



20220827
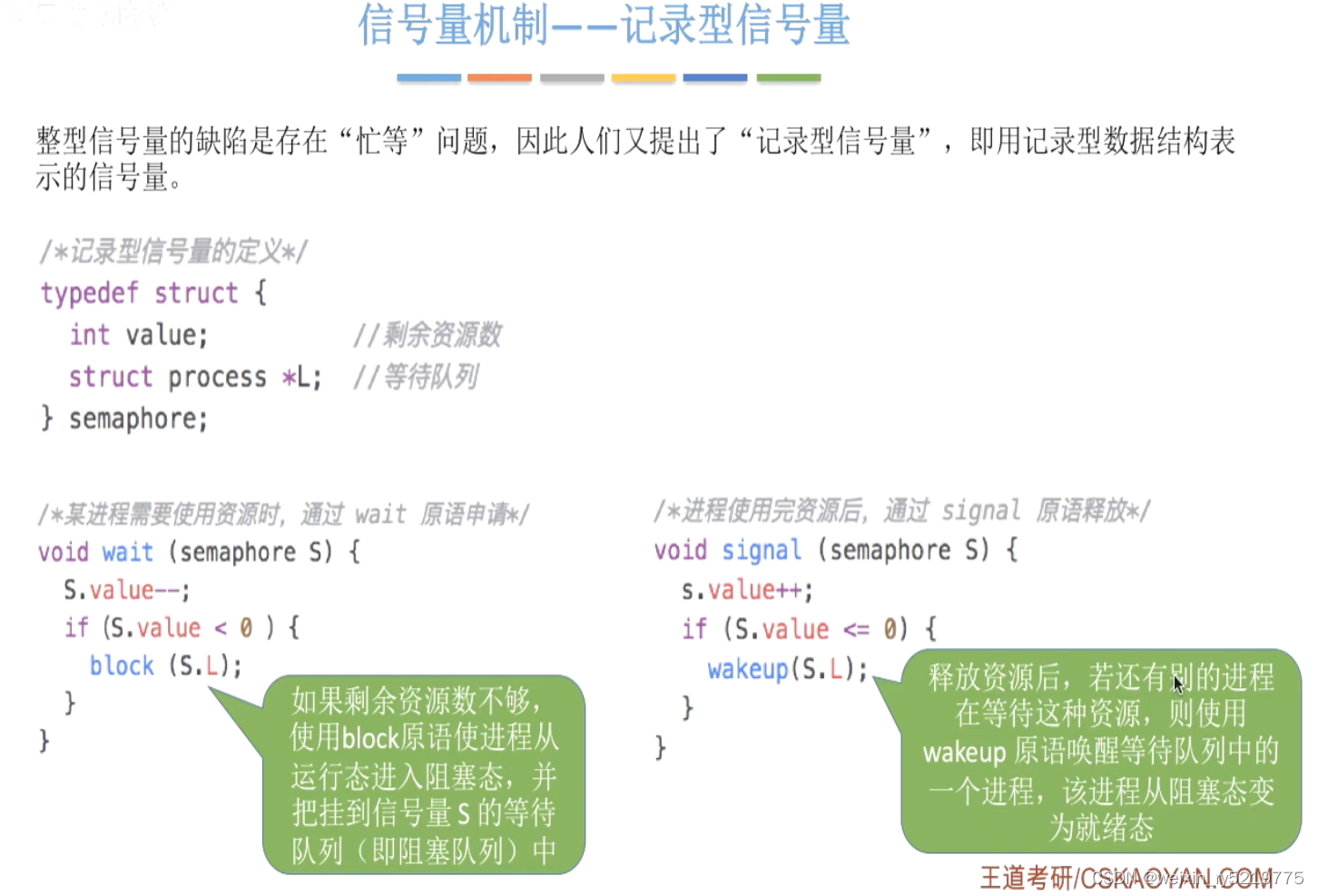
通过主动对进程进行操作,并利用队列,解决让权等待的问题,
20220826
进程调度算法
1.先来先服务
2.非抢占式短作业优先
3.抢占式短作业优先 任何时间都是跑的最短作业,总时间最省
4.高响应比优先

