







mysql配置文件详解:
[client]
#默认登录的账号
user=root
#默认登录的密码
password=1111aaAA_
#默认登录时socket位置
socket=/tmp/mysql.sock
[mysql]
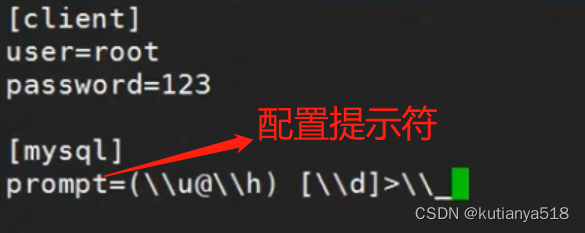
#显示用户名主机库名信息
prompt=(\\u@\\h) [\\d]>\\_
#禁用tab自动补全
no-auto-rehash
[mysqld]
server-id=1
prot = 3306
user = mysql
datadir = /mydata/mysql_test_data
log_error = error.log
#密码复杂度
plugin-load=validate_password.so
#跳过密码校验进入mysql
#skip-grant-tables
#设置密码永不过期
default_password_lifetime=0
#开启事件
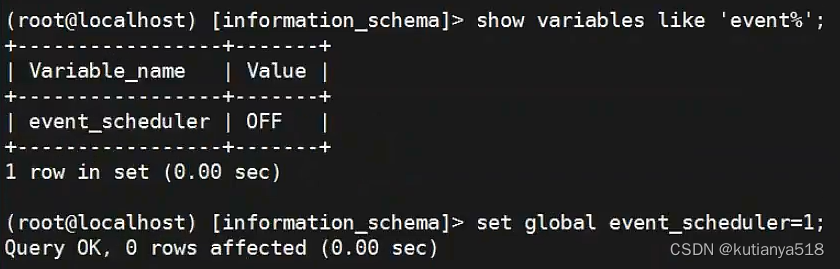
event_scheduler=1
#charset字符集
#utf8mb4能够存储更大得字符
characset_set_server = utf8mb4
# session memory
#提升排序效率
sort_buffer_size = 32M
#提示group by 效率
tmp_table_size = 32M
#innodb
innodb_buffer_pool_size =1G
innodb_log_file_size=128M
#设大避免在线修改索引失败
innodb_online_alter_log_max_size=512M
#禁用其他存储引擎只用innodb
skip-federated
skip-archive
skip-blackhole
