高阶函数使用案例一
高阶函数就说一个函数可以传进来一个别的函数进行使用.
object HighOrderFunDemo02 {
def main(args: Array[String]): Unit = {
//使用高阶函数 sun2 _,不能写成sum2(),如果写成小括号表示调用函数,写成_表示传入一个函数
val res = test(sum2 _, 3.5)
println("res=" + res)
//在 scala 中,可以把一个函数直接赋给一个变量,但是不执行函数
val f1 = myPrint _
f1() //执行
}
def myPrint(): Unit = {
println("hello,world!")
}
//说明
//1. test 就是一个高阶函数
//2. f: Double => Double 表示一个函数, 该函数可以接受一个 Double,返回 Double
//3. n1: Double 普通参数
//4. f(n1) 在 test 函数中,执行 你传入的函数
def test(f: Double => Double, n1: Double) = {
f(n1)
}
//普通的函数, 可以接受一个 Double,返回 Double
def sum2(d: Double): Double = {
println("sum2 被调用")
d + d
}
}
高阶函数使用案例二
object HighOrderFunDemo02 {
def main(args: Array[String]): Unit = {
test2(sayOK)
}
//说明 test2 是一个高阶函数,可以接受一个 没有输入,返回为 Unit 的函数
def test2(f: () => Unit) = {
f()
}
def sayOK() = {
println("sayOKKK...")
}
def sub(n1:Int): Unit = {
}
}
以下所有高阶函数都是给集合使用的
map高阶函数案例
object TestMap {
def main(args: Array[String]): Unit = {
/*
请将 List(3,5,7) 中的所有元素都 * 2 ,
将其结果放到一个新的集合中返回,即返回一个新的 List(6,10,14), 请编写程序实现.
*/
val list = List(3, 5, 7, 9)
//说明 list.map(multiple) 做了什么
//1. 将 list 这个集合的元素 依次遍历
//2. 将各个元素传递给 multiple 函数 => 新 Int
//3. 将得到新 Int ,放入到一个新的集合并返回
//4. 因此 multiple 函数调用 3
val list2 = list.map(multiple)
println("list2=" + list2) //List(6,10,14)
}
def multiple(n: Int): Int = {
println("multiple 被调用~~")
2 * n
}
}
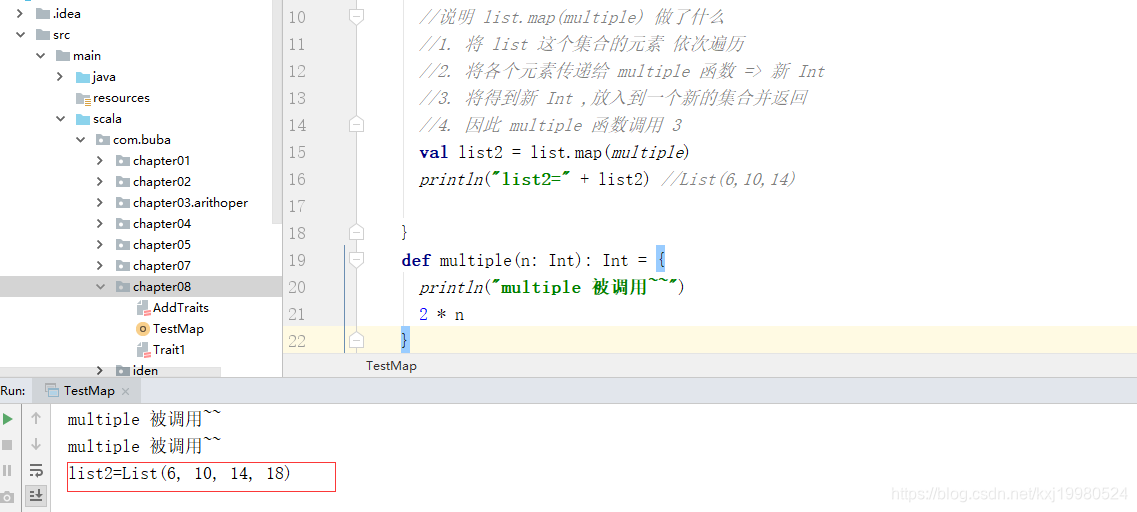
flatmap 映射:flat 即压扁,压平,扁平化映射
flatmap:flat 即压扁,压平,扁平化,效果就是将集合中的每个元素的子元素映射到某个函数并返
回新的集合。
object Test {
def main(args: Array[String]): Unit = {
val names = List("Alice", "Bob", "Nick")
//需求是将 List 集合中的所有元素,进行扁平化操作,即把所有元素打散
val names2 = names.flatMap(upper)
println("names2=" + names2)
}
def upper(s: String): String = {
s.toUpperCase
}
}
集合元素的过滤-filter
filter的高阶函数,返回值为boolean类型,true的留下,false的舍去.底层跟map一样也是循环遍历.
