




案例:获取快手短视频
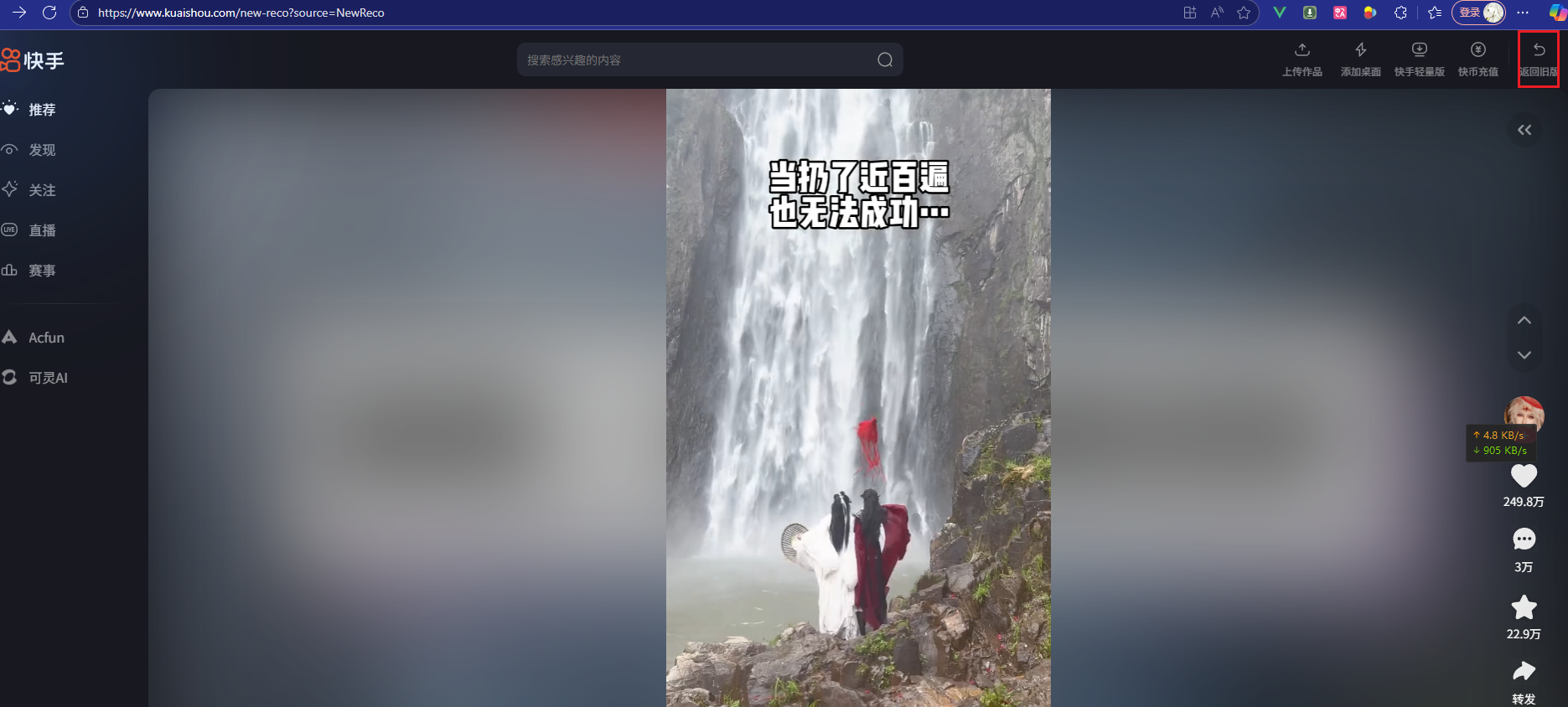
通过抓包发现这个graphql这个请求是获取视频数据的,里面的photoUrl属性是视频链接
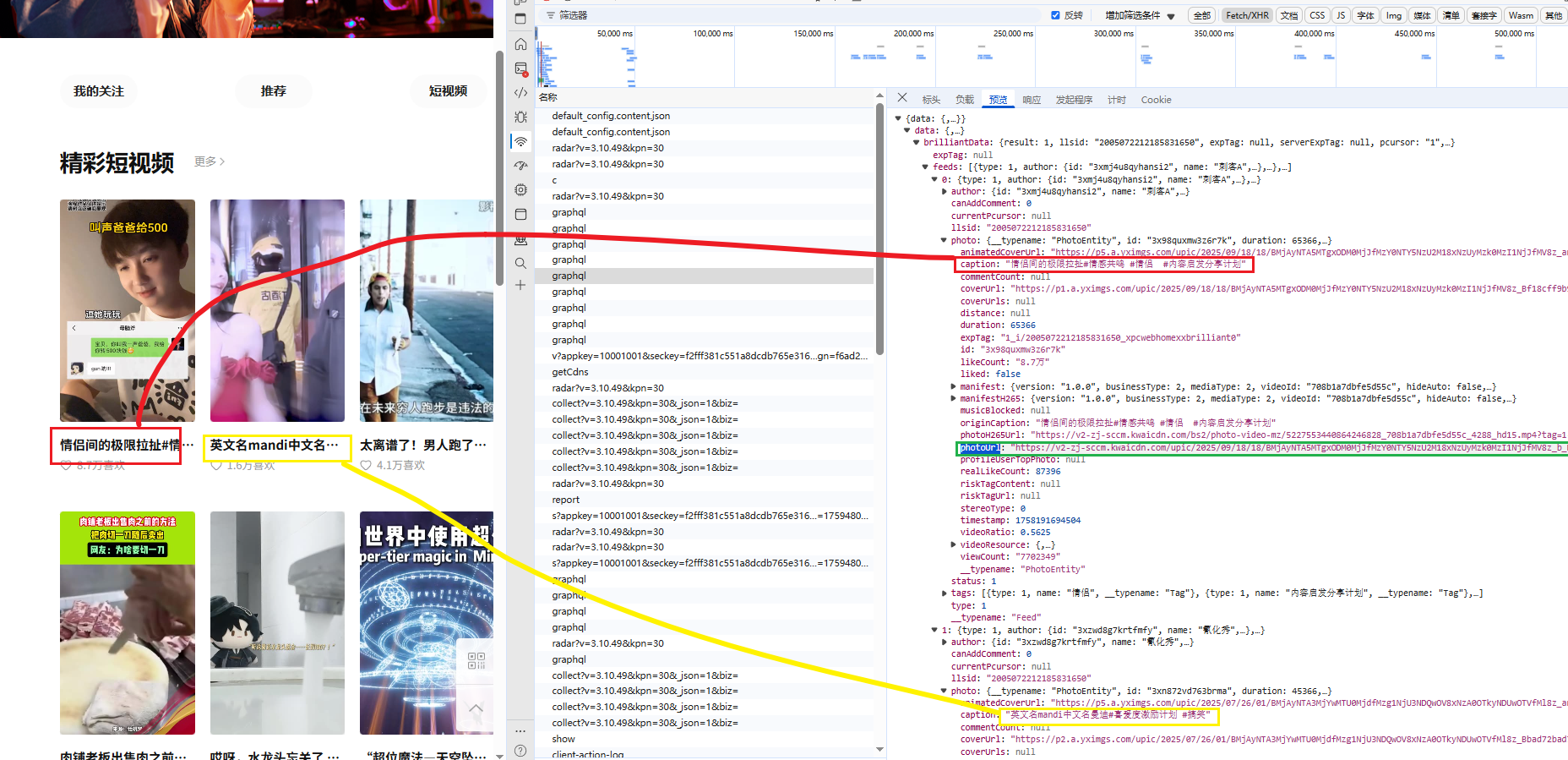
模拟请求发送数据
# 模拟请求获取视频数据
session = HTMLSession()
url='https://www.kuaishou.com/graphql'
headers={
# "Cookie": (
# "kpf=PC_WEB; " # "clientid=3; " # "did=web_adf8f55aca9899725e4134fdae902db2; " # "kwpsecproductname=kuaishou-vision; " # "kwpsecproductname=kuaishou-vision; " # "userId=5037453797; " # "kuaishou.server.webday7_st=ChprdWFpc2hvdS5zZXJ2ZXIud2ViZGF5Ny5zdBKwAYDMPBgiZ8CL921xlkyKSru2pb2HbZI4TI7bgVmf6INfxqPEoCIxNxUM7z5U5ods05EtLNi50gxkv7C6gWCAFBICnZZWqiHPIiMqeNc5XU03EtDlStqSkNS3zacBQ2fe9FPWR_7YTso8q3nCum3OQ3sg10D1GkEC9p5lVCzrZOFh7ljPM5XSmfnoJOMqyAJfzmGC9KCvehTr5F4-5aW2YGl6NoUVQcCCwVrqjwndWXp0GhKFbZIQPBqwmm2qxNndD6tYkp4iIFu-uMGWKUHAihmngqwkaUxdb1hnx_iAWM6dVwiNP_yOKAUwAQ; " # "kuaishou.server.webday7_ph=312d8d68643404293bc58dada21fe3e3d134; " # "ktrace-context=1|MS43NjQ1ODM2OTgyODY2OTgyLjE3NTg5OTY4LjE3NTk0NTcxNTkzODEuMzMzNTc4|MS43NjQ1ODM2OTgyODY2OTgyLjY1NTU3NDg5LjE3NTk0NTcxNTkzODEuMzMzNTc5|0|graphql-server|webservice|false|NA; " # "kwfv1=PnGU+9+Y8008S+nH0U+0mjPf8fP08f+98f+nLlwnrIP9+Sw/ZFGfzY+eGlGf+f+e4SGfbYP0QfGnLFwBLU80mYGAcF+ePA+/mY+Abf+9HUP/cIweZAG9P78fHEPAbS+Aql8BPh+nrhP9rl80SfPAGh8fPA8fQj+/4Y+/PhG/LEPfLEweGI+0GM8/Z9+9zD+0pYP/W7G9LUG9rFP0pjG/ZUwc==; " # "kwssectoken=inOczKT9X8dZx0RWsSqGcz46Afq+HubvhY0WEWcpTWhCj3nqSUKnIdfWDVxHlR1LvHbWK03b+9cUVE4E8RnJhQ==; " # "kwscode=47ab2e018ffd9a5082f18bdb7573fdbd8685d52802237835ce948df0fea3c848; " # "kpn=KUAISHOU_VISION" # ), # "Origin": "https://www.kuaishou.com", # "Referer": "https://www.kuaishou.com/brilliant", "User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/140.0.0.0 Safari/537.36 " "Edg/140.0.0.0" )
}
data={
"operationName": "brilliantTypeDataQuery",