#log慢日志
#开启慢日志
slow_query_log=1
#慢日志文件目录
slow_query_log_file=slow.log
#慢查询时间默认10s
long_query_time=5
#配置单机多实例---开始
[mysqld_multi]
#配置多实例启动命令,通过守护进程方式启动
mysqld= /user/local/mysql/bin/mysql_safe
#配置多实例停止命令
mysqladmin=/user/local/mysql/bin/mysqladmin
#配置mysqld_multi日志
log =/user/local/mysql/mysqld_multi.log
[mysqld1]
server-id=11
prot = 3307
datadir = /mydata/mysql_test_data1
socket=/tmp/mysql.sock1
[mysqld2]
server-id=12
prot = 3308
datadir = /mydata/mysql_test_data2
socket=/tmp/mysql.sock2
#配置单机多实例---结束
一、mysql安装与基本配置
1、mysql配置文件my.cnf
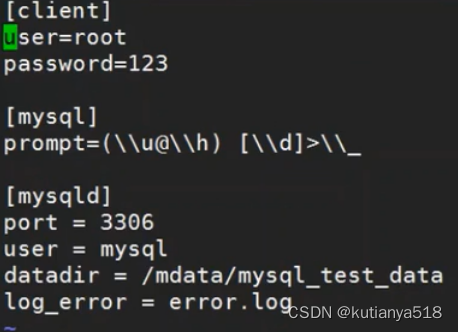
mysql配置提示符如下所示:
如下所示:
2、mysql登录后设置密码:set password = 'mypassword'
3、查看mysql 默认参数值:mysqld --help --verboss
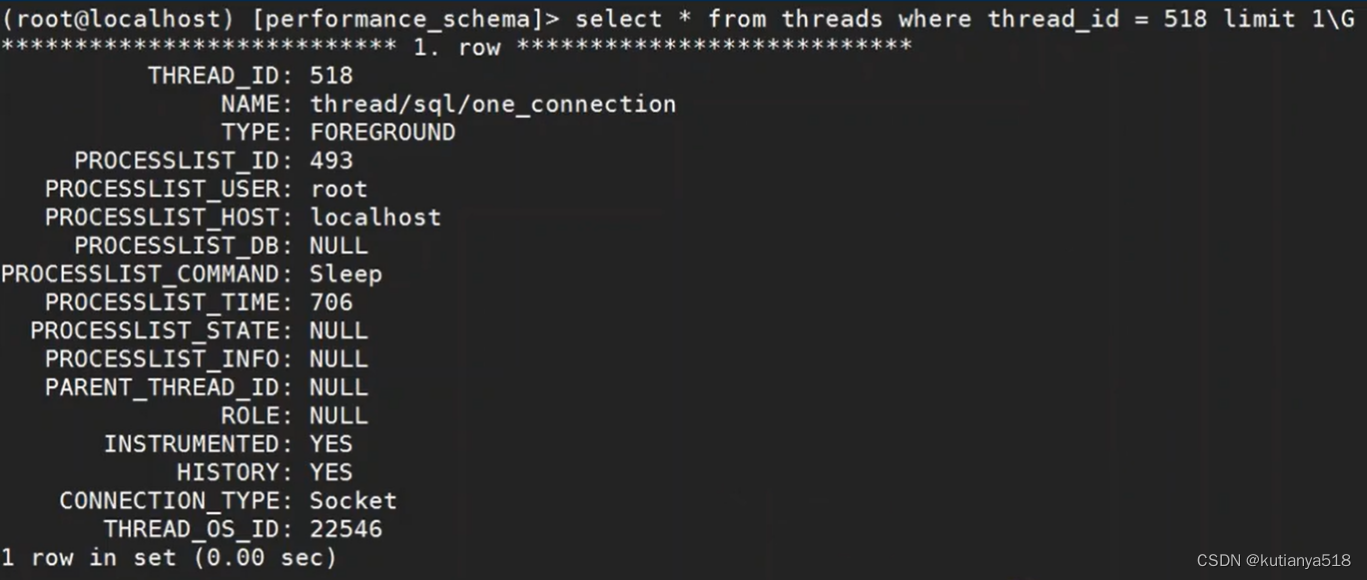
4、查看mysql当前连接的线程:
通过threads表查看对应线程详情:
二、mysql单机多实例
