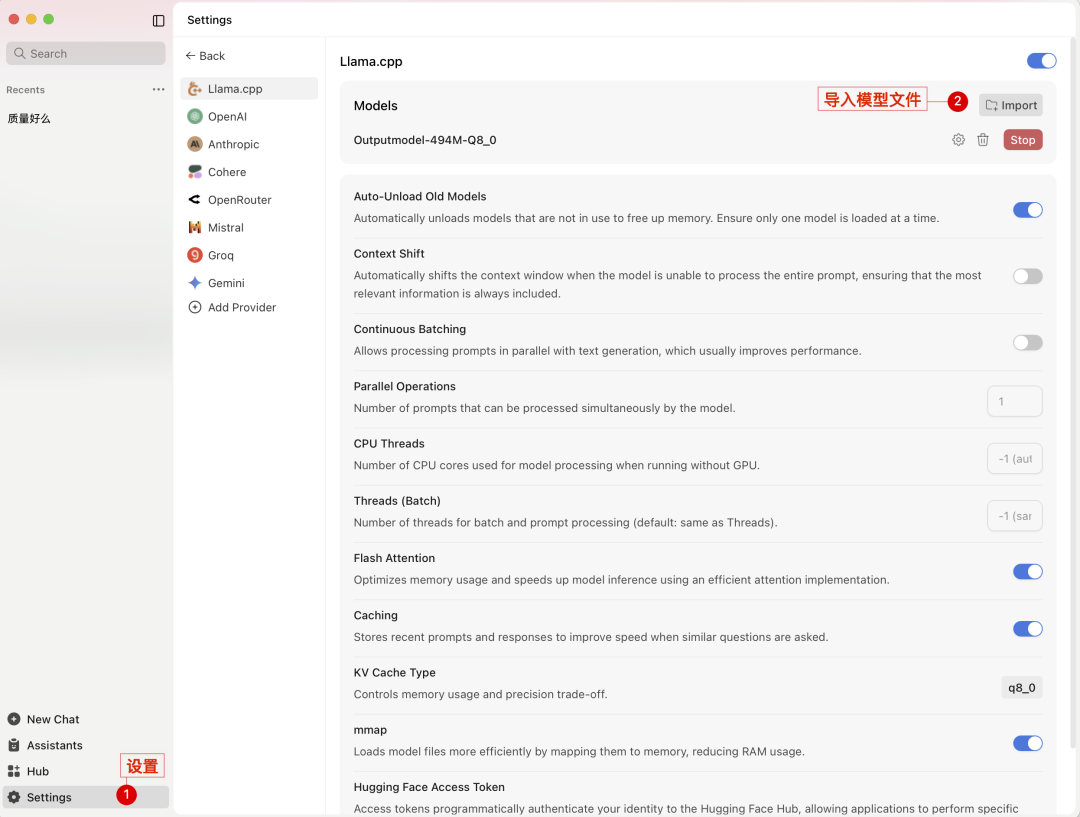
setting—— Molde Provider——import一下就可以了
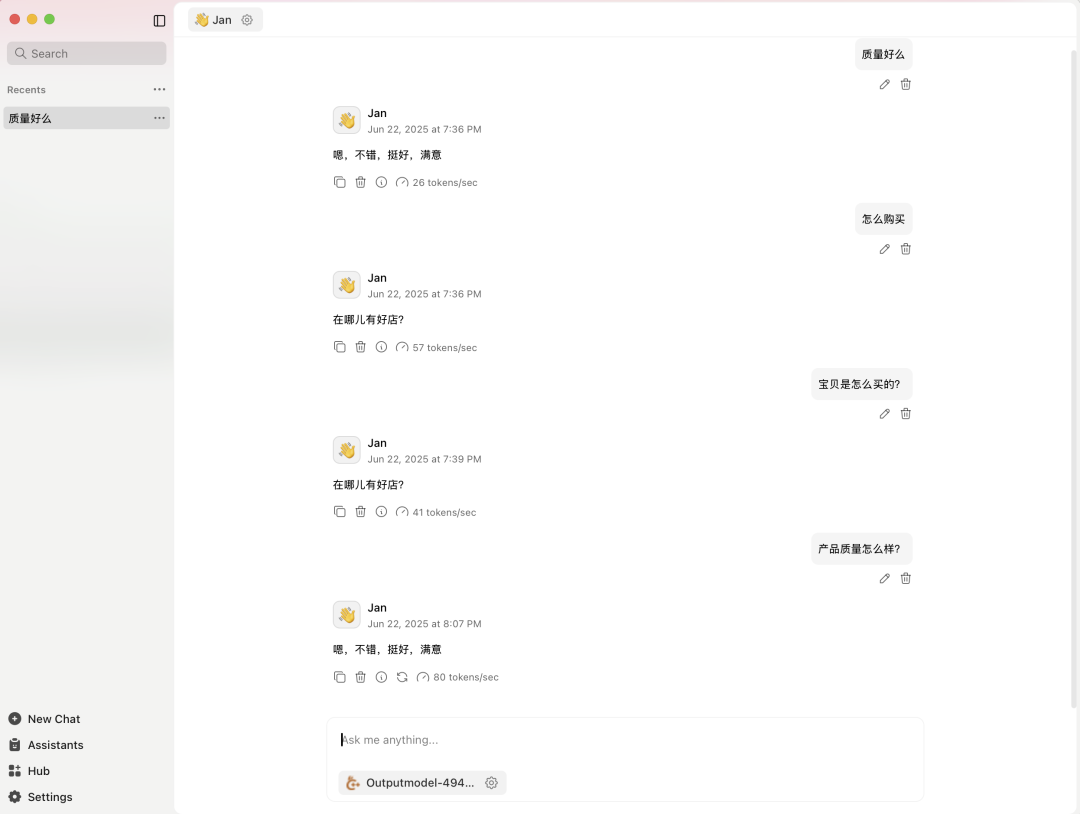
导入刚才下载的 GGUF 文件,点击 start,前往对话中,问个问题,嗯,是自己亲生打造的傻孩子没错了~~
如果你有 ollama 的客户端,也可以将文件再次转换后,导入到 ollama 中,进而被 dify 或者 cherrystudio 调用使用,我这里在 cherrystudio 中尝试了之后,发现傻孩子变成了疯孩子,一发不可收拾
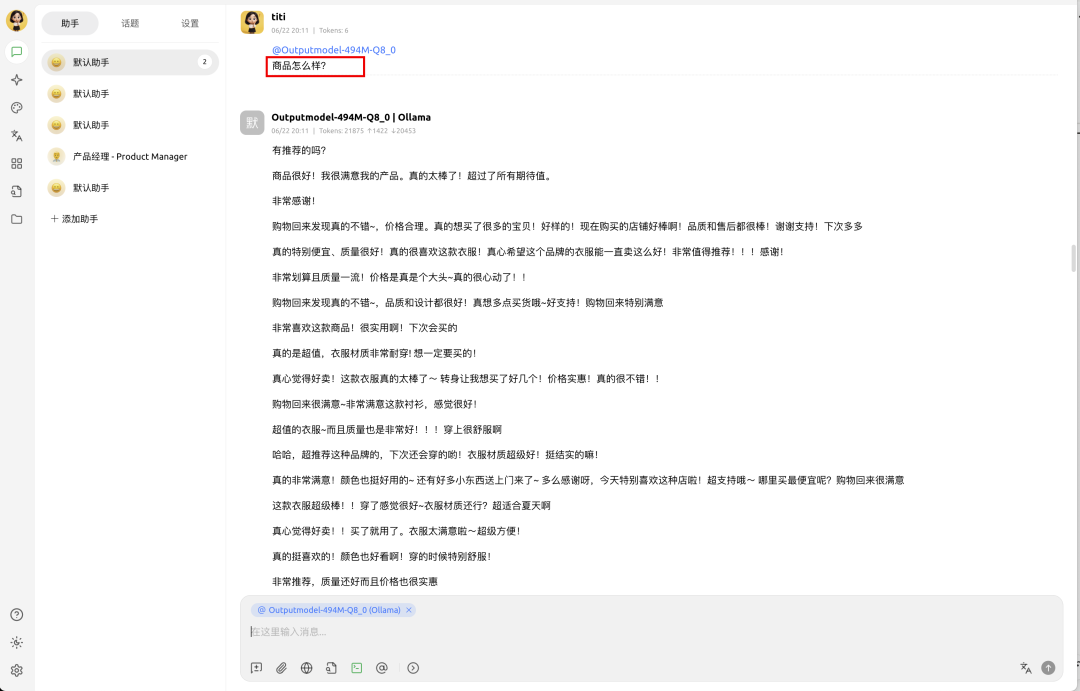
怀疑可能和默认系统提示词导致的,或者是在文件转换时出问题了。这里就不再赘述啦~~
ok,这就是我们模型预训练最最最简单的一个最简单的一个流程体验。都有工程师为你完成😄😄~
如何从零学会大模型?小白&程序员都能跟上的入门到进阶指南
当AI开始重构各行各业,你或许听过“岗位会被取代”的焦虑,但更关键的真相是:技术迭代中,“效率差”才是竞争力的核心——新岗位的生产效率远高于被替代岗位,整个社会的机会其实在增加。
