








最近,DeepSeek这款国产开源AI大模型在国内外引发了广泛讨论。国内对其赞誉有加,而外网却有不少质疑之声。
关于DeepSeek的视频和文章层出不穷,但大多只是浮于表面,没有探讨其技术细节。今天,我们就来简单了解一下DeepSeek,看看它究竟是好是坏,以及它背后的技术原理和潜在价值。
一、技术剖析:优化与创新
DeepSeek基于Transformer模型,与GPT一样,其模型结构和本质并没有改变。它依然是通过多头注意力机制等技术实现的。在模型的代码中,我们没有看到本质上的创新,但它在优化方面下了很大功夫。
(一)精度优化
在AI模型中,通常使用浮点数进行运算。一般情况下,显卡或编程语言(如C语言)默认声明的浮点数是32位的,精度极高。然而,当模型的参数量达到数亿甚至数十亿时,对精度的需求其实并没有那么高。DeepSeek在这方面做了大胆的尝试,它采用了8位精度的浮点数进行运算。虽然精度降低了,但在处理大量参数时,性能却得到了显著提升。从32位到8位,运算强度可以降低16倍左右。这意味着,即使在低端硬件上,DeepSeek也能高效运行,降低对高端的英伟达芯片的依赖程度。当然,对于损失一定精度换取效率的做法也是仁者见仁智者见智了。
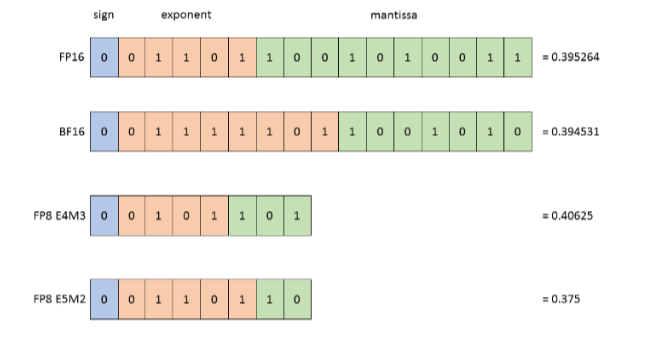
(二)并行计算优化
DeepSeek的代码中大量涉及并行计算的优化。它对Transformer模型的线性层进行了改造,使其能够更好地在多个GPU上并行运算。传统的解决方案需要昂贵的NVLink等技术来实现GPU之间的内存共享和算力协同,但DeepSeek通过改变模型结构,实现了在普通低端GPU集群上的高效并行计算。这种优化不仅降低了硬件成本,还提高了模型的可扩展性。更加的有利于中小科技公司在资金和硬件条件有限的情况下开展自己
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