1、一台服务器上安装多个MySQL实列,通过mysqld_multi程序即可,如下所示,如果想针对某个实例配置自己参数,则可专门配置,否则会继承[mysqld]下参数,其他实例通过mysqld_muti start/stop/report 进行启动,停止,查看状态
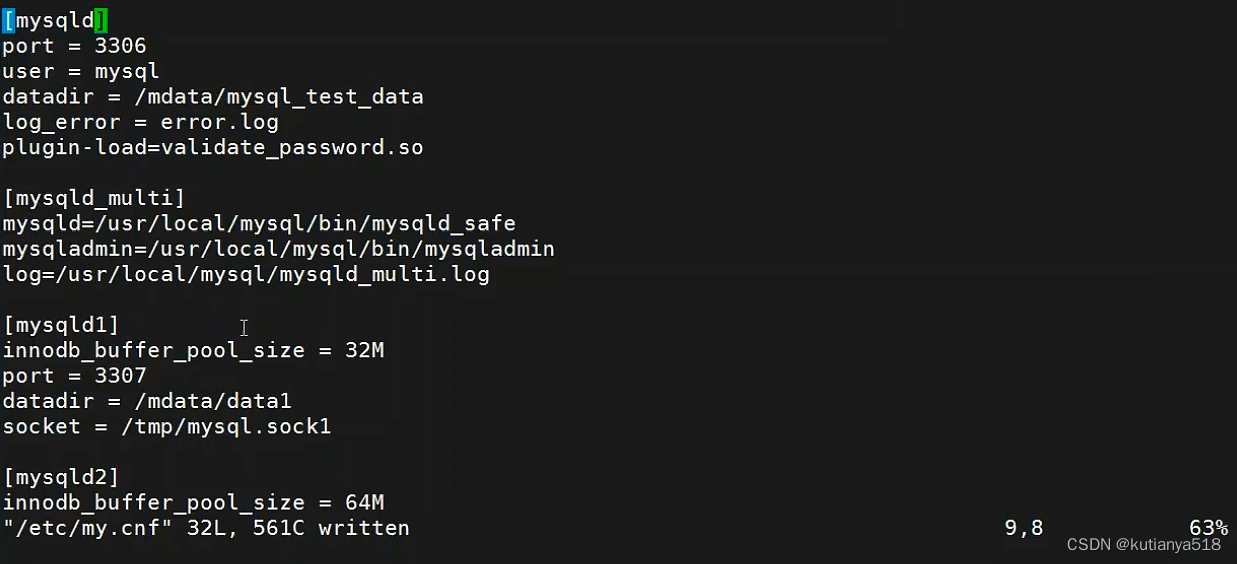
2、mysql忘记密码解决方式
配置文件下如[mysqld]下增加跳过验证参数skip-grant-tables,进入mysql,修改user表下指定用户的密码,然后重启mysql:

三、mysql数据类型
1、INT数据类型
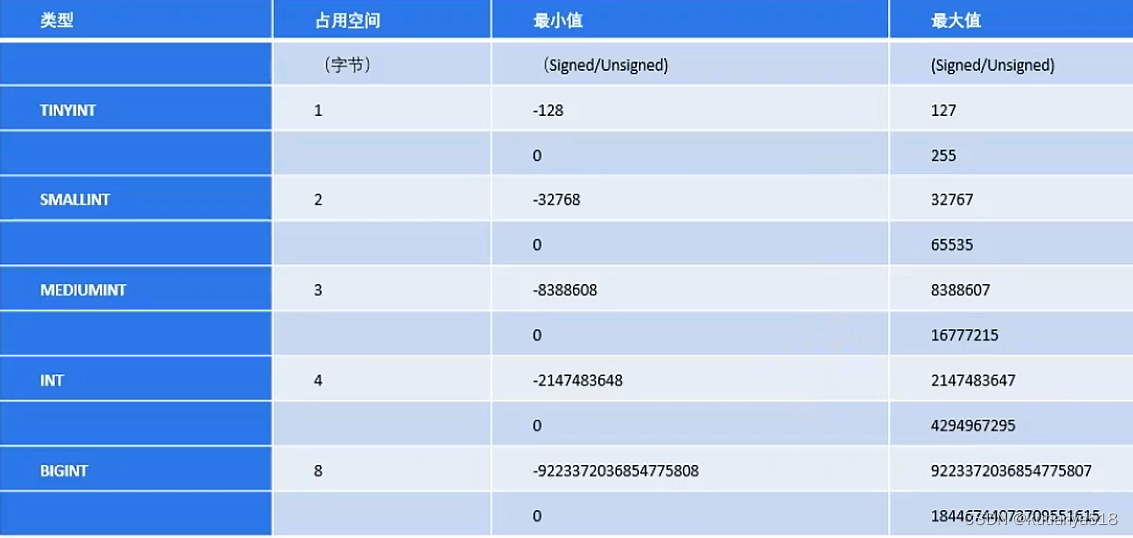 int类型:不要使用unsigned,因为有可能会溢出,自增int类型主键采用bigInt
int类型:不要使用unsigned,因为有可能会溢出,自增int类型主键采用bigInt
2、数字类型

生产中尽量使用高精度DECIMAL,尤其是做金钱、统计或其他计算时。
3、字符串类型
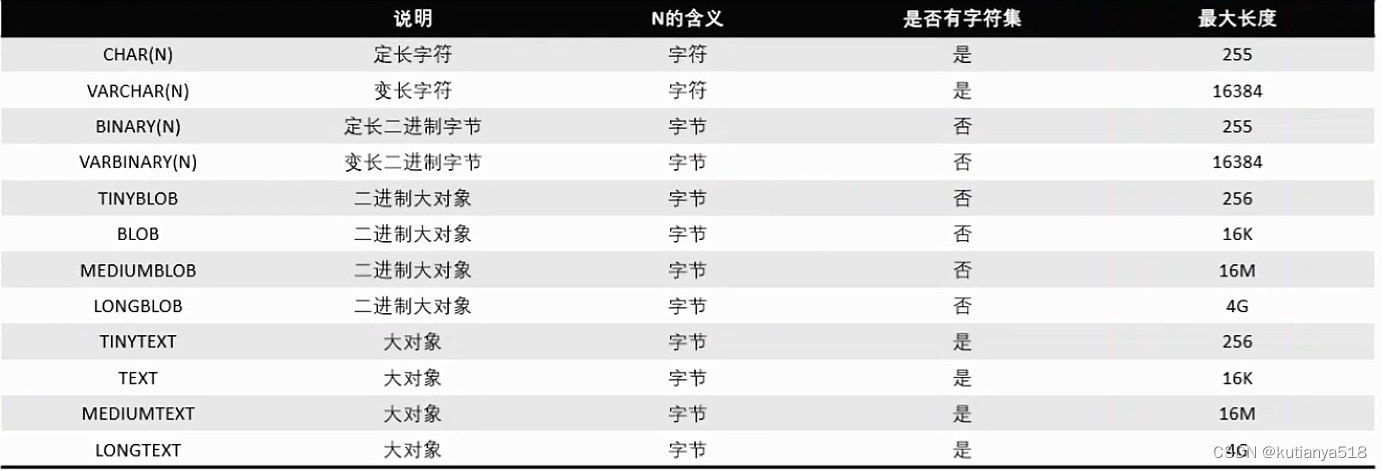 4、日期类型
4、日期类型
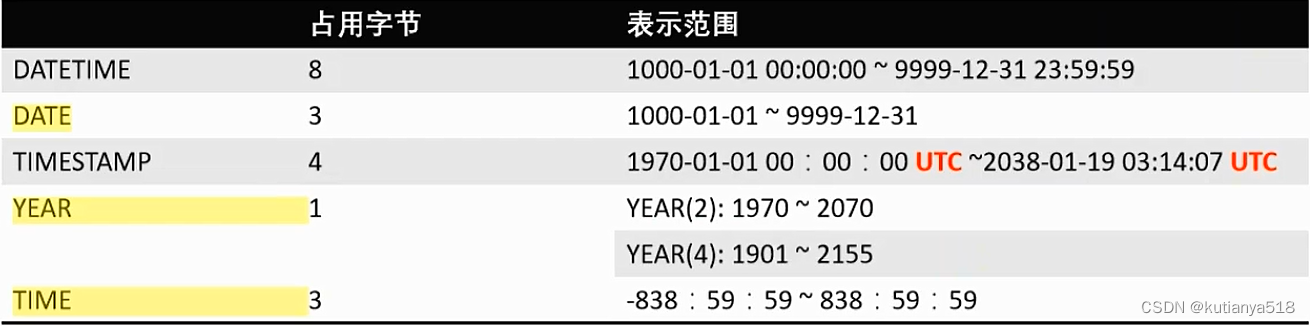
日期函数
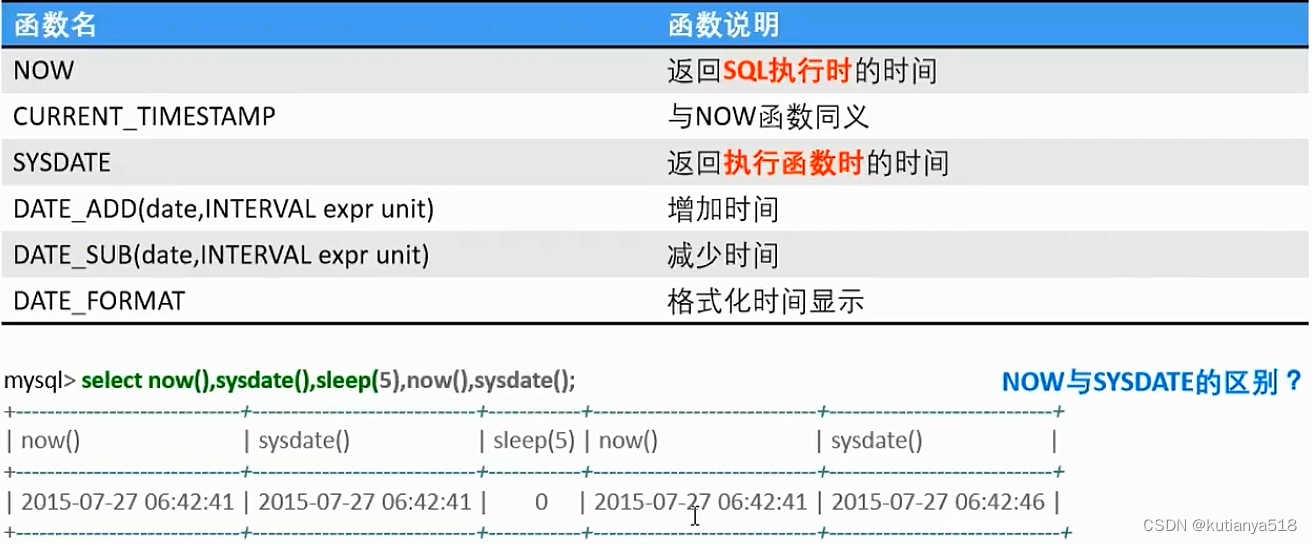 5、JSON类型
5、JSON类型

使用场景:如电商中得商品属性,或者用户信息的额外属性
四、Mysql语法
1、查看表的InnoDB引擎及表大小(sys.format_bytes)
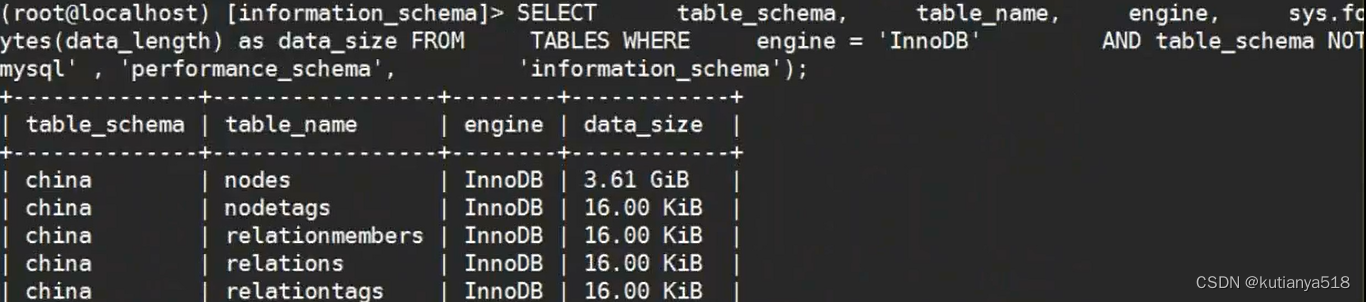
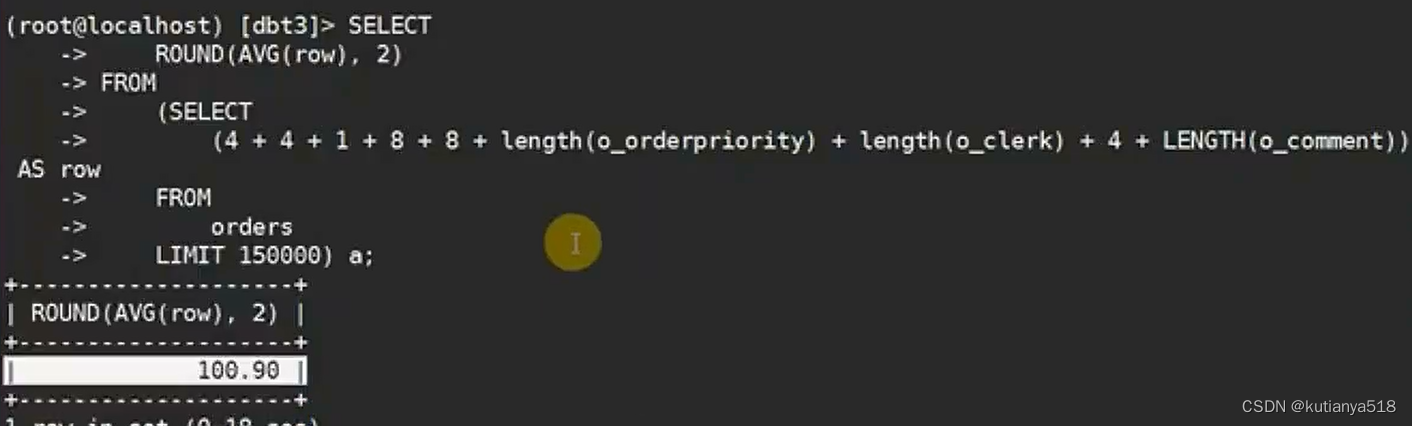
如何计算单表中,每条数据的大小:
length(字符串类型)=字节数,int 4字节,doble8字节,如下所示:计算出15w条数据平均每条占的字节数