但对个人而言,只有一句话算数:
“先掌握大模型的人,永远比后掌握的人,多一次职业跃迁的机会。”
回顾计算机、互联网、移动互联网的浪潮,每一次技术革命的初期,率先拥抱新技术的人,都提前拿到了“职场快车道”的门票。我在一线科技企业深耕12年,见过太多这样的案例:3年前主动学大模型的同事,如今要么成为团队技术负责人,要么薪资翻了2-3倍。
深知大模型学习中,“没人带、没方向、缺资源”是最大的拦路虎,我们联合行业专家整理出这套 《AI大模型突围资料包》,不管你是零基础小白,还是想转型的程序员,都能靠它少走90%的弯路:
- ✅ 小白友好的「从零到一学习路径图」(避开晦涩理论,先学能用的技能)
- ✅ 程序员必备的「大模型调优实战手册」(附医疗/金融大厂真实项目案例)
- ✅ 百度/阿里专家闭门录播课(拆解一线企业如何落地大模型)
- ✅ 2025最新大模型行业报告(看清各行业机会,避免盲目跟风)
- ✅ 大厂大模型面试真题(含答案解析,针对性准备offer)
- ✅ 2025大模型岗位需求图谱(明确不同岗位需要掌握的技能点)
所有资料已整理成包,想领《AI大模型入门+进阶学习资源包》的朋友,直接扫下方二维码获取~