响应比
考虑算法解决方案的时候
1.单个独立指标
2.复合比例指标
高响应比= (等待时间+运行时间)/运行时间
既考虑了运行时间,也考虑等待时间
本质上比较的就是等待时间/运行时间的大小
本质上兼顾了公平,运行时时间长的,等待时间也长
固定一个变量,对比另一个变量变化造成的变化
比如等待时间相同时候,运行时间越短,响应比越高
把之前两种算法的优点结合起来了,如何结合的,注意了
操作系统作业调度算法
20220730
最小二乘拟合到很偏的值的时候,通过构建阈值范围,来约束拟合点的访问,这样可以拟合大部分点
随机一次性抽样 opencv
20220629
大部分情况下,取对数就是为了把值变小
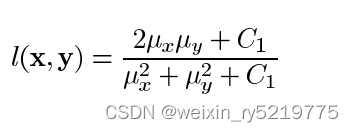
ssim:对两个对象的几个不同指标,都可以通过构建上面的公式进行相似性对比
两个变量代入极端值,可以只管查看结果 比如都取x,或者取相反的-1和1等能较好比较二者的结构性差异
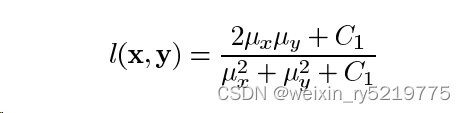
亮度比较
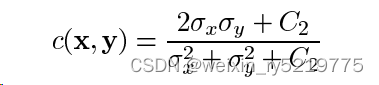
对比度比较
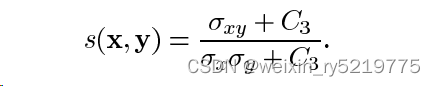
结构性比较
20220616
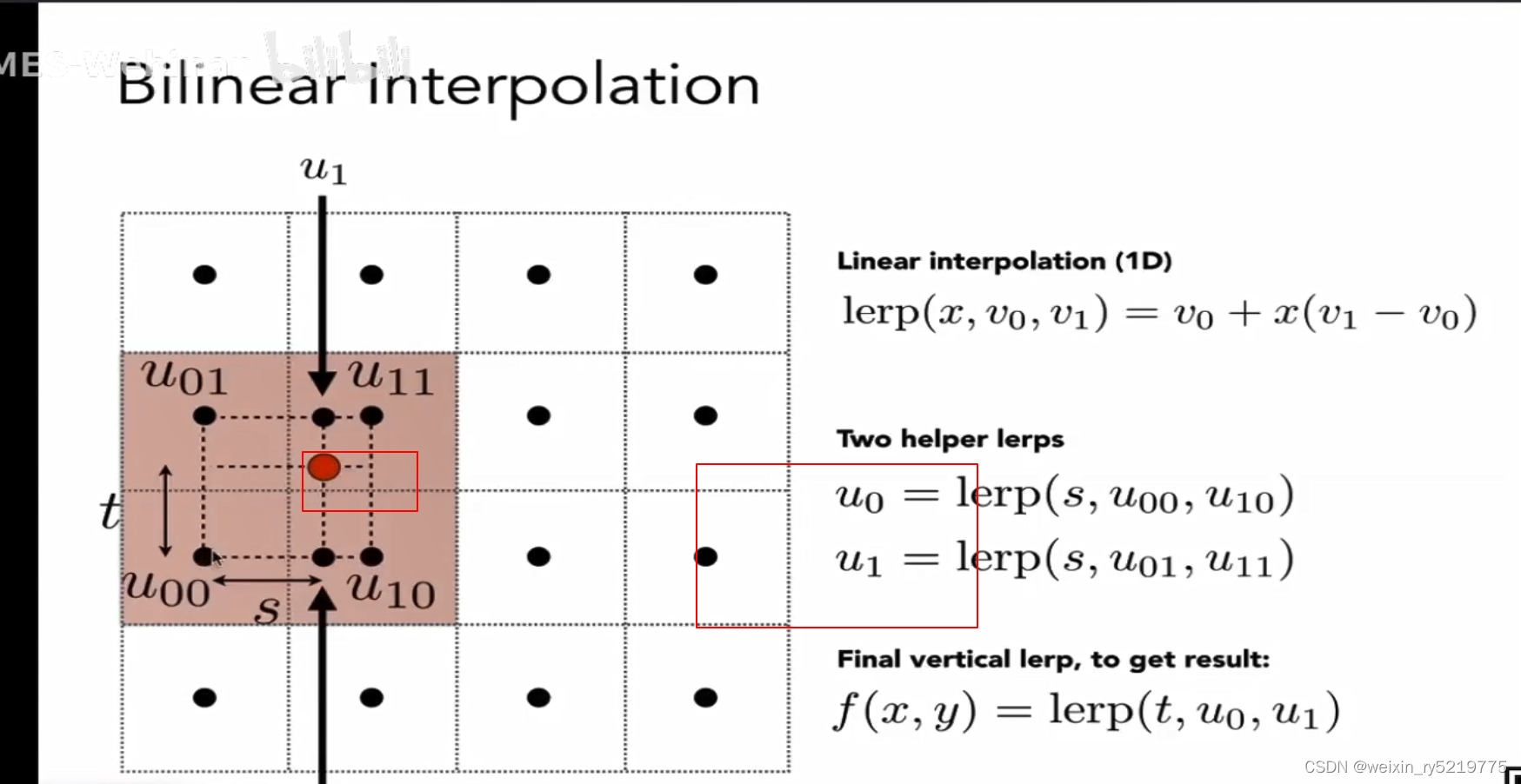
三次插值得到最终的值,直接离四个点的距离的话,应该是比较难以计算,计算量大,效果应该差不多
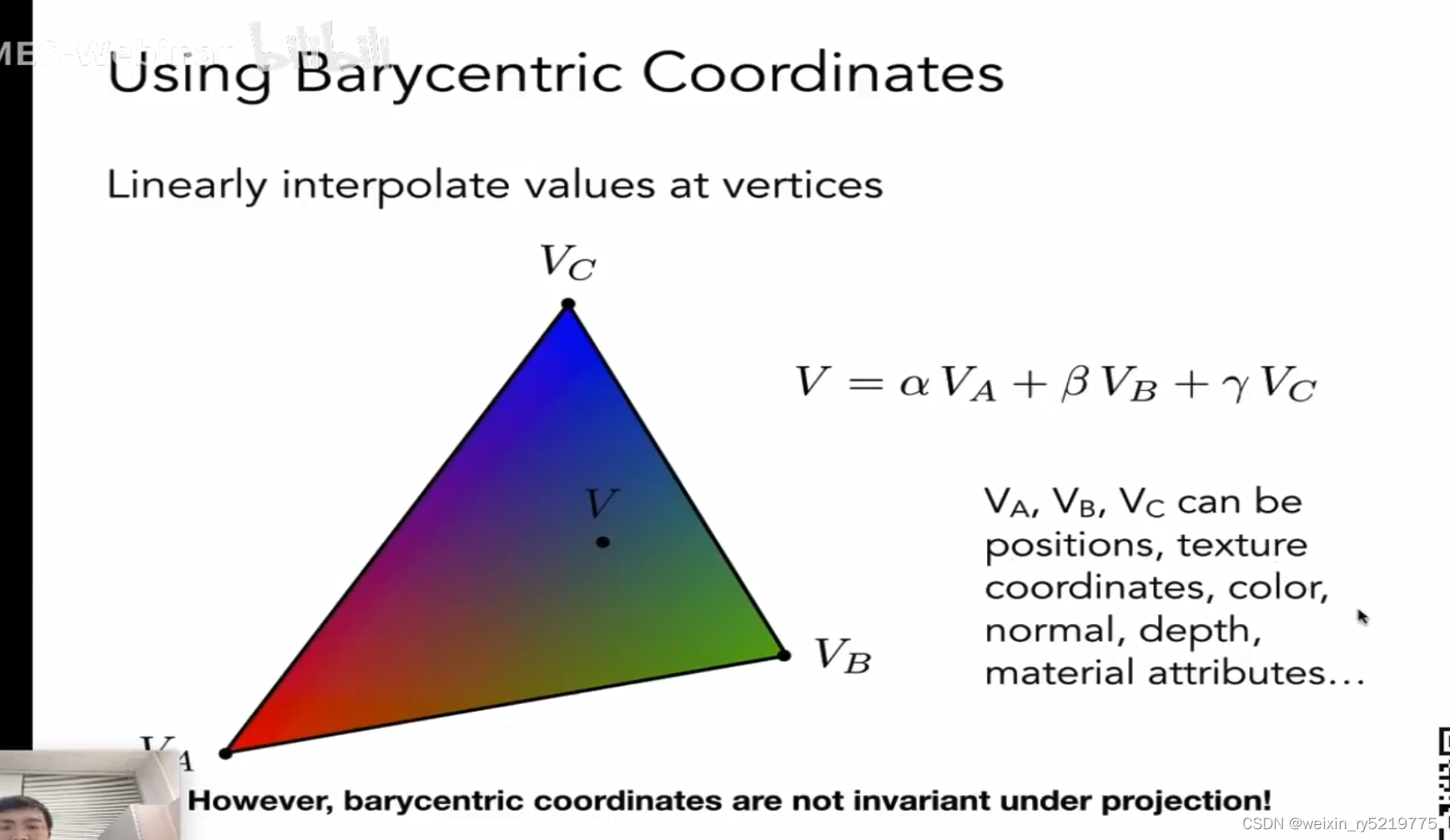
求任一个点的值,又是借助周围的点来算其插值
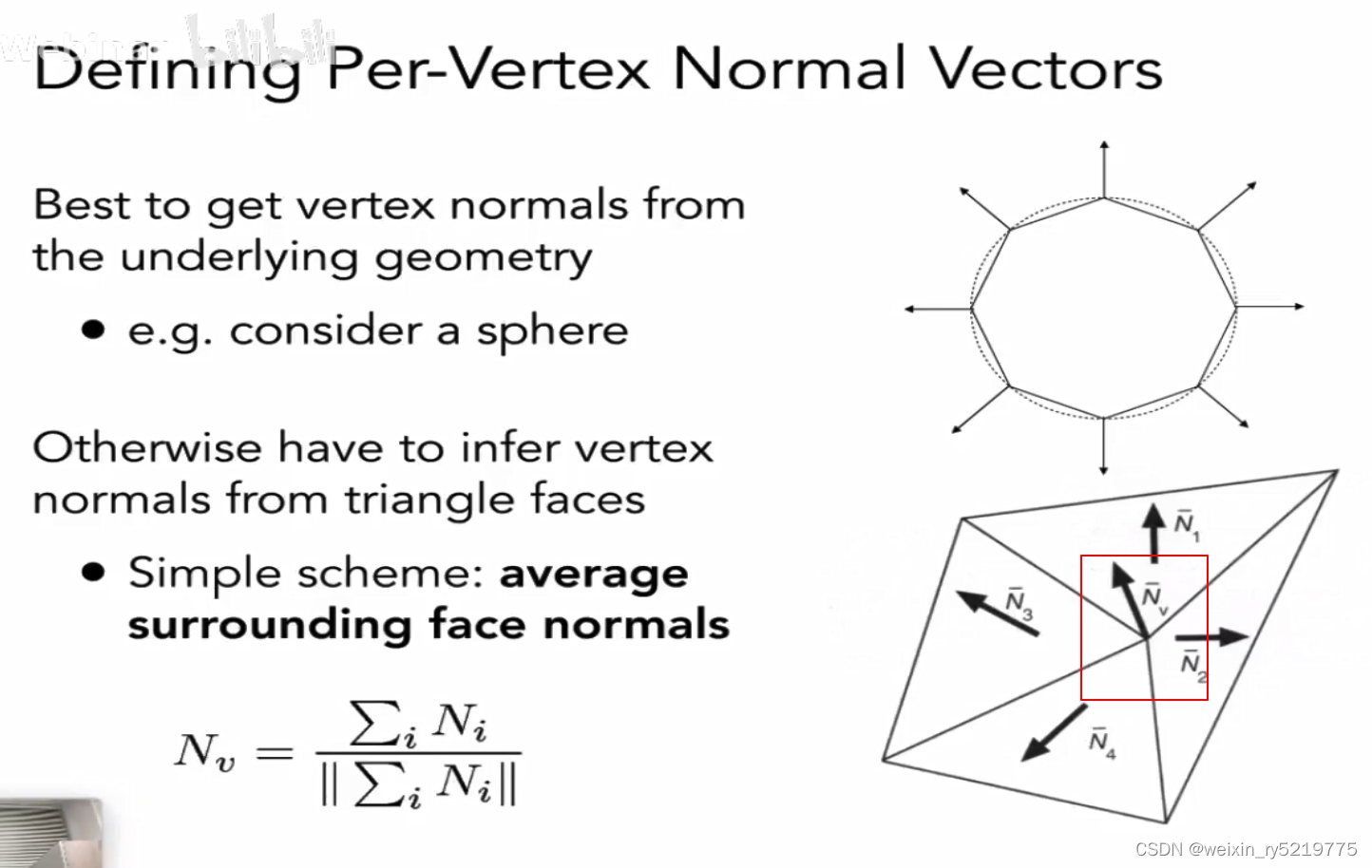
订单法线,为所有面法线的平均,权重为各个面的大小
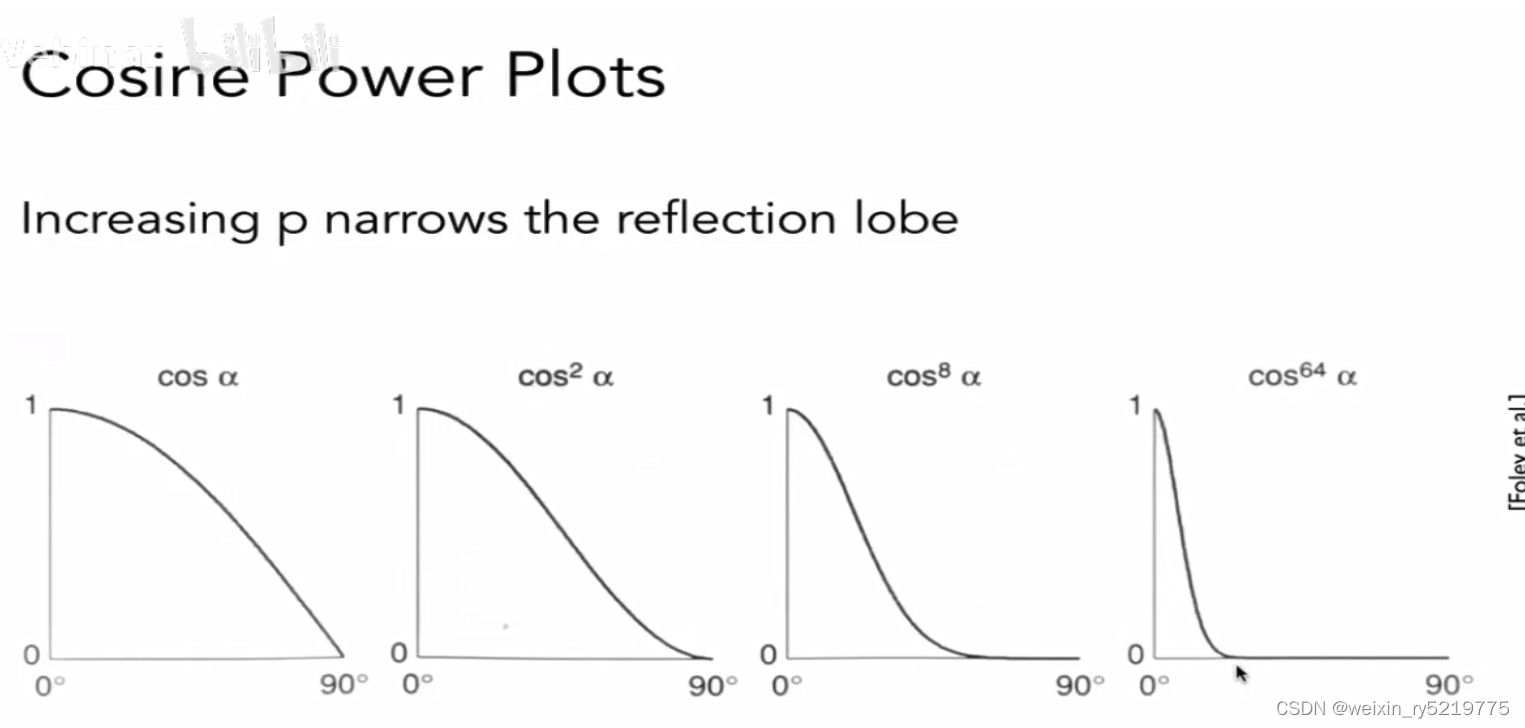 高光,加速衰减
高光,加速衰减
20220615
静态转动态:抗锯齿 四个采样点,分成四张时间上不同的四张图片,考虑每个时间点上,采样点与图像的内外关系
20220612