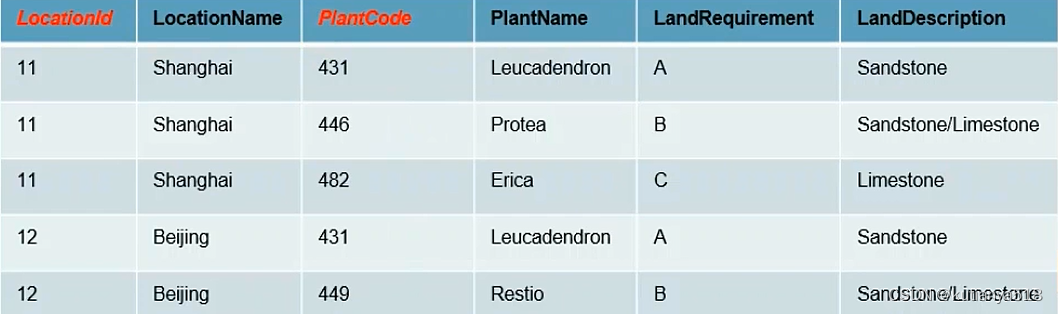
2、mysql三大范式:
1NF:原子性,字段不能再拆分,有主键
2NF:满足1NF,产生部分依赖(比如表中有些字典类键值字段)
3NF:满足2NF,消除传递依赖(比如消除了字典类键值字段)
如下图所示:1张表(满足1NF--LocationId,PlantCode做联合主键)拆成4张表
满足1NF:
拆成满足2NF:
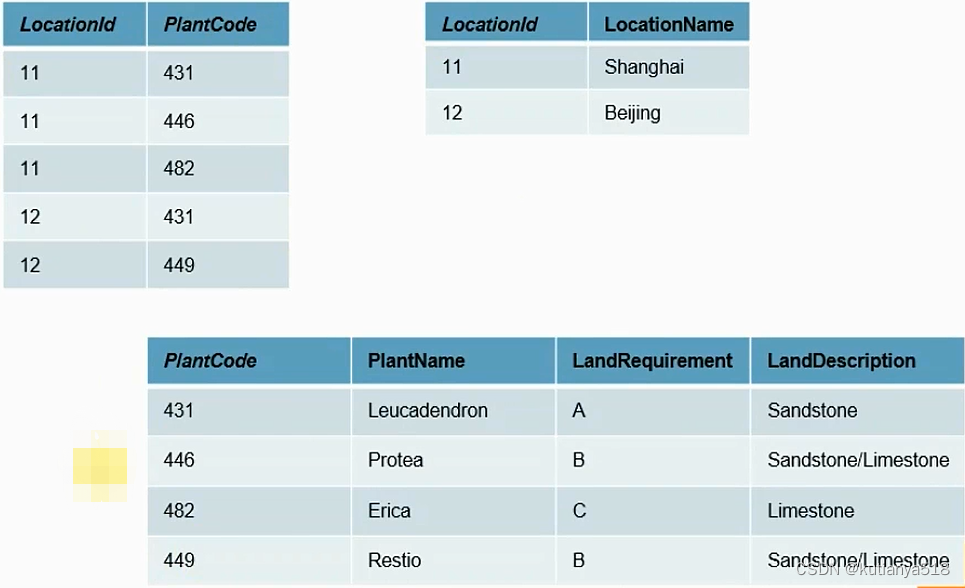
拆成满足3NF:
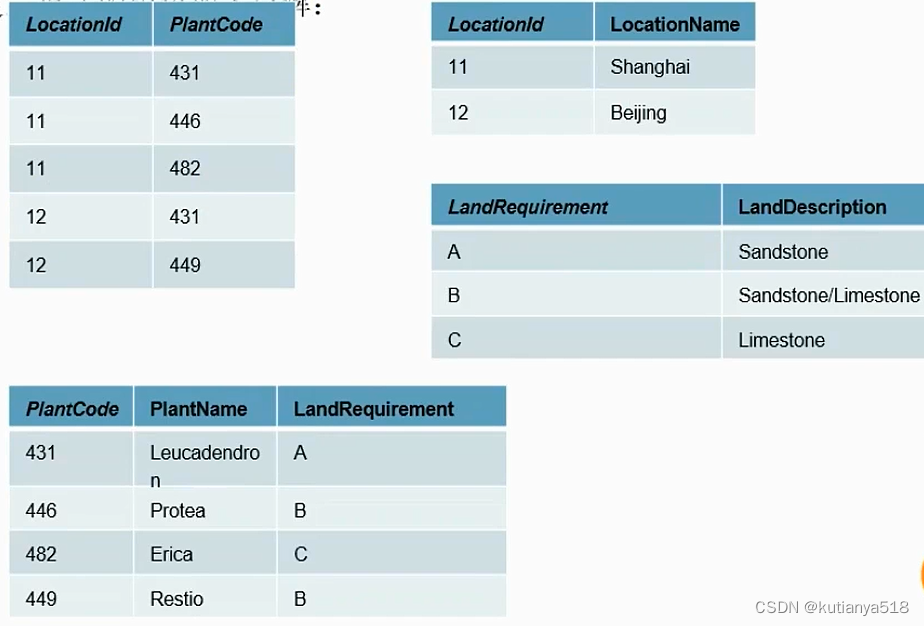
3、Group by 分组
1、通过多字段多重分组聚合, #提高性能的参数设置tmp_table_size大小,可避免group by 临时表存储磁盘:建议my.cnf设置 tmp_table_size = 32M
select user_id, DATE_FORMAT(orderDate,'%Y-%-m'),count(1),sum(price),avg(price) from orders group by DATE_FORMAT(orderDate,'%Y-%-m'),user_id
2、统计数量:count(1),count(*),count(字段)
count是统计的意思,count(数字)与count(*)得到得结果一样,而count(字段)得到的结果是统计该字段不为null的数量:

3、Having是对聚合函数的一种过滤
select user_id, DATE_FORMAT(orderDate,'%Y-%-m'),count(1),sum(price),avg(price) from orders group by DATE_FORMAT(orderDate,'%Y-%-m'),user_id HAVING count(1)>2
