



 本文介绍了层次聚类的基本概念及其常用算法AgglomerativeClustering的工作原理。重点讲解了如何通过不同规则来计算聚类间的距离,并提供了scikit-learn中该算法的使用方法及实例分析。
本文介绍了层次聚类的基本概念及其常用算法AgglomerativeClustering的工作原理。重点讲解了如何通过不同规则来计算聚类间的距离,并提供了scikit-learn中该算法的使用方法及实例分析。
层次聚类(hierarchical clustering)可在不同层次上对数据集进行划分,形成树状的聚类结构。AggregativeClustering是一种常用的层次聚类算法。
其原理是:最初将每个对象看成一个簇,然后将这些簇根据某种规则被一步步合并,就这样不断合并直到达到预设的簇类个数。这里的关键在于:如何计算聚类簇之间的距离?
由于每个簇就是一个集合,因此需要给出集合之间的距离。给定聚类簇Ci,CjCi,Cj,有如下三种距离:

Python实战
AgglomerativeClustering是scikit-learn提供的层级聚类算法模型,其原型为:
class sklearn.cluster.AgglomerativeClustering(n_clusters=2, affinity=’euclidean’, memory=None, connectivity=None, compute_full_tree=’auto’, linkage=’ward’, pooling_func=<function mean>)
参数
n_clusters:一个整数,指定分类簇的数量
connectivity:一个数组或者可调用对象或者None,用于指定连接矩阵
affinity:一个字符串或者可调用对象,用于计算距离。可以为:’euclidean’,’l1’,’l2’,’mantattan’,’cosine’,’precomputed’,如果linkage=’ward’,则affinity必须为’euclidean’
memory:用于缓存输出的结果,默认为不缓存
n_components:在 v-0.18中移除
compute_full_tree:通常当训练了n_clusters后,训练过程就会停止,但是如果compute_full_tree=True,则会继续训练从而生成一颗完整的树
linkage:一个字符串,用于指定链接算法
‘ward’:单链接single-linkage,采用dmindmin
‘complete’:全链接complete-linkage算法,采用dmaxdmax
‘average’:均连接average-linkage算法,采用davgdavg
pooling_func:一个可调用对象,它的输入是一组特征的值,输出是一个数
属性
labels:每个样本的簇标记
n_leaves_:分层树的叶节点数量
n_components:连接图中连通分量的估计值
children:一个数组,给出了每个非节点数量
方法
fit(X[,y]):训练样本
fit_predict(X[,y]):训练模型并预测每个样本的簇标记

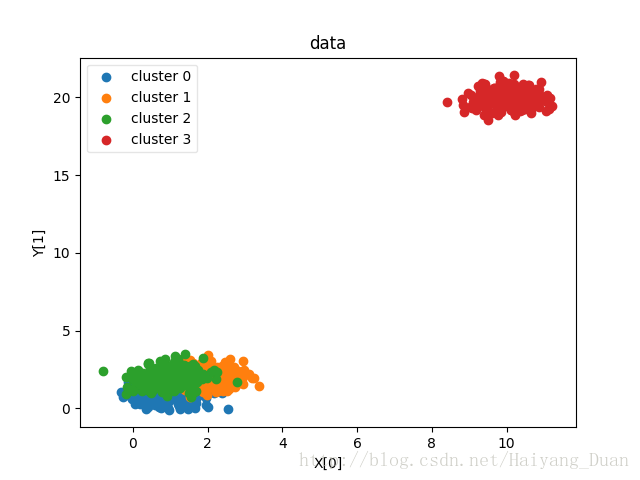


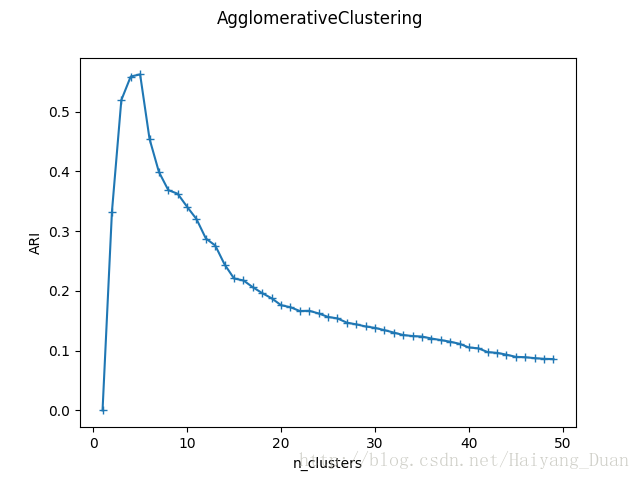
可以看到当n_clusters=4时,ARI指数最大,因为确实是从四个中心点产生的四个簇。
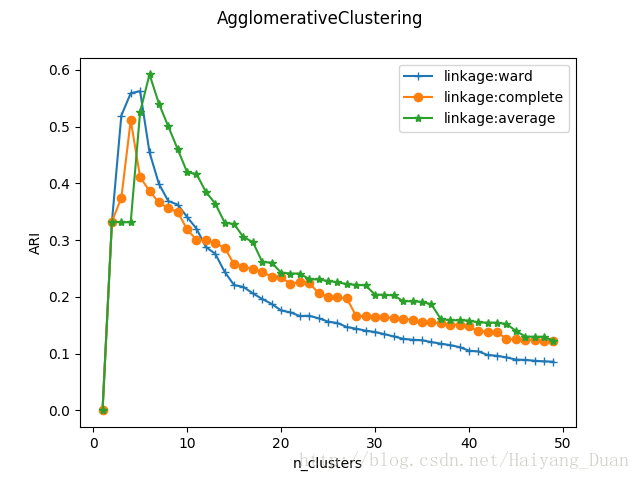
可以看到,三种链接方式随分类簇的数量的总体趋势相差无几。但是单链接方式ward的峰值最大,且峰值最大的分类簇的数量刚好等于实际生成的簇的数量。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