object TestMap {
def main(args: Array[String]): Unit = {
/*
选出首字母为 A 的元素
*/
val names = List("Alice", "Bob", "Nick")
val names2 = names.filter(startA)
println("names=" + names)
println("names2=" + names2)
}
def startA(str:String): Boolean = {
str.startsWith("A")
}
}
化简reduce,reduceLeft,reduceRight
底层是进行递归操作.
1) def reduceLeft[B >: A](@deprecatedName('f) op: (B, A) => B): B
2) reduceLeft(f) 接收的函数需要的形式为 op: (B, A) => B): B
3) reduceleft(f) 的运行规则是 从左边开始执行将得到的结果返回给第一个参数
4) 然后继续和下一个元素运行,将得到的结果继续返回给第一个参数,继续..
即: //((((1 + 2) + 3) + 4) + 5) = 15
5)reduceRight就是从右往左执行,把结果返回给前面一个值
6)reduce就说reduceLift
object TestMap {
def main(args: Array[String]): Unit = {
/*
使用化简的方式来计算 list 集合的和
*/
val list = List(1, 20, 30, 4, 5)
val res = list.reduceLeft(sum) // reduce/reduceLeft/reduceRight
//执行的流程分析
//步骤 1 (1 + 20)
//步骤 2 (1 + 20) + 30
//步骤 3 ((1 + 20) + 30) + 4
//步骤 4 (((1 + 20) + 30) + 4) + 5 = 60
println("res=" + res) // 60
}
def sum(n1: Int, n2: Int): Int = {
println("sum 被调用~~")
n1 + n2
}
}
object TestMap {
def main(args: Array[String]): Unit = {
val list = List(1, 2, 3, 4, 5)
def minus(num1: Int, num2: Int): Int = {
num1 - num2
}
// (((1-2) - 3) - 4) - 5 = -13
println(list.reduceLeft(minus)) // 输出? -13
// 1 - (2 - (3 -(4 - 5))) = 3
println(list.reduceRight(minus)) //输出? 3
// reduce 等价于 reduceLeft
println(list.reduce(minus))
println("minval=" + list.reduceLeft(min)) // 1
}
//求出最小值
def min(n1: Int, n2: Int): Int = {
if (n1 > n2) n2 else n1
}
}
折叠fold,foldLeft,foldRight
fold 函数将上一步返回的值作为函数的第一个参数继续传递参与运算,直到 list 中的所有元素被遍
历。
可以把 reduceLeft 看做简化版的 foldLeft。
如何理解:
def reduceLeft[B >: A](@deprecatedName('f) op: (B, A) => B): B =
if (isEmpty) throw new UnsupportedOperationException("empty.reduceLeft")
else tail.foldLeft[B](head)(op)
大家可以看到. reduceLeft就是调用的foldLeft[B](head),并且是默认从集合的head元素开始操作的。
相关函数:fold,foldLeft,foldRight,可以参考 reduce 的相关方法理解
7)list.fold(5)(minus) 这个5先传入minus函数的第一个参数,所以5的类型得和minus函数第一个参数类型一致.minus函数第二个参数才是从集合中遍历.
object TestMap {
def main(args: Array[String]): Unit = {
val list = List(1, 2, 3, 4)
def minus(num1: Int, num2: Int): Int = {
num1 - num2
}
println(list.fold(5)(minus))
//说明
//1. 折叠的理解和化简的运行机制几乎一样.