"query": "fragment photoContent on PhotoEntity {\n __typename\n id\n duration\n caption\n originCaption\n likeCount\n viewCount\n commentCount\n realLikeCount\n coverUrl\n photoUrl\n photoH265Url\n manifest\n manifestH265\n videoResource\n coverUrls {\n url\n __typename\n }\n timestamp\n expTag\n animatedCoverUrl\n distance\n videoRatio\n liked\n stereoType\n profileUserTopPhoto\n musicBlocked\n riskTagContent\n riskTagUrl\n}\n\nfragment recoPhotoFragment on recoPhotoEntity {\n __typename\n id\n duration\n caption\n originCaption\n likeCount\n viewCount\n commentCount\n realLikeCount\n coverUrl\n photoUrl\n photoH265Url\n manifest\n manifestH265\n videoResource\n coverUrls {\n url\n __typename\n }\n timestamp\n expTag\n animatedCoverUrl\n distance\n videoRatio\n liked\n stereoType\n profileUserTopPhoto\n musicBlocked\n riskTagContent\n riskTagUrl\n}\n\nfragment feedContent on Feed {\n type\n author {\n id\n name\n headerUrl\n following\n headerUrls {\n url\n __typename\n }\n __typename\n }\n photo {\n ...photoContent\n ...recoPhotoFragment\n __typename\n }\n canAddComment\n llsid\n status\n currentPcursor\n tags {\n type\n name\n __typename\n }\n __typename\n}\n\nfragment photoResult on PhotoResult {\n result\n llsid\n expTag\n serverExpTag\n pcursor\n feeds {\n ...feedContent\n __typename\n }\n webPageArea\n __typename\n}\n\nquery brilliantTypeDataQuery($pcursor: String, $hotChannelId: String, $page: String, $webPageArea: String) {\n brilliantTypeData(pcursor: $pcursor, hotChannelId: $hotChannelId, page: $page, webPageArea: $webPageArea) {\n ...photoResult\n __typename\n }\n}\n",
"variables": {
"hotChannelId": "00",
"page": "brilliant",
# "pcursor": "1"
}
}
response=session.post(url,headers=headers,json=data)
print(response.json())
根据响应数据,获取指定视频url提取出来并下载视频到指定文件夹
if response.status_code == 200:
if not os.path.exists(ks_path):
os.mkdir(ks_path)
# print(response.json())
list = response.json()['data']['brilliantTypeData']['feeds']
for item in list:
# print(item)
video_name = item['photo']['caption'].split('#')[0]
# 去掉特殊字符
video_name = re.sub(r'[\\/:*?"<>|\r\n]', '', video_name)
if video_name == '':
# 随机名
video_name = item['photo']['caption'].split('#')[1]+'_'+str(uuid.uuid4())
# print("视频名称为空,随机生成:", video_name,item['photo']['caption'])
video_url = item['photo']['photoUrl']
# print(video_name,video_url)
video_response = requests.get(url=video_url)
