




前言
话说懒惰是人类进步的原动力,古人诚不欺我。最近在折腾一个微信公众号,开始的时候在网上找一些资源然后进行二次创作然后发表到微信公众号,但是这就要自己先把里面的图片下载下来然后文字也复制过来然后再慢慢的上传到微信公众号,干了几天以后发现这样效率太低了,每天都在干重复的事情,这作为一个程序员是不能忍受的,任何重复的事情都有实现自动化的价值,我们不能浪费生命在这种地方,废话不说,开搞。
一、需求与难点
- 从指定页面爬取数据
- 只爬取我们需要的内容(什么广告啊,导航那种是不要的)
- 然后把正文上传到微信公众号的草稿箱
- 微信的草稿箱接口只能放上传到微信里面的图片,所以我们要做一步额外的操作就是先把网页里面的图片提取出来上传到微信公众号里面,然后把正文里面的图片链接替换成微信公众号里面的 图片
二、使用到的工具和接口
- 上传封面图片到微信公众号 新增永久图文素材 | 微信开放文档 (qq.com)
- 上传正文图片到微信公众号
http请求方式: POST,https协议 https://api.weixin.qq.com/cgi-bin/media/uploadimg?access_token=ACCESS_TOKEN 调用示例(使用curl命令,用FORM表单方式上传一个图片): curl -F media=@test.jpg "https://api.weixin.qq.com/cgi-bin/media/uploadimg?access_token=ACCESS_TOKEN" -
上传正文到公众号草稿箱 接口请求说明 | 微信开放文档 (qq.com)
-
python 这边主要使用:requests,BeautifulSoup,json
三、实现步骤
1.分析网页
这个是我们要分析的网页截图: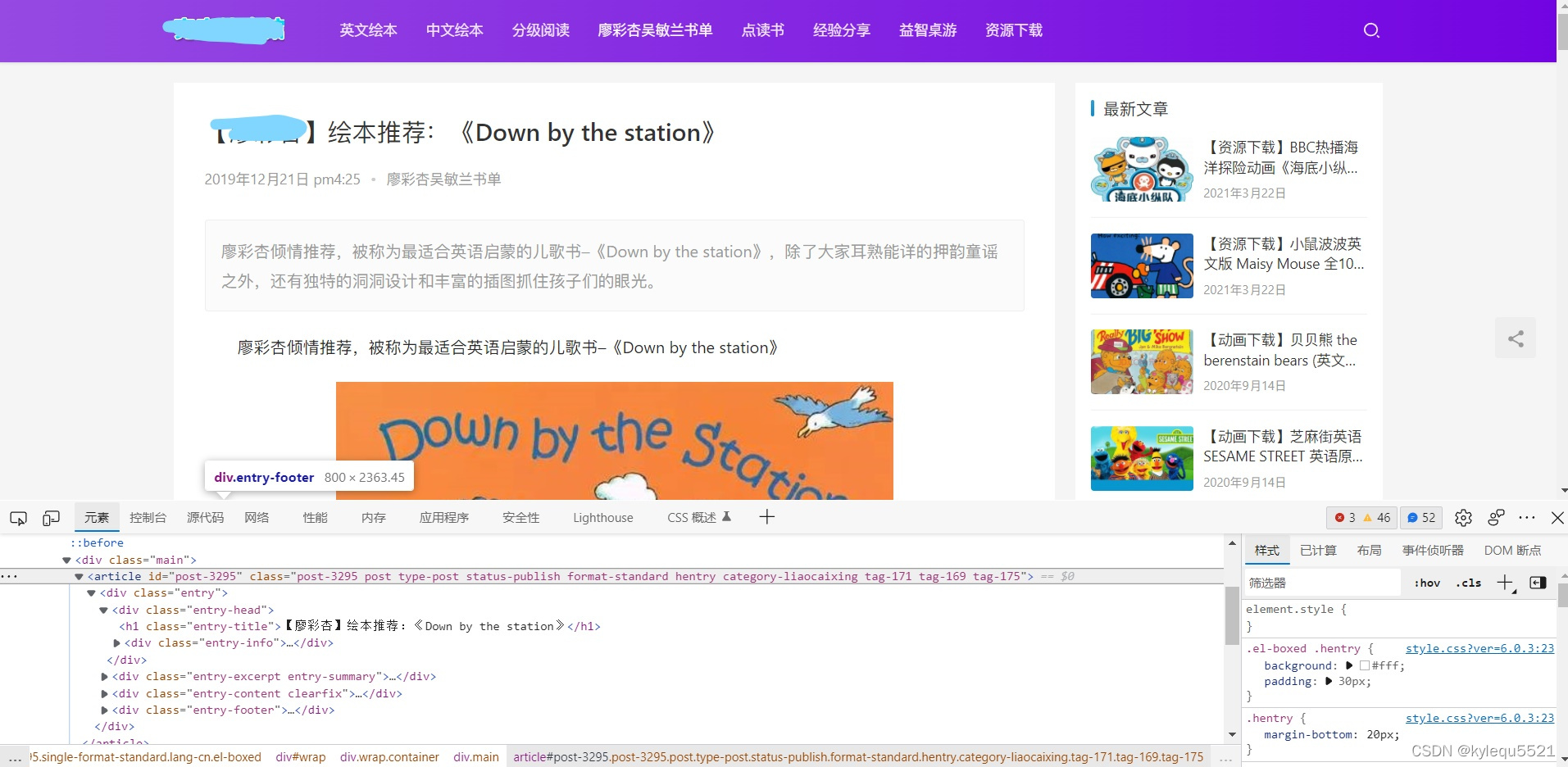 我们可以看出这个网页有自己的导航还有右边的推荐栏还有底部的导航,如果我们直接吧整个网页都扣下来上传到的微信公众号那无疑会给我们后期处理带来很多的工作,所以我们只需要正文也就是html里面的<article></article>里面的内容
我们可以看出这个网页有自己的导航还有右边的推荐栏还有底部的导航,如果我们直接吧整个网页都扣下来上传到的微信公众号那无疑会给我们后期处理带来很多的工作,所以我们只需要正文也就是html里面的<article></article>里面的内容
2. 调用接口
- 我们先来看上传草稿API接口