//理解 list.foldLeft(5)(minus) 理解成 list(5,1, 2, 3, 4) list.reduceLeft(minus)
//步骤 (5-1)
//步骤 ((5-1) - 2)
//步骤 (((5-1) - 2) - 3)
//步骤 ((((5-1) - 2) - 3)) - 4 = - 5
println(list.foldLeft(5)(minus)) // 函数的柯里化
////理解 list.foldRight(5)(minus) 理解成 list(1, 2, 3, 4, 5) list.reduceRight(minus)
// 步骤 (4 - 5)
// 步骤 (3- (4 - 5))
// 步骤 (2 -(3- (4 - 5)))
// 步骤 1- (2 -(3- (4 - 5))) = 3
println(list.foldRight(5)(minus)) //
}
}
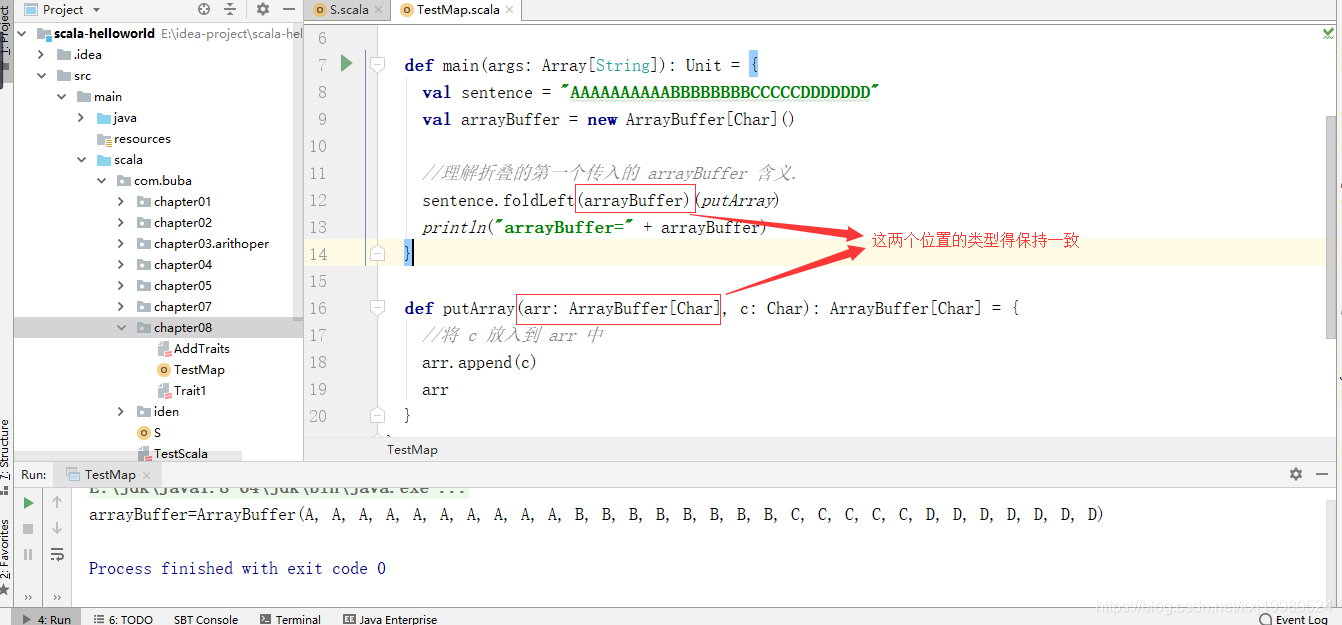
foldLeft 和 foldRight 缩写方法分别是:/:和:\
object TestMap {
def main(args: Array[String]): Unit = {
val list4 = List(1, 9)
def minus(num1: Int, num2: Int): Int = {
num1 - num2
}
var i6 = (1 /: list4) (minus) // =等价=> list4.foldLeft(1)(minus)
println("i6=" + i6)
i6 = (100 /: list4) (minus) //=等价=> list4.foldLeft(100)(minus)
println(i6) // 输出?