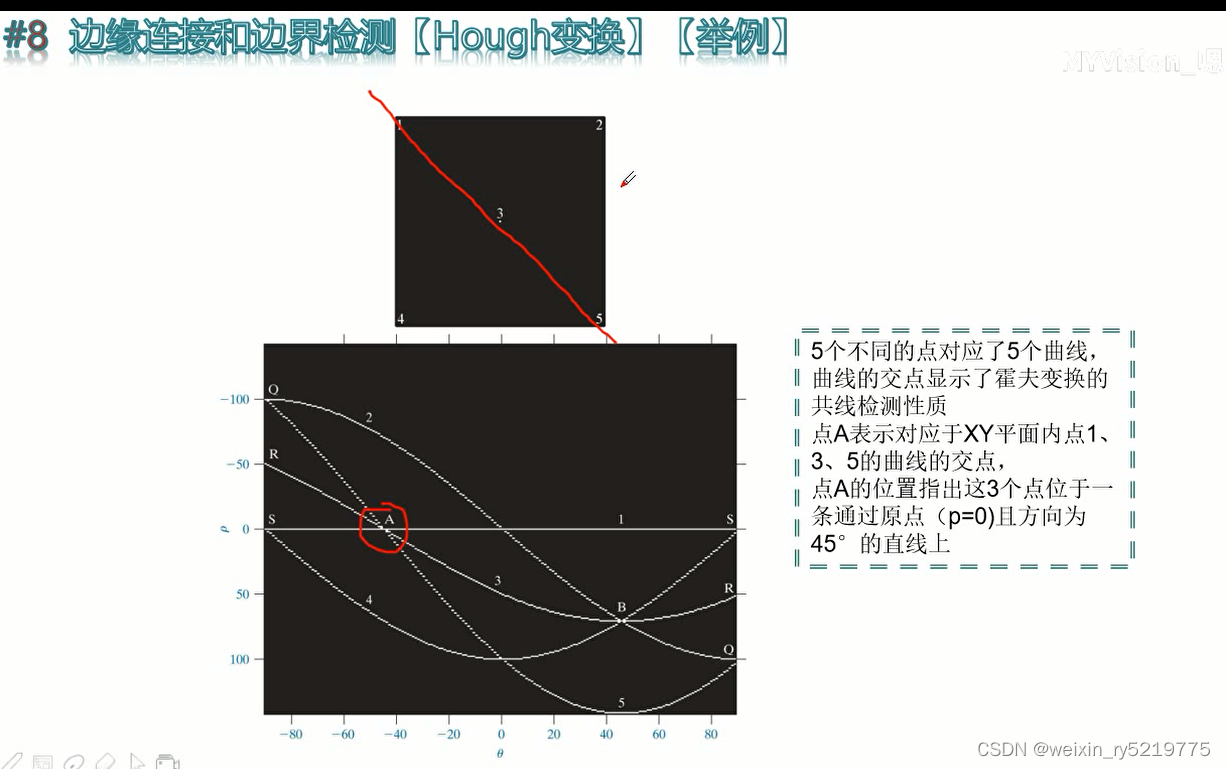 hough变换,把判定共现转变为判定共点,空间转换来简化问题难度
hough变换,把判定共现转变为判定共点,空间转换来简化问题难度
增强泛化和扩展:把预测中从未遇到过的,用之前遇到过的来表示
比如transformer的正余弦位置编码
20220610
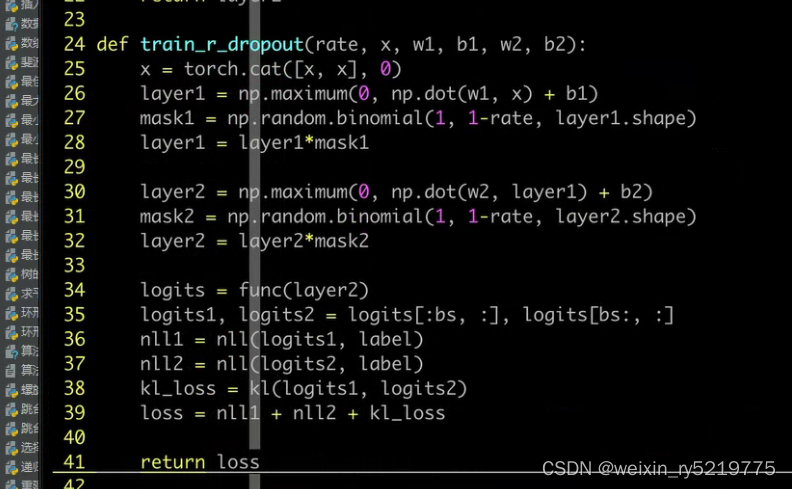
分布不一致,我就用一个损失函数 散度 把其分布弄成一致 r-dropout
通过加一个约束,指导指标把差距缩小
需要训练两次,我同时扩大batch_size为一倍,再拆分算结果,这样就不用算两次了串联变并联,提高并行度
dropout
w*α/(1-p) :1-p 抵消α的作用,同时使得测试时候,不用再额外操作?
为什么要除以 1 - p (保留的概率),或者在测试阶段 乘以 1-p 保留概率
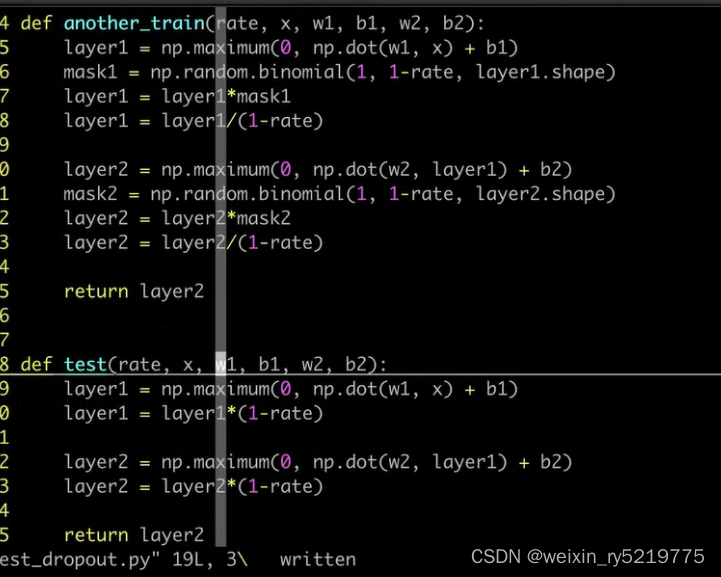
训练阶段除了,测试阶段就不需要乘了 为什么,相当于抵消了测试阶段的乘法工作?????,把工作量放到训练阶段
20220602
To predict the pixels in the border region of the image, the missing context is extrapolated by mirroring the input image. This tiling strategy is important to apply the network to large images, since otherwise the resolution would be limited by the GPU memory.
为了预测图像边界区域的像素,通过镜像输入图像来推断缺失的上下文。这种平铺策略对于将网络应用于大型图像非常重要,否则,分辨率将受到GPU内存的限制。
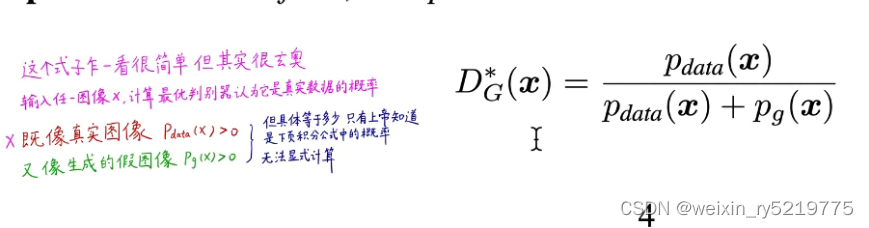
pdata是真实图概率,自己赋值0到1之间的值查看