接口请求说明 http 请求方式:POST(请使用https协议)https://api.weixin.qq.com/cgi-bin/draft/add?access_token=ACCESS_TOKEN 调用示例 { "articles": [ { "title":TITLE, "author":AUTHOR, "digest":DIGEST, "content":CONTENT, "content_source_url":CONTENT_SOURCE_URL, "thumb_media_id":THUMB_MEDIA_ID, "show_cover_pic":1, "need_open_comment":0, "only_fans_can_comment":0 } //若新增的是多图文素材,则此处应还有几段articles结构 ] }请求参数说明 参数 是否必须 说明 title 是 标题 content 是 图文消息的具体内容,支持HTML标签,必须少于2万字符,小于1M,且此处会去除JS,涉及图片url必须来源 "上传图文消息内的图片获取URL"接口获取。外部图片url将被过滤 thumb_media_id 是 图文消息的封面图片素材id(必须是永久MediaID) 可以看出这个接口的参数有3个必须的,那么接下来我们就去网页的代码里面看看怎么拿到这3个参数
- 分析网页我们可以得到我们要的title就在class = 'entry-title'的a标签里面,而且我们还可以拿到文章的摘要在class=‘entry-summary’的div里面
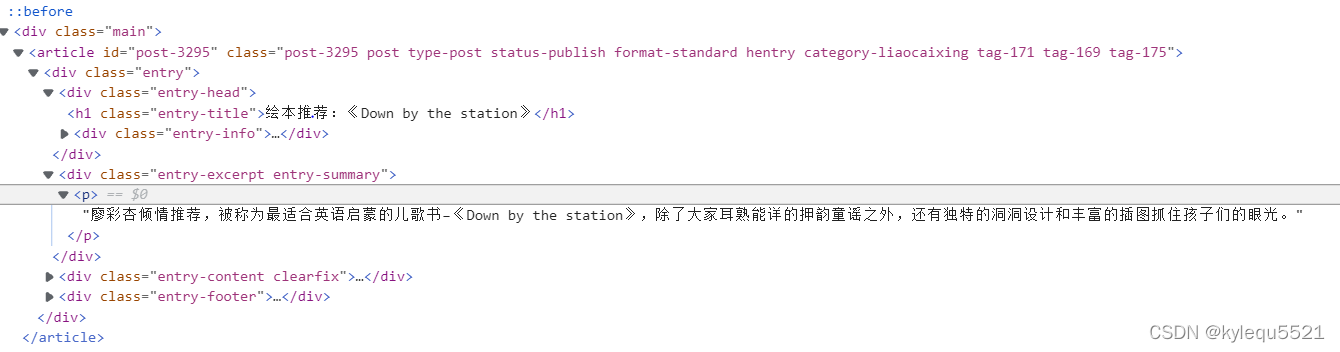
- 所以我们首先抓取这个页面然后拿到title和摘要
baseUrl = 'https://www.test.com' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.57' } res = requests.get(baseUrl, verify=False, headers=headers) root_soup = BeautifulSoup(res.content, 'html.parser') title = root_soup.select('.entry-title')[0].text summary = root_soup.select('.entry-summary p')[0].text print(title) print(summary) - 接下来要准备搞定封面,这下开始用到微信公众号接口,但是在使用公众号接口之前我们要先获取一个token,来使我们有权限访问公众号的API接口,获取token的文档在这里:微信开放文档 (qq.com)
- 通过分析正文我们知道这个文章有很多图片,那我们就把第一个图片单做封面,先定义一个上传封面的方法