i6 = (list4 :\ 10) (minus) // list4.foldRight(10)(minus)
println(i6) // 输出? 2
}
}
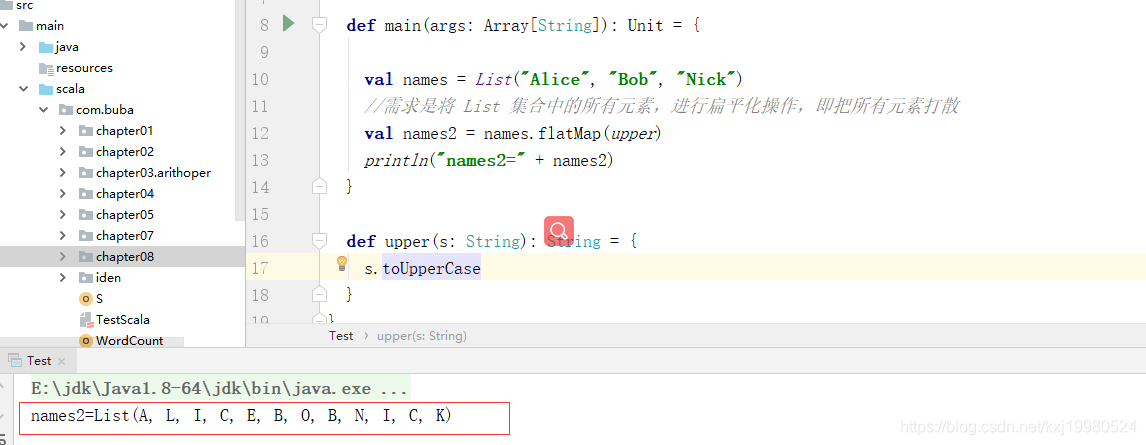
案例二
val sentence = "AAAAAAAAAABBBBBBBBCCCCCDDDDDDD"将 sentence 中各个字符,通过
foldLeft 存放到 一个 ArrayBuffer 中,目的:理解 flodLeft 的用法. ArrayBufer('A','A','A'..)
object TestMap {
import scala.collection.mutable.ArrayBuffer
def main(args: Array[String]): Unit = {
val sentence = "AAAAAAAAAABBBBBBBBCCCCCDDDDDDD"
val arrayBuffer = new ArrayBuffer[Char]()
//理解折叠的第一个传入的 arrayBuffer 含义.
sentence.foldLeft(arrayBuffer)(putArray)
println("arrayBuffer=" + arrayBuffer)
}
def putArray(arr: ArrayBuffer[Char], c: Char): ArrayBuffer[Char] = {
//将 c 放入到 arr 中
arr.append(c)
arr
}
}
案例三
使用映射集合,统计一句话中,各个字母出现的次数
object TestMap {
import scala.collection.mutable
def main(args: Array[String]): Unit = {
val sentence = "AAAAAAAAAABBBBBBBBCCCCCDDDDDDD"
val map2 = sentence.foldLeft(Map[Char, Int]())(charCount)
println("map2=" + map2)
//使用可变的 map,效率更高.