上一个式子梯度解决与零很难优化,转换为下面的式子改成从最小化改成最大化

D(G(z))为横轴
20220418
为了确定一个时间序列相对于它的快速变化的长期稳定性,我们利用自相关分析技术。此外,为了将重复的模式从缓慢的变化中分离出来,我们利用了分解分析技术。分解将时间序列分解为捕捉缓慢变化的趋势分量、捕捉重复模式的季节分量和捕捉剩余噪声的分量。我们使用从这些分析中提取的信息作为输入分类器进行检测。这些分类器用于确定未知的时间序列是属于爬虫还是属于用户。
Sample Auto-Correlation Function (SAC)
通过自相关考察强自相关相关系数的滞后期大小,如果大就是用户否则是爬虫
归根结底就是时间序列技术
20220410

垃圾回收算法
1.可达性算法 是否存在gc root 引用,无引用则可删除 通过复制一块完全相同打下的内库块来保存不被删除的部分 比较高效地完成了整理
2.计数器算法 会存在两个无用对象的循环引用而得不到清除
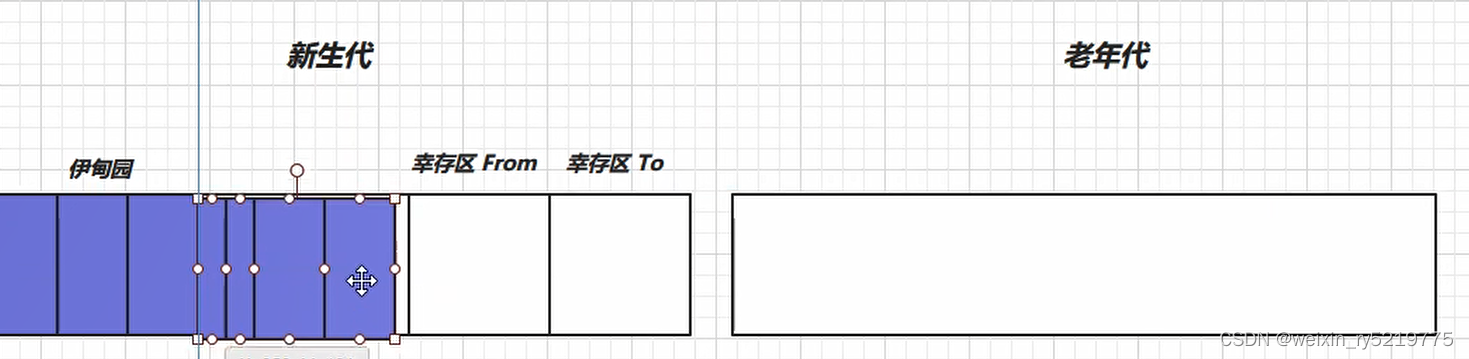
分代垃圾回收,新生 快生快死 老年代:长久有效
按不同的对象的 生命周期来分别处理

相应时间优先
吞吐量优先
上面两种混合算法就是把各种垃圾回收策略通过分时间或者分层次混合不同策略
充分吸收不用算法的优点
gi:同时兼顾低延迟和吞吐量高
20220331
 bm25逆文档频率
bm25逆文档频率
20220326
两条mysql服务器同步更新主键id,通过奇偶来解决(互斥的两种选择)
如果后面再加服务器(三种情况的时候就要加入中介媒介来处理了),可以提前先生成主键id放在队列里,公用的
每次生成都在公共id集中来取
或者步长相隔很远 开始是1 一台 offset 1亿 一台 offset两亿 一台3亿
或者 10001 1002 10003 offset都是3 步长3能容纳冲突 但后期还是不太智能
下面两种方式属于改变其他的某种元素
20220314
总结大数据中提高效率的方法
bitmap:位图索引 向量存储 代价小
20211219
- 减去均数除去主观整体影响 评分
- 除以对应的季节指数,除去季节影响
- 差分去掉趋势影响
总体原则除去公共的或者多余的部分
离散序列的d 阶差分就相当于连续变址的d 阶求导
20211211
方程组的解法
1.直接求解
2.通解加特解
3.迭代法
4.近似解
矩估计:就是利用样本的统计特征来归结总体的其他值比如利用均值,方差等来估计总体的相关系数等精度差作为
最小二乘法和极大似然估计的初始值
20211201
要比较二者的差异,同时屏蔽二者整体的或者说基数的不同,可以减去均值之后再比较
余弦相似度和皮尔逊相关系数的关系
欧式侧重于绝对距离,余弦侧重于相对差异 欧式归一化之后呢?
20211125