① 全套AI大模型应用开发视频教程:从“听懂”到“会用”
不用啃复杂公式,直接学能落地的技术——不管你是想做AI应用,还是调优模型,这套视频都能覆盖:
- 小白入门:提示工程(让AI精准输出你要的结果)、RAG检索增强(解决AI“失忆”问题)
- 程序员进阶:LangChain框架实战(快速搭建AI应用)、Agent智能体开发(让AI自主完成复杂任务)
- 工程落地:模型微调与部署(把模型用到实际业务中)、DeepSeek模型实战(热门开源模型实操)
每个技术点都配“案例+代码演示”,跟着做就能上手!

课程精彩瞬间

② 大模型系统化学习路线:避免“学了就忘、越学越乱”
很多人学大模型走弯路,不是因为不努力,而是方向错了——比如小白一上来就啃深度学习理论,程序员跳过基础直接学微调,最后都卡在“用不起来”。
我们整理的这份「学习路线图」,按“基础→进阶→实战”分3个阶段,每个阶段都明确:
- 该学什么(比如基础阶段先学“AI基础概念+工具使用”)
- 不用学什么(比如小白初期不用深入研究Transformer底层数学原理)
- 学多久、用什么资料(精准匹配学习时间,避免拖延)
跟着路线走,零基础3个月能入门,有基础1个月能上手做项目!