if video_response.status_code == 200:
# print(video_response.content)
video_path = os.path.join(ks_path, video_name + '.mp4')
try:
with open(video_path, 'wb') as f:
f.write(video_response.content)
print(f"视频下载成功{tmp_num}:", video_name)
except OSError as e:
print("保存文件夹有问题:", e)
except Exception as e:
print("视频保存失败:", e)
else:
print("获取视频失败:", video_url)
else:
print("获取请求失败", response.status_code)
请求效果
完整代码
import os.path
import re
import uuid
import requests
from requests_html import HTMLSession
if __name__=='__main__':
# 模拟请求获取视频数据
session = HTMLSession()
url='https://www.kuaishou.com/graphql'
headers={
# "Cookie": (
# "kpf=PC_WEB; " # "clientid=3; " # "did=web_adf8f55aca9899725e4134fdae902db2; " # "kwpsecproductname=kuaishou-vision; " # "kwpsecproductname=kuaishou-vision; " # "userId=5037453797; " # "kuaishou.server.webday7_st=ChprdWFpc2hvdS5zZXJ2ZXIud2ViZGF5Ny5zdBKwAYDMPBgiZ8CL921xlkyKSru2pb2HbZI4TI7bgVmf6INfxqPEoCIxNxUM7z5U5ods05EtLNi50gxkv7C6gWCAFBICnZZWqiHPIiMqeNc5XU03EtDlStqSkNS3zacBQ2fe9FPWR_7YTso8q3nCum3OQ3sg10D1GkEC9p5lVCzrZOFh7ljPM5XSmfnoJOMqyAJfzmGC9KCvehTr5F4-5aW2YGl6NoUVQcCCwVrqjwndWXp0GhKFbZIQPBqwmm2qxNndD6tYkp4iIFu-uMGWKUHAihmngqwkaUxdb1hnx_iAWM6dVwiNP_yOKAUwAQ; " # "kuaishou.server.webday7_ph=312d8d68643404293bc58dada21fe3e3d134; " # "ktrace-context=1|MS43NjQ1ODM2OTgyODY2OTgyLjE3NTg5OTY4LjE3NTk0NTcxNTkzODEuMzMzNTc4|MS43NjQ1ODM2OTgyODY2OTgyLjY1NTU3NDg5LjE3NTk0NTcxNTkzODEuMzMzNTc5|0|graphql-server|webservice|false|NA; " # "kwfv1=PnGU+9+Y8008S+nH0U+0mjPf8fP08f+98f+nLlwnrIP9+Sw/ZFGfzY+eGlGf+f+e4SGfbYP0QfGnLFwBLU80mYGAcF+ePA+/mY+Abf+9HUP/cIweZAG9P78fHEPAbS+Aql8BPh+nrhP9rl80SfPAGh8fPA8fQj+/4Y+/PhG/LEPfLEweGI+0GM8/Z9+9zD+0pYP/W7G9LUG9rFP0pjG/ZUwc==; " # "kwssectoken=inOczKT9X8dZx0RWsSqGcz46Afq+HubvhY0WEWcpTWhCj3nqSUKnIdfWDVxHlR1LvHbWK03b+9cUVE4E8RnJhQ==; " # "kwscode=47ab2e018ffd9a5082f18bdb7573fdbd8685d52802237835ce948df0fea3c848; " # "kpn=KUAISHOU_VISION" # ), # "Origin": "https://www.kuaishou.com", # "Referer": "https://www.kuaishou.com/brilliant", "User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) " "Chrome/140.0.0.0 Safari/537.36 " "Edg/140.0.0.0" )
}