TFIDF改进
textrank也是关键字提取
20211029
用计算机模拟计算就是写一个def函数
计算需求价格弹性系数的时候
如果事物本身存在持续增长的情况下
需要先考虑本身的增长
比如火车客运量,但是药物明显不存在这种情况
要试图得到某个因素对结果造成的影响,可以先把其他因素置为相同 比如求需求价格弹性 可以只考虑年度的数据 这样就忽略了促销,年度,节假日的影响
或者通过减的方式排除某个影响 推荐系统过滤
或者通过除以相同分母的方式,比如归一化
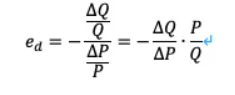
单位价格变化率对应的需求变化率
为什么不是直接的需求变化绝对量除以价格变化的绝对量

pi刚开始也是参数,就像求梯度一样
最后再代入具体的数值
20211027
权重的意义可以解释为敏感度
比如
需求=权重*价格
权重为负值,价格越高,需求越小
20211016
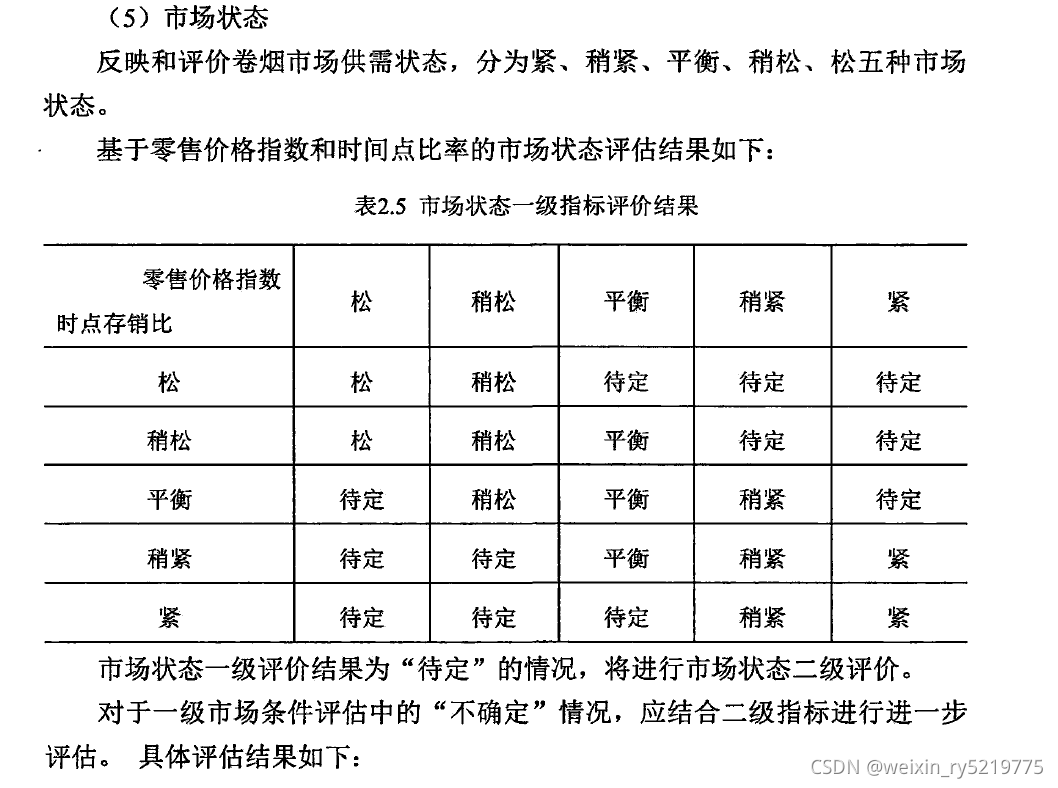
反映市场状态的指标 零售价格指数和时点存销比
基于贝叶斯网络的卷烟市场状态监测的研究与应用
论文
机器学习融入时间序列模型
把准确率序列最后通过Arima来预测
20211003
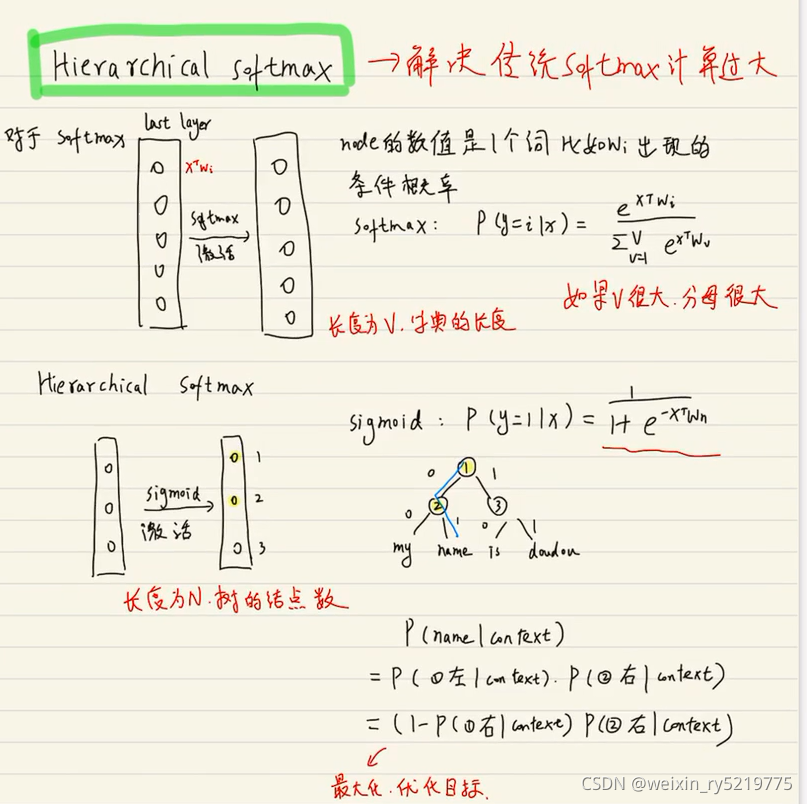
层次softmax减少计算量
通过huffman树把预测标签总数减少了 预测的是每个父节点而不再是根节点
单词越多减少量越明显
20210925
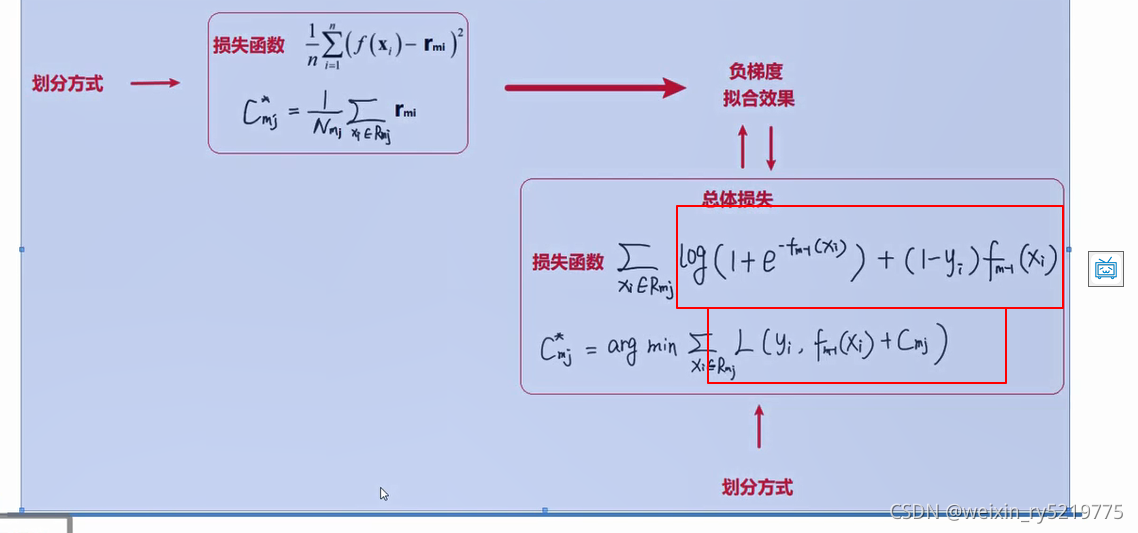
当得不到具体的解的表达式的时候 用梯度下降或者泰勒二阶展开来求解