def updFm(path, file_name): base_folder = 'D:\\tempDir\\' file_path = '{}{}.jpg'.format(base_folder, file_name) res = requests.get(path, verify=False) with open(file_path, 'wb') as f: f.write(res.content) url = 'https://api.weixin.qq.com/cgi-bin/material/add_material?access_token={}&type={}'.format( access_token, 'image') request_file = { 'media': ('{}.jpg'.format(file_name), open(file_path, 'rb'), 'image/jpeg')} vx_res = requests.post(url=url, files=request_file) obj = json.loads(vx_res.content) print(obj) return obj['media_id'] - 然后获取正文里面所有的图片,把第一个传入到这个方法里面获取封面id
content_soup = root_soup.select('.entry-content')[0] imgs = content_soup.select('.wp-block-image') fmId = updFm(imgs[0].img['src'], title) - 接下来我们在定义一个上传正文其他图片的方法,因为其他图片需要返回的url不是media_id,所以调的另外一个接口
def updImg(url): base_folder = 'D:\\tempDir' res = requests.get(url, verify=False) file_name = '{}.jpg'.format(random.randint(10000, 99999)) with open(base_folder + file_name, 'wb') as f: f.write(res.content) vx_img_url = 'https://api.weixin.qq.com/cgi-bin/media/uploadimg' request_file = { 'media': (file_name, open(base_folder + file_name, 'rb'), 'image/jpeg')} data = { 'access_token': access_token } vx_res = requests.post(url=vx_img_url, files=request_file, data=data) obj = json.loads(vx_res.content) print(obj) return obj['url'] - 然后把正文里面的图片全部上传到微信公众号号的素材库并替换到正文里面的图片地址