data={
"operationName": "brilliantTypeDataQuery",
"query": "fragment photoContent on PhotoEntity {\n __typename\n id\n duration\n caption\n originCaption\n likeCount\n viewCount\n commentCount\n realLikeCount\n coverUrl\n photoUrl\n photoH265Url\n manifest\n manifestH265\n videoResource\n coverUrls {\n url\n __typename\n }\n timestamp\n expTag\n animatedCoverUrl\n distance\n videoRatio\n liked\n stereoType\n profileUserTopPhoto\n musicBlocked\n riskTagContent\n riskTagUrl\n}\n\nfragment recoPhotoFragment on recoPhotoEntity {\n __typename\n id\n duration\n caption\n originCaption\n likeCount\n viewCount\n commentCount\n realLikeCount\n coverUrl\n photoUrl\n photoH265Url\n manifest\n manifestH265\n videoResource\n coverUrls {\n url\n __typename\n }\n timestamp\n expTag\n animatedCoverUrl\n distance\n videoRatio\n liked\n stereoType\n profileUserTopPhoto\n musicBlocked\n riskTagContent\n riskTagUrl\n}\n\nfragment feedContent on Feed {\n type\n author {\n id\n name\n headerUrl\n following\n headerUrls {\n url\n __typename\n }\n __typename\n }\n photo {\n ...photoContent\n ...recoPhotoFragment\n __typename\n }\n canAddComment\n llsid\n status\n currentPcursor\n tags {\n type\n name\n __typename\n }\n __typename\n}\n\nfragment photoResult on PhotoResult {\n result\n llsid\n expTag\n serverExpTag\n pcursor\n feeds {\n ...feedContent\n __typename\n }\n webPageArea\n __typename\n}\n\nquery brilliantTypeDataQuery($pcursor: String, $hotChannelId: String, $page: String, $webPageArea: String) {\n brilliantTypeData(pcursor: $pcursor, hotChannelId: $hotChannelId, page: $page, webPageArea: $webPageArea) {\n ...photoResult\n __typename\n }\n}\n",
"variables": {
"hotChannelId": "00",
"page": "brilliant",
# "pcursor": "1"
}
}
response=session.post(url,headers=headers,json=data)
print(response.json())
ks_path='ks_vedio'
down_num=int(input("请输入下载数量:"))
tmp_num=0
while down_num!=tmp_num:
if response.status_code == 200:
if not os.path.exists(ks_path):
os.mkdir(ks_path)