梯度下降可能面临的缺点
解决梯度下降的问题

adboost 整体就是利用前向分布算法实现的损失函数优化
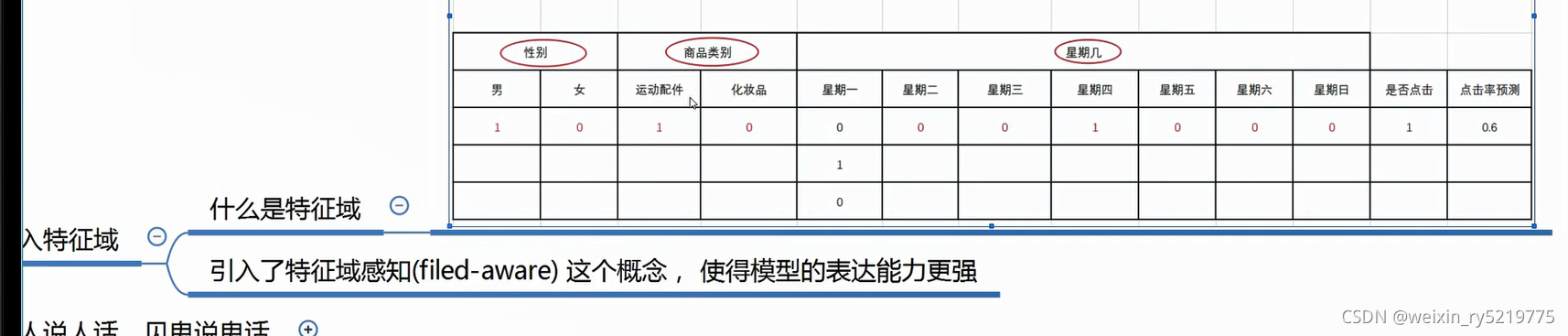
特征域
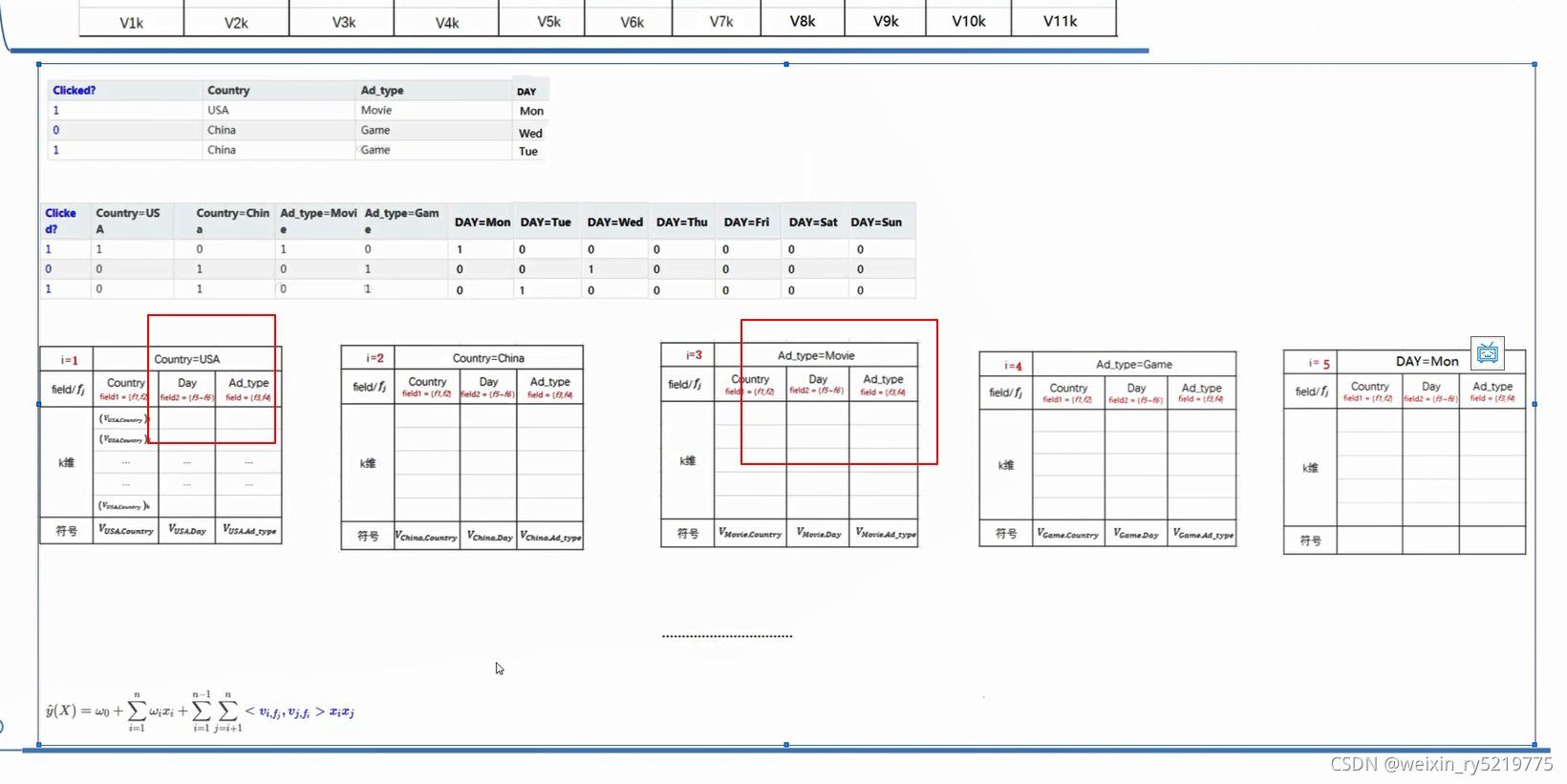
高一层抽象 多一层分组以此来区分不同的事务
20210924
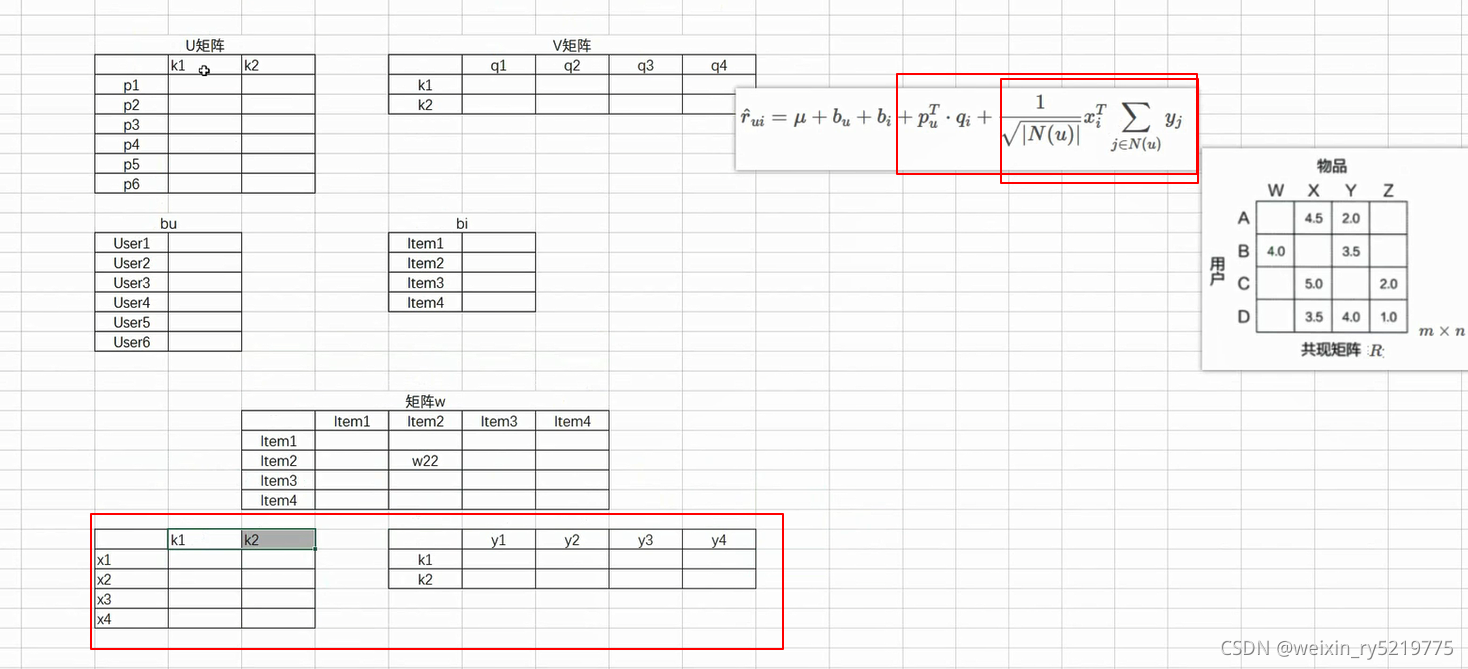
看到这种形式就要想到是两个矩阵相乘
xT不变表示 每次点积X都不变,y变化 xy1+xy2+x*y3
x和j没有关系 所以可以直接拖出来
XT T表示X的组成以行向量表示
09 9.SVD++
视频
矩阵分解隐向量和深度学习embedding其实可以看成是同一个东西