//1. 先创建一个可变 map,作为左折叠的第一个参数
val map3 = mutable.Map[Char, Int]()
sentence.foldLeft(map3)(charCount2)
println("map3=" + map3)
}
//使用不可变 map 实现
def charCount(map: Map[Char, Int], char: Char): Map[Char, Int] = {
map + (char -> (map.getOrElse(char, 0) + 1))
}
//使用可变 map 实现
def charCount2(map: mutable.Map[Char, Int], char: Char): mutable.Map[Char, Int] = {
map += (char -> (map.getOrElse(char, 0) + 1))
}
}
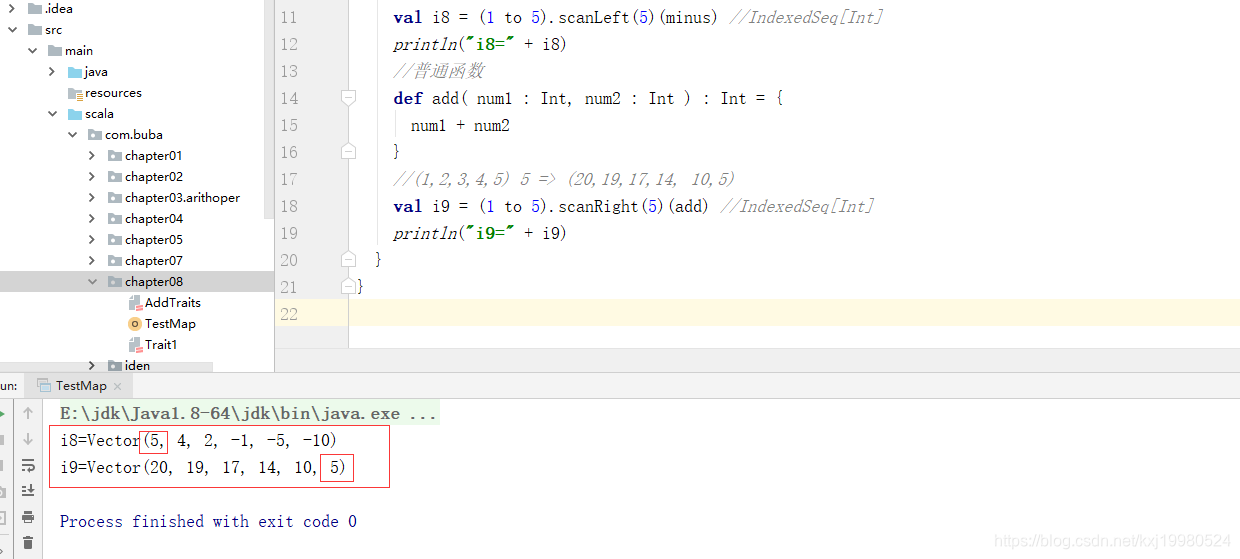
扫描
扫描,即对某个集合的所有元素做 fold 操作,但是会把产生的 所有中间结果放置于一个集合中保存
只不过会把传入的参数也放入到集合当中.
object TestMap {
def main(args: Array[String]): Unit = {
//普通函数
def minus( num1 : Int, num2 : Int ) : Int = {
num1 - num2
}
//5 (1,2,3,4,5) =>(5, 4, 2, -1, -5, -10) //Vector(5, 4, 2, -1, -5, -10)
val i8 = (1 to 5).scanLeft(5)(minus) //IndexedSeq[Int]
println("i8=" + i8)
//普通函数
def add( num1 : Int, num2 : Int ) : Int = {
num1 + num2
}
//(1,2,3,4,5) 5 => (20,19,17,14, 10,5)
val i9 = (1 to 5).scanRight(5)(add) //IndexedSeq[Int]
println("i9=" + i9)
}
}
拉链(合并)
在开发中,当我们需要将两个集合进行 对偶元组合并,可以使用拉链
1) 拉链的本质就是两个
2) 操作的规则下图:

3) 如果两个集合个数不对应,会造 成数据丢失。多出来的就不要了
4) 集合不限于 List, 也可以是其它集合比如 Array
5) 如果要取出合并后的各个对偶元组的数据,可以遍历
object TestMap {
def main(args: Array[String]): Unit = {
// 拉链
val list1 = List(1, 2, 3)
val list2 = List(4, 5, 6)
val list3 = list1.zip(list2) // (1,4),(2,5),(3,6)
println("list3=" + list3)
//遍历
for(item<-list3){
print(item._1 + " " + item._2) //取出时,按照元组的方式取出即可
}
}
}
迭代器
通过 iterator 方法从集合获得一个迭代器,通过 while 循环和 for 表达式对集合进行遍历.(学习使用
迭代器来遍历)
1) iterator 的构建实际是 AbstractIterator 的一个匿名子类,该子类提供了
/*
def iterator: Iterator[A] = newAbstractIterator[A] {
var these = self
def hasNext: Boolean = !these.isEmpty
def next():A=
*/
2) 该 AbstractIterator 子类提供了 hasNext next 等方法.