4、group_concat(字段 order by 字段 seperator ":")分组之后把组内数据按照某个字段排序,并用冒号":"拼接,默认是逗号","
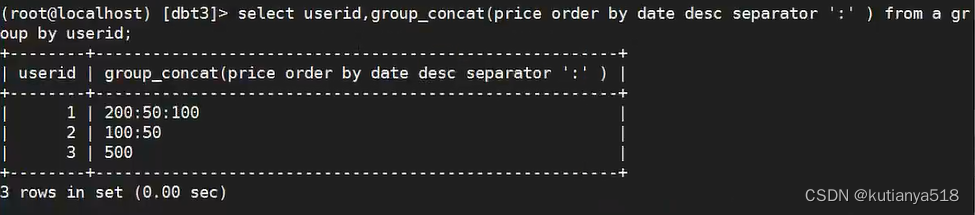
4、JOIN表关联
1、in子查询,可使用多字段----(字段1,字段2)in (select 字段1,max(字段2) from tables)
查询员工最新职位:
select emp_no,title from titles where (emp_no,to_date) in (select emp_no,max(to_date) from titles group by emp_no)
2、mysql行号:通过变量行成单例,巧用笛卡儿积
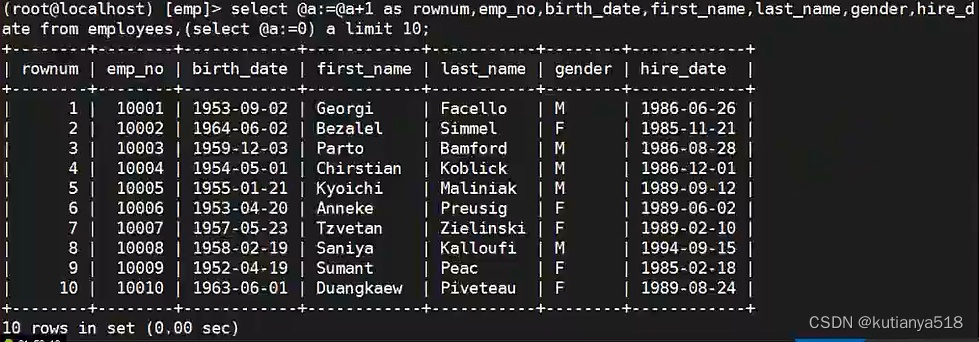
另一种效率非常低,却理解有点费劲的相关子查询方式:
select emp_no ,(select count(*) from employees t2 where t1.emp_no <=t2.emp_no) as rownum where employees t1 order by emp_no limit 10
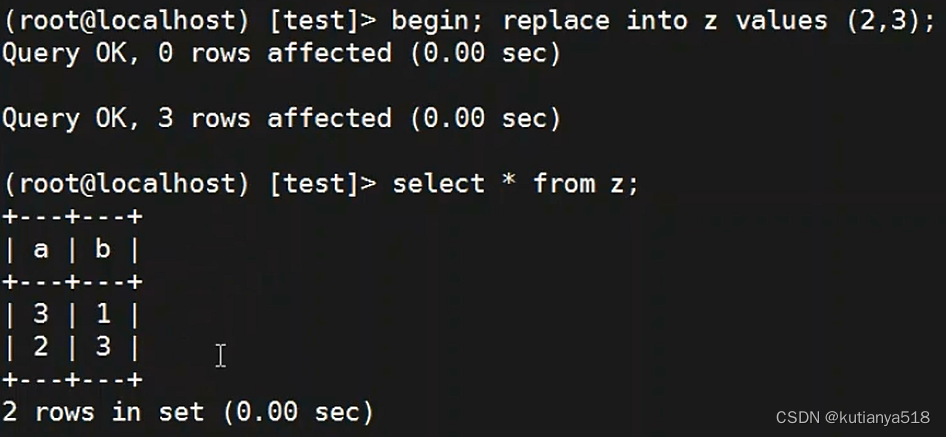
5、replace into:遇到主键或唯一索引,先删除再插入
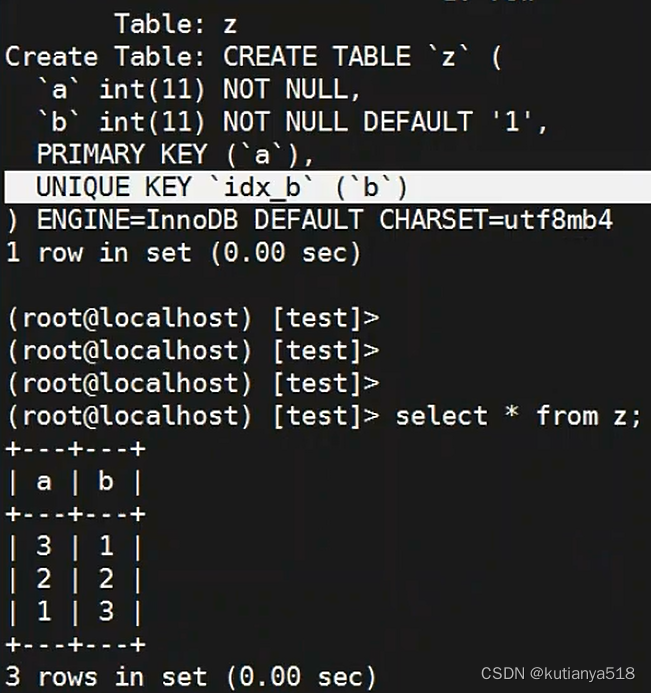
replace操作--会将所有重复的数据先删除,再执行insert:遇见主键2,则先删除主键为2的那条,然后又发现唯一为3的那条,则再删除,最后插入(2,3)
五、存储过程:
存储过程:存储在数据库端的一组SQL语句集
触发器:触发器是一种特殊存储过程,在定义触发器时会定义触发器的触发条件,使得触发器在满足触发条件时自动执行而不需要认为调用,如在insert时根据某个字段的值,触发修改其他字段的值