通过这种方式 引入其他物品相互间的影响因素
梯度下降最优化使用的场景
1.当公式直接计算的时候存在各种现实的限制条件的时候
比如矩阵稀疏,矩阵规模大,极值多,缺失值多的时候就可以考虑
用梯度下降来慢慢接近答案 就没有了上面这些烦恼
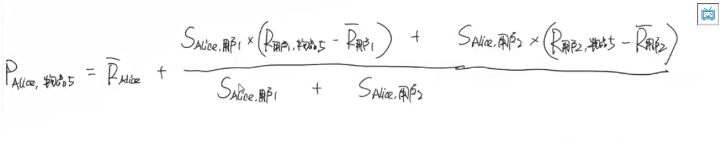
减少每个人主观的评判差异 各自每次的实际值减去其自身所有值的平均值只考察偏差
要归一化就是所有的情况求和做分母或者最大值做分母
20210825
20210514

统一两种写法
20210420
rear = (rear + 1) % maxSize;
取模可以模拟以maxsize做循环操作
20210401
要考察企业成长性
根据已有的,已公开的信息统计各种指标的曲线
然后再映射去套要预测的企业
20210315

计算信息增益时对采样的Z2样本的梯度数据乘以(1-n)/m(目的是不改变原数据的分布)
假设原来是10个
a 取 2个
剩下的取8个
也就是两个集合数目加起来还是总数 不改变最后的训练例子总数
20210116
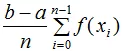
n的位置可以移动 可以作为 b-a除以n
也可以说是后面部分求均值
20201213
log 使值变大 比如 0.001,0.002 等 也是把相乘变成相加
负数加上底数 使其取值变到坐标轴的上半部分 更容易观看

perplexity
20201108


根据概率采样
20201014

https://haokan.baidu.com/v?vid=15284978659146216535&pd=bjh&fr=bjhauthor&type=video
第一行的1 表示 0结点到1结点的距离
第三行 的 3 表示 2号结点到0号结点的距离
第三行的 4 的位子 表示 2号结点到0号结点的位置 这里已经被覆盖过一次
20200927
除以总数肯定就是平均了
20200925

除以 归一化的作用、
歧义消除

log2 化成二进制
20200923

同号取交和异号取强

第二个式子 分母 相当于 0-P(H)
两个式子都是表示最大范围 也就是把整个值限定在
(0,1)之间
可信度
20200902

估计算法效率
离散数学
20200809

NP难问题 通过近似求解
20200728
Hyman分别测试法
https://blog.youkuaiyun.com/weixin_42194284/article/details/93898281
捕获再捕获抽样是用于生态学以及估计野生动物总体数量的一种抽样方法。其基本方法是从总体中抽取一个样本,做上记号以后放回总体,使之与原总体的单位均匀地混合,经过适当的时间,再从中抽取一个样本。根据已做记号与未做记号的比率来推断总体的数量 [1] 。
估计
抽样出的真实故障除以总的真实故障总数 等于 抽样出的植入故障数除以植入的故障总数

温度放大信息,亲自动手算一下
20200607
今天早上想到两种情形,不能依靠相邻词的概率排除歧义义项。第一种是“我花了8000元买了个苹果”,第二种是“小李很喜欢他的苹果”。这两种都比较难确定“苹果”是水果还是手机?特别是第二种,需要依靠上下文前面的“小李拥有两个手机”来判断,两句话的距离可能比较远,而且要在小李的拥有物之内,把苹果与手机关联起来,人虽然容易做到,电脑想依靠数学或算法来做可真是头痛。还好灵感发现,我五分钟之后就想到了办法。
第一种情形,只要写两个语义正则表达式,“Q:* 苹果 * num 元 * A:num:TP@TOTOAL”,“Q:* num 元 * 苹果 * A:num:TP@TOTOAL”,再用这个模板上语料库搜到八句num数值最接近的句子,再计算所得到的八个整句(TP@TOTOAL)里面所有的名词动词与水果和手机的关联度,可以排除歧义义项了。
第二种情形更复杂一点,就用以下语句训练出一个语义模板:
“Q:小明拥有两个手机 A:小明 手机”,
“Q:小明买了一个手机 A:小明 手机”,
“Q:*送给小明一个手机 A:小明 手机”,
“Q:小明手上有两个手机 A:小明 手机”,
“Q:小明的手机 A:小明 手机”,
“Q:小朱拥有两个玩具 A:小朱 玩具”,
“Q:小朱买了一个玩具 A:小朱 玩具”,
“Q:*送给小朱一个玩具 A:小朱 玩具”,
“Q:小朱手上有两个玩具 A:小朱 玩具”,
“Q:小朱的玩具 A:小朱 玩具”,
有了这个语义模板以后,遇到可以确定拥有物的语句,就可以输出所有者与拥有物这两个词。用它来处理上下文,就能找到小李的所有拥有物,计算这些拥有物与水果和手机的关联度,可以排除歧义义项了。
词嵌入算关联度?
@劲风的味道 内部编辑了一个语义库,部分借鉴了hownet
【活跃】旭日东升 2020/6/7 14:39:20
关联度,反义度是我独有的,hownet基本没有
14:43:43
【潜水】劲风的味道 2020/6/7 14:43:43
能一句话概括一下idea吗
抽烟,香烟,尼古丁都是关联词,一般是相邻句子里共现多的,或者是词的一部分例如抽烟与烟,或者有从属关系的。

知识 信息 数据
解释过程
20200510
How do you compare two probability distributions? We simply subtract one from the other. For more details, look atcross-entropy and Kullback–Leibler divergence.
简单的考察分布
公式构造
思路
最简单的加减乘除着手
F(x)=(1-x)a+bx
当x等于1的时候要消去变量a 就让x减去1 这个值再乘以 a
当x等于0的时候要消去变量b
公式构造
乘以零 消去
减法 用于抵消某东西的影响