3) 因此,我们可以使用 while 的方式,使用 hasNext next 方法变量
object TestMap {
def main(args: Array[String]): Unit = {
val iterator = List(1, 2, 3, 4, 5).iterator // 得到迭代器
/*
这里我们看看 iterator 的继承关系
def iterator: Iterator[A] = newAbstractIterator[A] {
var these = self
def hasNext: Boolean = !these.isEmpty
def next():A=
if (hasNext) {
val result = these.head; these = these.tail; result
} else Iterator.empty.next()
*/
println("--------遍历方式 1 while -----------------")
while (iterator.hasNext) {
println(iterator.next())
}
println("--------遍历方式 2 for -----------------")
for(enum <- iterator) {
println(enum) //
}
}
}
流 Stream
stream 是一个集合。这个集合,可以用于存放 无穷多个元素,但是这无穷个元素并不会一次性生
产出来,而是需要用到多大的区间,就会动态的生产, 末尾元素遵循 lazy 规则(即:要使用结果才进行计算的)
说明
1) Stream 集合存放的数据类型是 BigInt
2) numsForm 是自定义的一个函数,函数名是程序员指定的。
3) 创建的集合的第一个元素是 n , 后续元素生成的规则是 n + 1
4) 后续元素生成的规则是可以程序员指定的 ,比如 numsForm( n * 4)...
注意:如果使用流集合,就不能使用last属性,如果使用last集合就会进入无限循环
object TestMap {
def main(args: Array[String]): Unit = {
//创建 Stream
def numsForm(n: BigInt): Stream[BigInt] = n #:: numsForm(n + 1)
val stream1 = numsForm(1)
println(stream1) //
//取出第一个元素
println("head=" + stream1.head) //
println(stream1.tail) // 当对流执行 tail 操作时,就会生成一个新的数据.
println(stream1) //?
}
}
视图 View
Stream 的懒加载特性,也可以对其他集合应用 view 方法来得到类似的效果,具有如下特点:
1) view 方法产出一个总是 被懒执行的集合。
2) view 不会缓存数据,每次都要重新计算,比如遍历 View 时。
object TestMap {
def main(args: Array[String]): Unit = {
def multiple(num: Int): Int = {
num
}
//如果这个数,逆序后和原来数相等,就返回 true,否则返回 false
def eq(i: Int): Boolean = {
println("eq 被调用..")