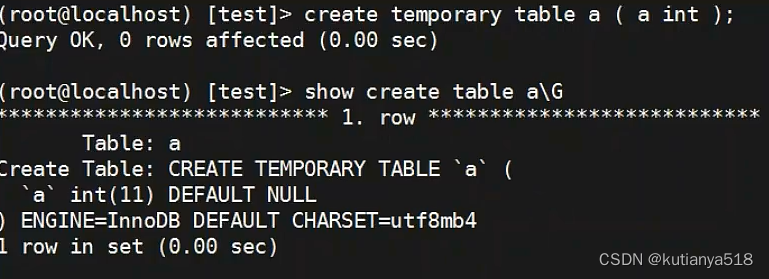
1、临时表:当前会话创建的一种临时表,持久化在磁盘上,随着会话的结束而结束,mysql的启动而删除,通过show tables 是不能查询到临时表的。在mysql5.7中,表数据存储在ibtmp1文件中,表结构是定义在tmp下的frm文件中
2、Event事件:定时器--mysql默认是关闭的
定时任务可配合存储过程做一些事情:
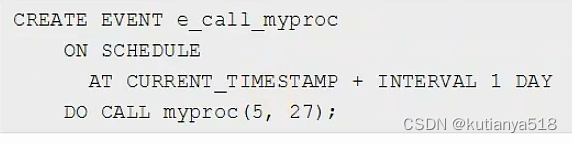
六、B+Tree索引
B+Tree定义:基于块存储,一组由根节点和叶子节点,有序的索引记录,叶子节点存储记录,非叶子节点存储索引列和主键值,一般B+tree高度3到4层,主键8字节可存储500亿左右数据,每叶大小16k。
索引的作用:第一快速的定位数据,第二快读的从排过序的数据中取数据
索引组织表:在innodb存放索引及指针(6字节)
堆表:存放着无序的数据,索引组织表指针指着数据

回表:是指查询二级索引时,找到主键,再根据主键查数据,而叶子索引不需要查询回表,直接根据指针找到存放数据的堆表
EXPLAIN:查看是否使用了索引,一般情况下通过慢查询日志,通过explain分析,进而去增加索引
1、创建索引:默认5分钟内不会锁表,查询和插入都不会受到影响,但是当online_alter的时候,会将数据存在log中,log有个上限就是这个参数;如果alter花费了很久,而在这段时间内的数据变更超过128M(默认),那么就会失败,故需要调大
innodb_online_alter_log_max_size=512M
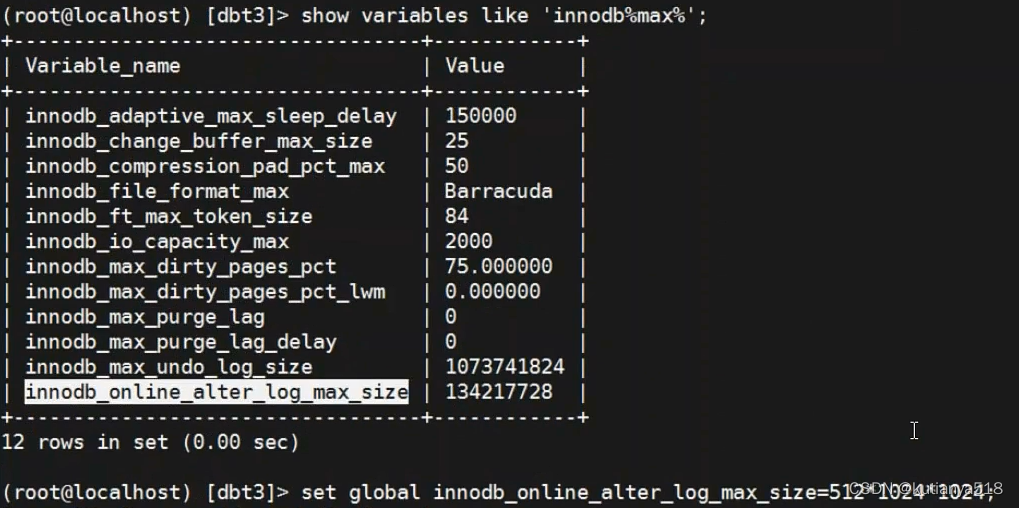
2、 150W条数据添加索引耗时:4s(根据不同服务器资源配置稍有变化)

3、80%的mysql调优可通过查看慢日志进行排查
慢日志查看:
 格式化查看慢日志:mysqldumpslow slow.log ,但是往往生产环境下slow.log非常大,可通过
格式化查看慢日志:mysqldumpslow slow.log ,但是往往生产环境下slow.log非常大,可通过
tail -fn10000 slow -> fenxi.log 先过滤出最新的慢日志,然后再通过mysqldumpslow查看
mysqldumpslow fenxi.log
通过慢日志重命名,新生成slow.log:
mv slow.log slow.log.20220717
flush slow logs //在mysql中执行命令,刷新生成新的慢日志文件slow.log
4、sys库:mysql统计分析的视图库
mysql5.7 通过sys库查看sql执行状况:如慢sql、全表扫描的sql
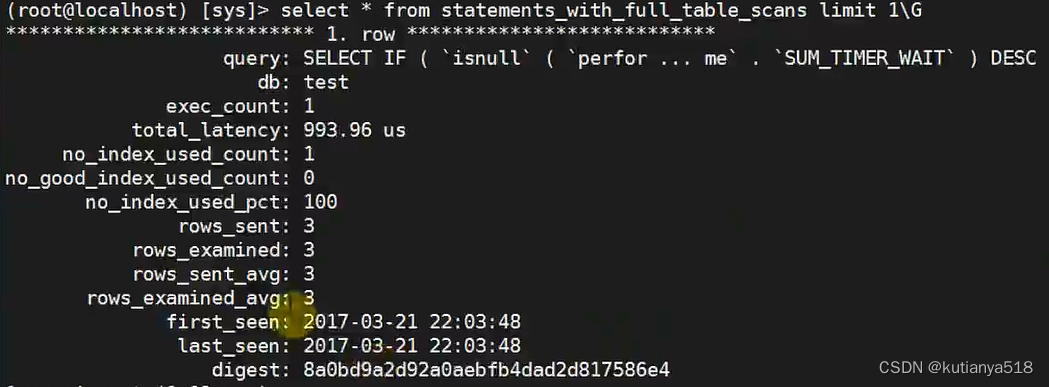
statement_analysis慢sql表:
是一个视图,数据是按照sql执行的时间倒叙排列的
select * from statement_analysis limit 100;
statements_with_full_table_scan全表扫描sql记录表:
schema_index_statistics表:查看某个库下某个表,增删改查索引使用情况
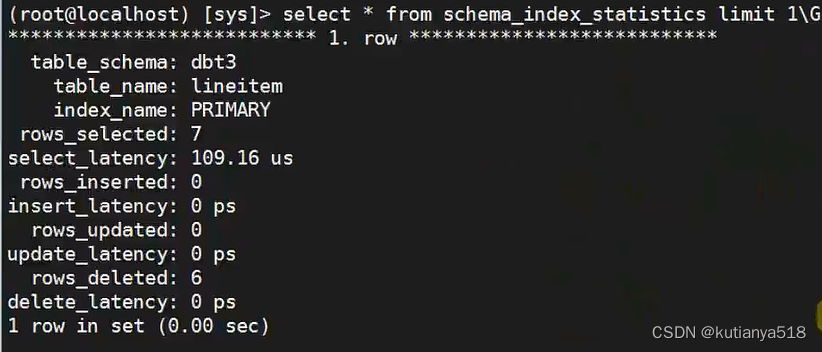
5、查看没有索引的表
select * from information_schema.STATISTICS;
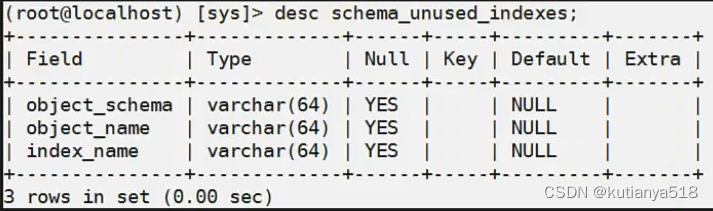
6、查询索引从来没被使用过的表
select * from sys.schema_unused_indexes;在8.0版本可以设置不可用,使用时在设置可用
7、符合索引Compound Index