for img_content in imgs: img_content.noscript.decompose() current_url = img_content.img['data-original'] upd_url = updImg(current_url) img_content.img['src'] = upd_url img_content.img['data-original'] = upd_url - 最后我们就可以开始准备上传文章到草稿箱,还是先定义方法,因为草稿接口的标题和摘要有长度限制所以这个方法开始做了一个限制如果长度超过了就截取字符串
def updCG(title, summary, content, fmId): if len(title) > 64: title = title[:63] if len(summary) > 120: summary = summary[:119] url = 'https://api.weixin.qq.com/cgi-bin/draft/add?access_token='+access_token data = { "articles": [ { "title": title, "author": '作者', "digest": summary, "content": content, "show_cover_pic": 1, "need_open_comment": 0, "only_fans_can_comment": 0, "thumb_media_id": fmId } ] } vx_res = requests.post(url=url, data=json.dumps( data, ensure_ascii=False).encode("utf-8")) obj = json.loads(vx_res.content) print(obj) return obj['media_id'] - 然后再总方法里面调用我们的上传草稿的方法
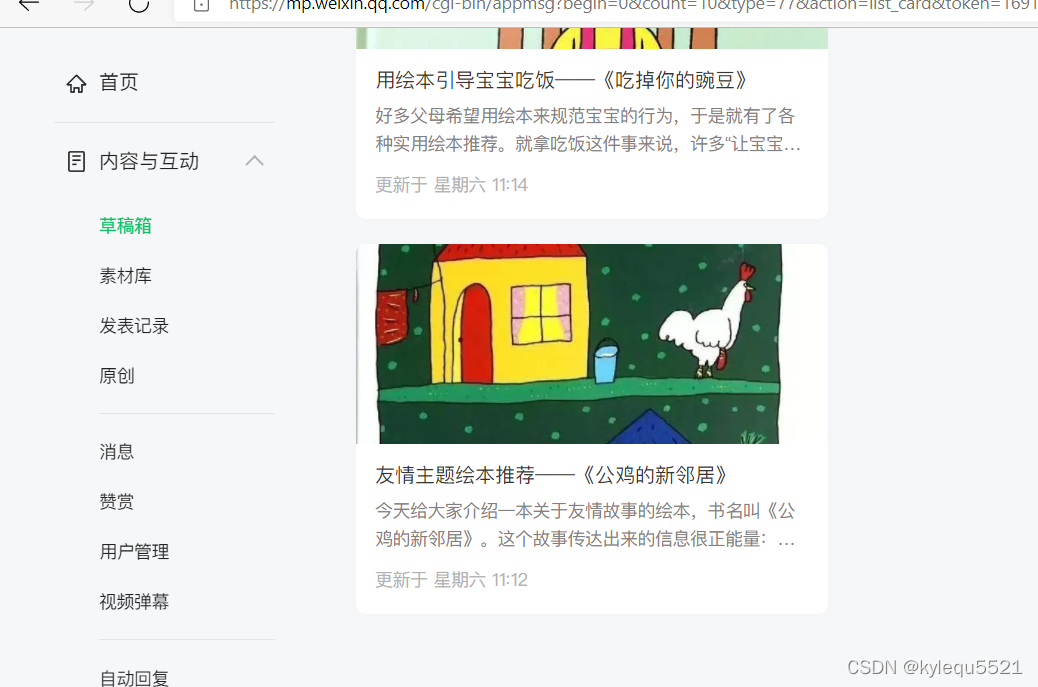
print(content_soup.prettify()) updCG(title, summary, content_soup.prettify(), fmId) - 查看结果,可以看到文章已经自动提交到草稿箱,接下里我们就可以进去进行二次创作进行发表了
总结
这个总共实现下来也就100多行代码半天就能搞定,其实这个主要还是需要你去分析网页,因为每个网站的情况都是不一样的,后面的技术实现都大同小异,我们在生活中也会遇到很多这种需要一直机械重复的事情,这时候我们只要稍微在多费一点脑力就可以后面节省很多时间,我们掌握一些其他人不会的东西,那就做一些不一样的事情吧,技术改变生活不是吗。


















 1381
1381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