i.toString.equals(i.toString.reverse)
}
//说明: 没有使用 view,常规方式
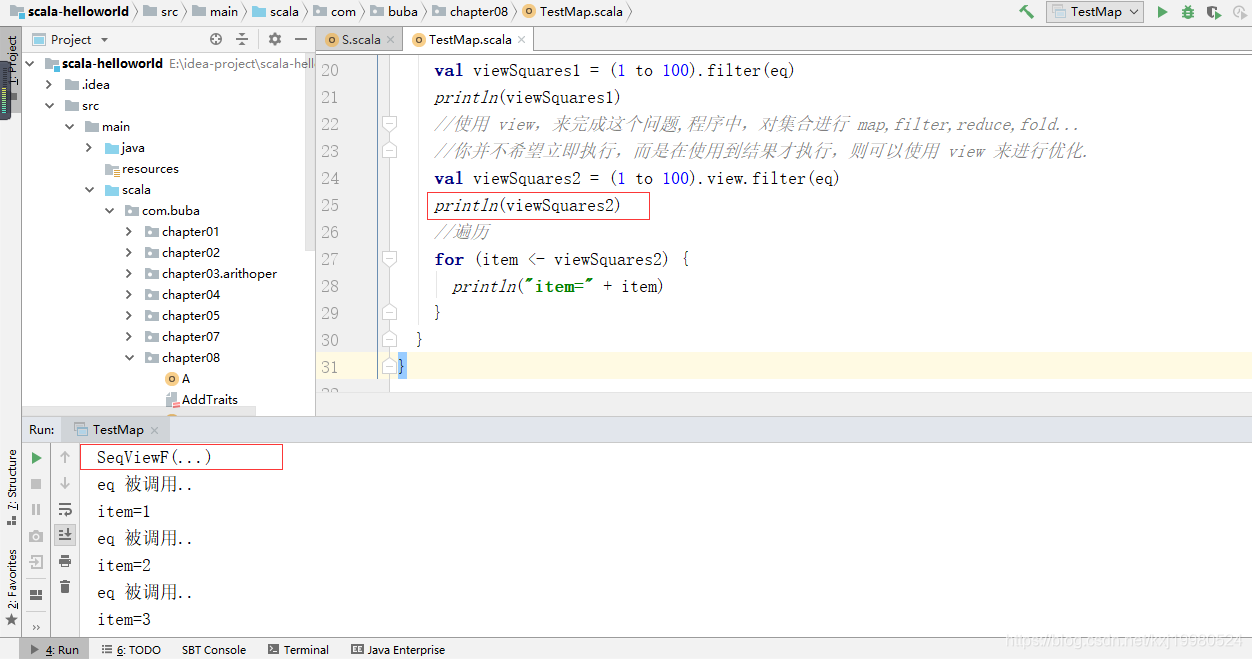
val viewSquares1 = (1 to 100).filter(eq)
println(viewSquares1)
//使用 view,来完成这个问题,程序中,对集合进行 map,filter,reduce,fold...
//你并不希望立即执行,而是在使用到结果才执行,则可以使用 view 来进行优化.
val viewSquares2 = (1 to 100).view.filter(eq)
println(viewSquares2)
//遍历
for (item <- viewSquares2) {
println("item=" + item)
}
}
}
直接打印view的话,是不会执行的,只有在调用,比如遍历的时候才会调用view
并行集合
1) Scala 为了充分使用多核 CPU,提供了并行集合(有别于前面的串行集合),用于多核环境的
并行计算。
2) 主要用到的算法有:
Divide and conquer : 分治算法,Scala 通过 splitters(分解器),combiners(组合器)等抽象层来实现,
主要原理是将计算工作分解很多任务,分发给一些处理器去完成,并将它们处理结果合并返回
Work stealin 算法【学数学】,主要用于任务调度负载均衡(load-balancing),通俗点完成自己的
所有任务之后,发现其他人还有活没干完,主动(或被安排)帮他人一起干,这样达到尽早干完的目
的
加上pre方法就多cpu运行了,这样能提高效率.
object TestMap {
def main(args: Array[String]): Unit = {
(1 to 5).foreach(println(_))
println()
(1 to 5).par.foreach(println(_))
}
}
object ParDemo02 {
def main(args: Array[String]): Unit = {
//.distinct 去除相同的结果集
val result1 = (0 to 100).map{case _ => Thread.currentThread.getName}.distinct
val result2 = (0 to 100).par.map{case _ => Thread.currentThread.getName}.distinct
println(result1) //非并行
println("--------------------------------------------")
println(result2) //并行
}
}








 本文深入探讨Scala中的高阶函数概念,包括其定义、使用案例及与集合操作的结合,如map、filter、reduce等功能,展示了Scala强大的函数式编程特性。
本文深入探讨Scala中的高阶函数概念,包括其定义、使用案例及与集合操作的结合,如map、filter、reduce等功能,展示了Scala强大的函数式编程特性。

















 502
502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