案例:根据用户姓名查询最近1000条下单信息
select * from item where user=laoli order by date_time
符合索引(user,date_time):如果只创建user,则会进行file_sort,因为date_time没建索引,故查到数据后,会再进行排序
复合索引:选择度高的放前面
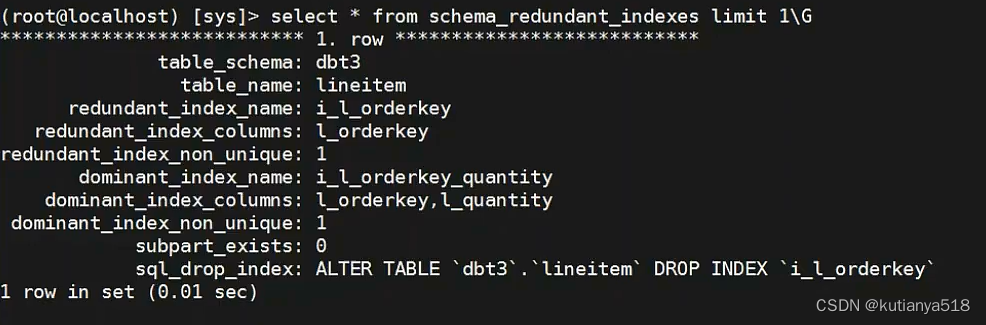
8、冗余索引:schema_redundant_indexes
通过查看这个冗余索引表,可以根据提示去除冗余索引
七、索引优化
1、Sql join 算法
左连接,左边为驱动表;右连接,右边为驱动表
以小结果集驱动大结果集:如果没有指定左右连接的情况下,MySQL优化器会以数据量小的表作为驱动表。
Join是通过两层for循环进行比较的,join_buffer_size能够缓存外层(小表驱动)要比较的列,故根据数据情况设置它的大小,通常配置1G即可,默认是256k。join_buffer_size是会话级别得,有几个线程对应会占用几个join_buffer_size内存。
注意:join_buffer_size在两张关联得表中,如果关联的列没有创建索引是有效果的,反之是无效的。
2、Explain

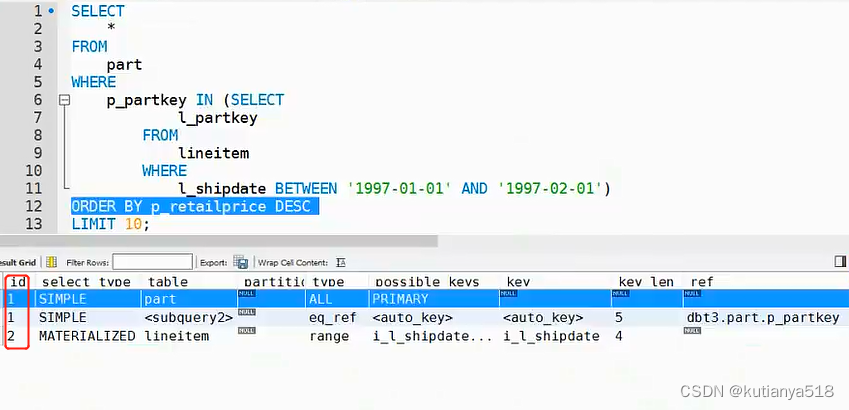
2.1 json格式的执行计划:format=json,这种情况的查看一般只在workbench中查看执行计划视图使用。
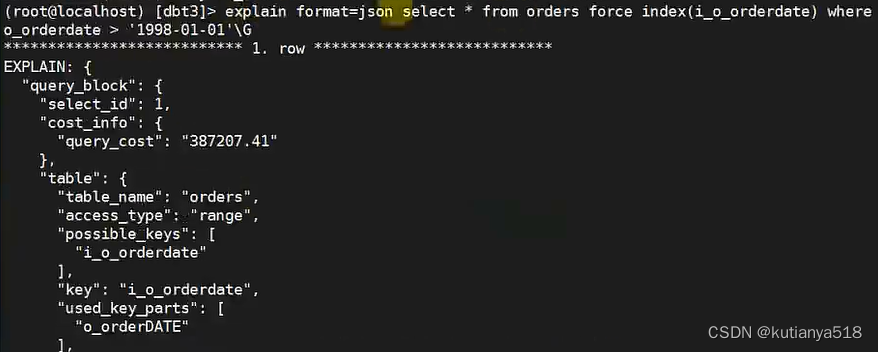
2.2 对于执行计划的id标志,查看的规则是:不同id从下往上看,相同id从上往下看,此规则可满足80%的执行计划场景的解读。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