③ 大模型学习书籍&文档:打好理论基础,走得更稳
想长期在大模型领域发展,理论基础不能少——但不用盲目买一堆书,我们精选了「小白能看懂、程序员能查漏」的核心资料:
- 入门书籍:《大模型实战指南》《AI提示工程入门》(用通俗语言讲清核心概念)
- 进阶文档:大模型调优技术白皮书、LangChain官方中文教程(附重点标注,节省阅读时间)
- 权威资料:斯坦福CS224N大模型课程笔记(整理成中文,避免语言障碍)
所有资料都是电子版,手机、电脑随时看,还能直接搜索重点!

④ AI大模型最新行业报告:看清机会,再动手
学技术的核心是“用对地方”——2025年哪些行业需要大模型人才?哪些应用场景最有前景?这份报告帮你理清:
- 行业趋势:医疗(AI辅助诊断)、金融(智能风控)、教育(个性化学习)等10大行业的大模型落地案例
- 岗位需求:大模型开发工程师、AI产品经理、提示工程师的职责差异与技能要求
- 风险提示:哪些领域目前落地难度大,避免浪费时间
不管你是想转行,还是想在现有岗位加技能,这份报告都能帮你精准定位!
⑤ 大模型大厂面试真题:针对性准备,拿offer更稳
学会技术后,如何把技能“变现”成offer?这份真题帮你避开面试坑:
- 基础题:“大模型的上下文窗口是什么?”“RAG的核心原理是什么?”(附标准答案框架)
- 实操题:“如何优化大模型的推理速度?”“用LangChain搭建一个多轮对话系统的步骤?”(含代码示例)
- 场景题:“如果大模型输出错误信息,该怎么解决?”(教你从技术+业务角度回答)
覆盖百度、阿里、腾讯、字节等大厂的最新面试题,帮你提前准备,面试时不慌!

以上资料如何领取?
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

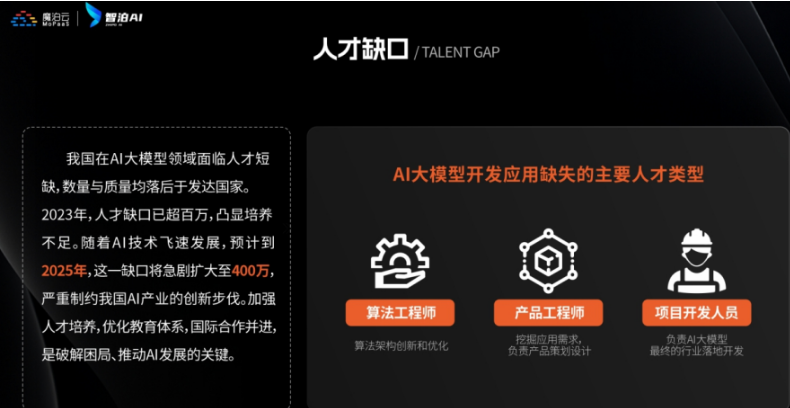
为什么现在必须学大模型?不是焦虑,是事实
最近英特尔、微软等企业宣布裁员,但大模型相关岗位却在疯狂扩招:
- 大厂招聘:百度、阿里的大模型开发岗,3-5年经验薪资能到50K×20薪,比传统开发岗高40%;
- 中小公司:甚至很多传统企业(比如制造业、医疗公司)都在招“会用大模型的人”,要求不高但薪资可观;
- 门槛变化:不出1年,“有大模型项目经验”会成为很多技术岗、产品岗的简历门槛,现在学就是抢占先机。
风口不会等任何人——与其担心“被淘汰”,不如主动学技术,把“焦虑”变成“竞争力”!

最后:全套资料再领一次,别错过这次机会
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