惩罚
softmax 可以是值大的更大,小的更小

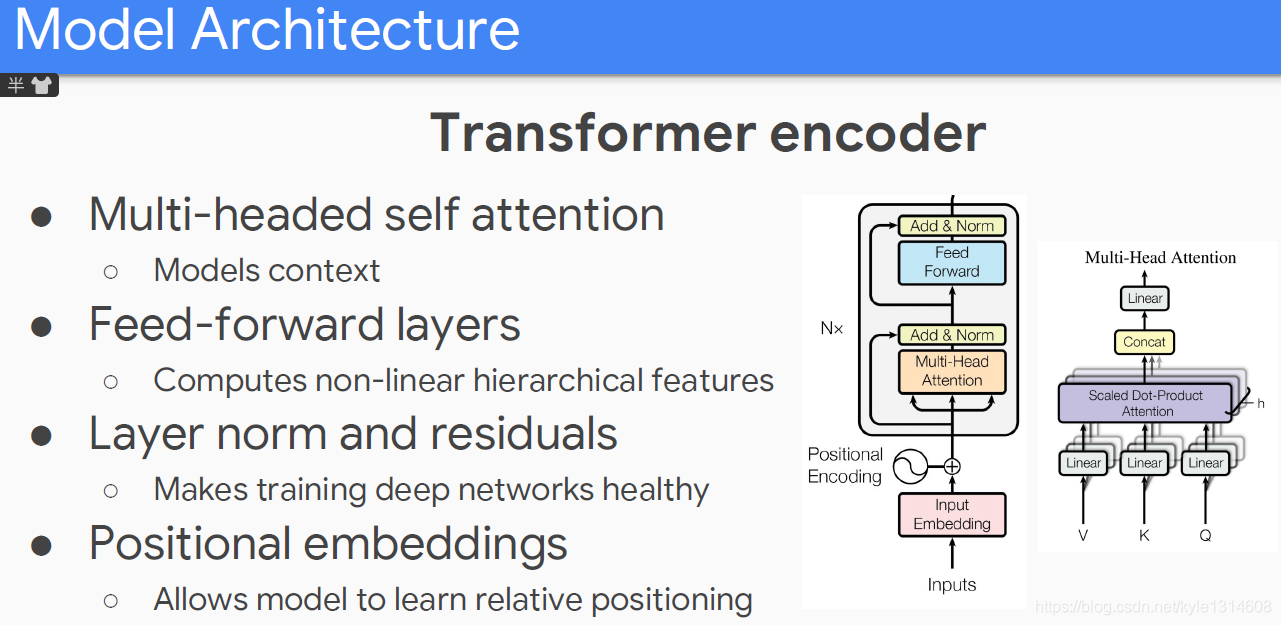
bert 各层结构的作用
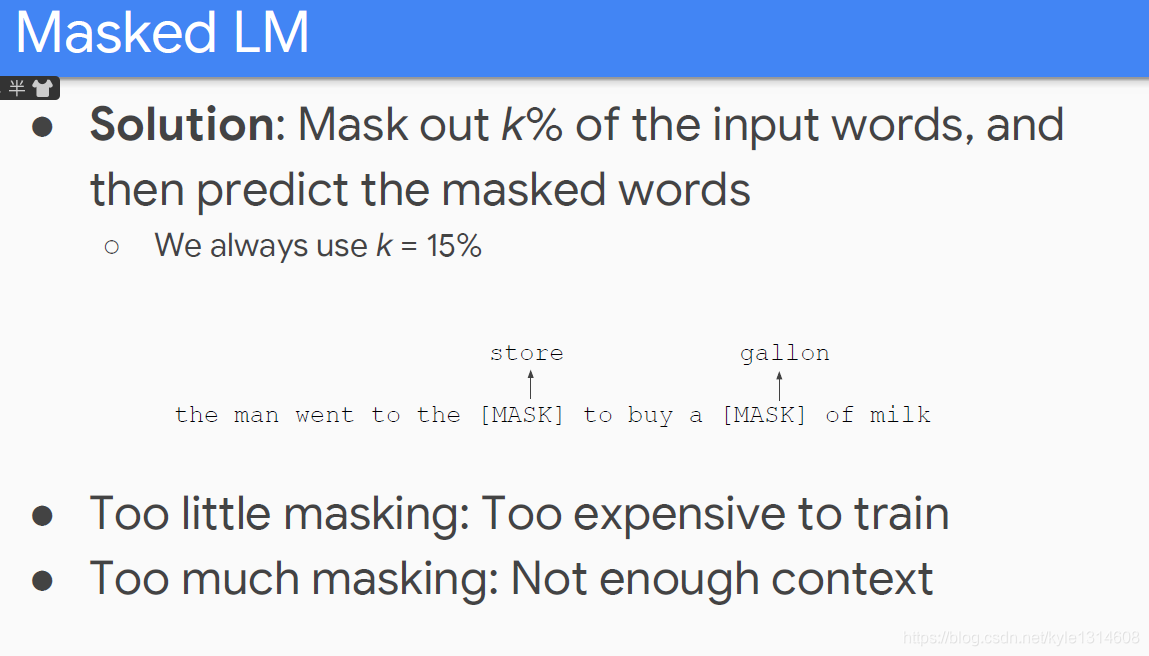
bert
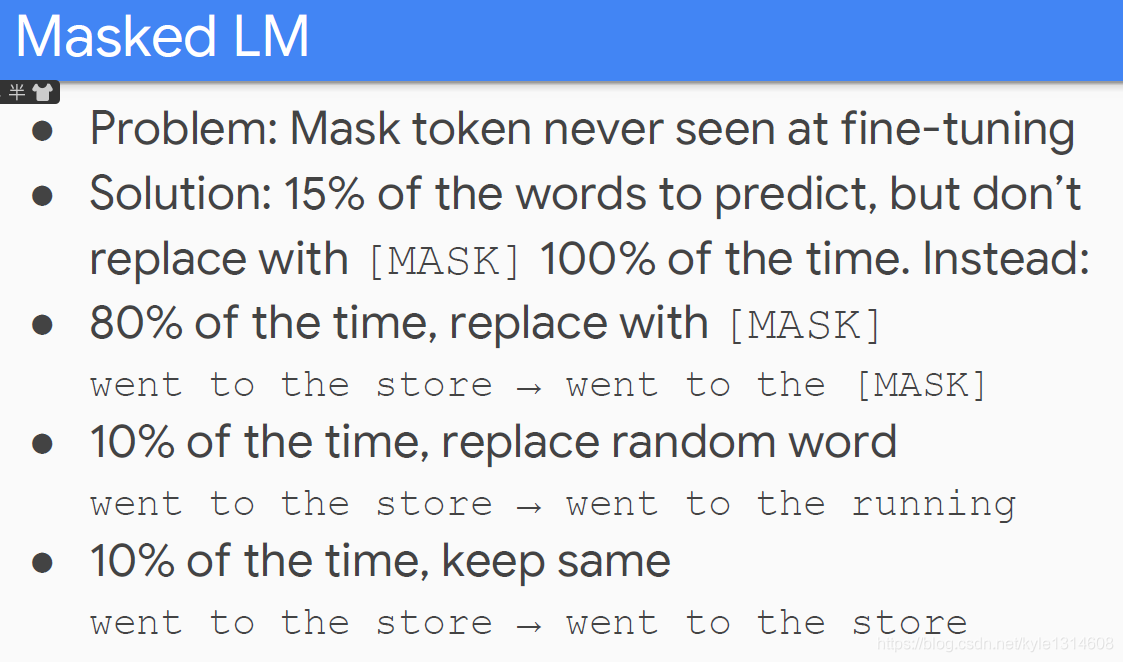
bert masked
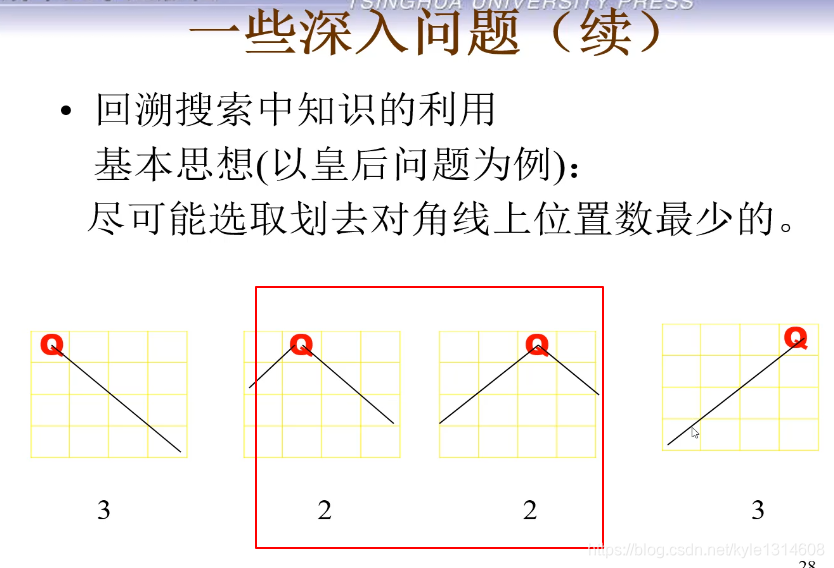
动态排序
动态排序 中间两个优先 边上两个滞后

八格游戏
通用规则和特殊规则相结合
需求发现:可以参看北京大学的软件工程


















 1068
1068

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