# print(response.json())
list = response.json()['data']['brilliantTypeData']['feeds']
for item in list:
# print(item)
video_name = item['photo']['caption'].split('#')[0]
# 去掉特殊字符
video_name = re.sub(r'[\\/:*?"<>|\r\n]', '', video_name)
if video_name == '':
# 随机名
video_name = item['photo']['caption'].split('#')[1]+'_'+str(uuid.uuid4())
# print("视频名称为空,随机生成:", video_name,item['photo']['caption'])
video_url = item['photo']['photoUrl']
# print(video_name,video_url)
video_response = requests.get(url=video_url)
if video_response.status_code == 200:
# print(video_response.content)
video_path = os.path.join(ks_path, video_name + '.mp4')
try:
with open(video_path, 'wb') as f:
f.write(video_response.content)
if down_num == tmp_num:
print("下载完成")
break;
tmp_num+=1
print(f"视频下载成功{tmp_num}:", video_name)
except OSError as e:
print("保存文件夹有问题:", e)
except Exception as e:
print("视频保存失败:", e)
else:
print("获取视频失败:", video_url)
else:
print("获取请求失败", response.status_code)
知识点
json常用方法
| 方法 | 操作对象 | 功能 |
|---|---|---|
dumps | Python对象 → 字符串 | 序列化为 JSON 字符串 |
loads | 字符串 → Python对象 | 反序列化 JSON 字符串 |
dump | Python对象 → 文件 | 序列化并写入 JSON 文件 |
load | 文件 → Python对象 | 读取文件并反序列化 |
- 将字典数据转成字符串:dumps ( 添加indent参数美化输出 )
dict1={'name':'小明','age':20,'sex':'男'}
# ensure_ascii 默认为True,将中文转换成unicode编码
res=json.dumps(dict1,ensure_ascii=False)
print(res,type(res))
结果
{"name": "小明", "age": 20, "sex": "男"} <class 'str'>
- 字典字符串转成字典:loads
dict='{"name": "小明", "age": 20, "sex": "男"}'
res=json.loads(dict)
print(res,type(res))
结果
{'name': '小明', 'age': 20, 'sex': '男'} <class 'dict'>
- 字典数据写到文件:dump
dict={
"id": 1,
"name": "Tom",
"age": 20
}
with open('j.json','w',encoding='utf-8') as f :
json.dump(dict,f)
- 将存储在文件中的字典读取出来:load
with open('j.json','r',encoding='utf-8') as f:
res=json.load(f)
print(res,type(res))
结果
{'id': 1, 'name': 'Tom', 'age': 20} <class 'dict'>
jsonpath常用方法
提取键值(嵌套的也能提取)
dict = {
"k": {
"case1": 1,
"case2": 2,
"case3": 3
},
"user": {
"case1": "Tom",
"id2": "Alice"
}
}
name_path=jsonpath(dict,'$..case1')
print(name_path)
结果
[1, 'Tom']
注意:当提取的键值不存在时,返回的是Boolean类型False
在页面上三个查询
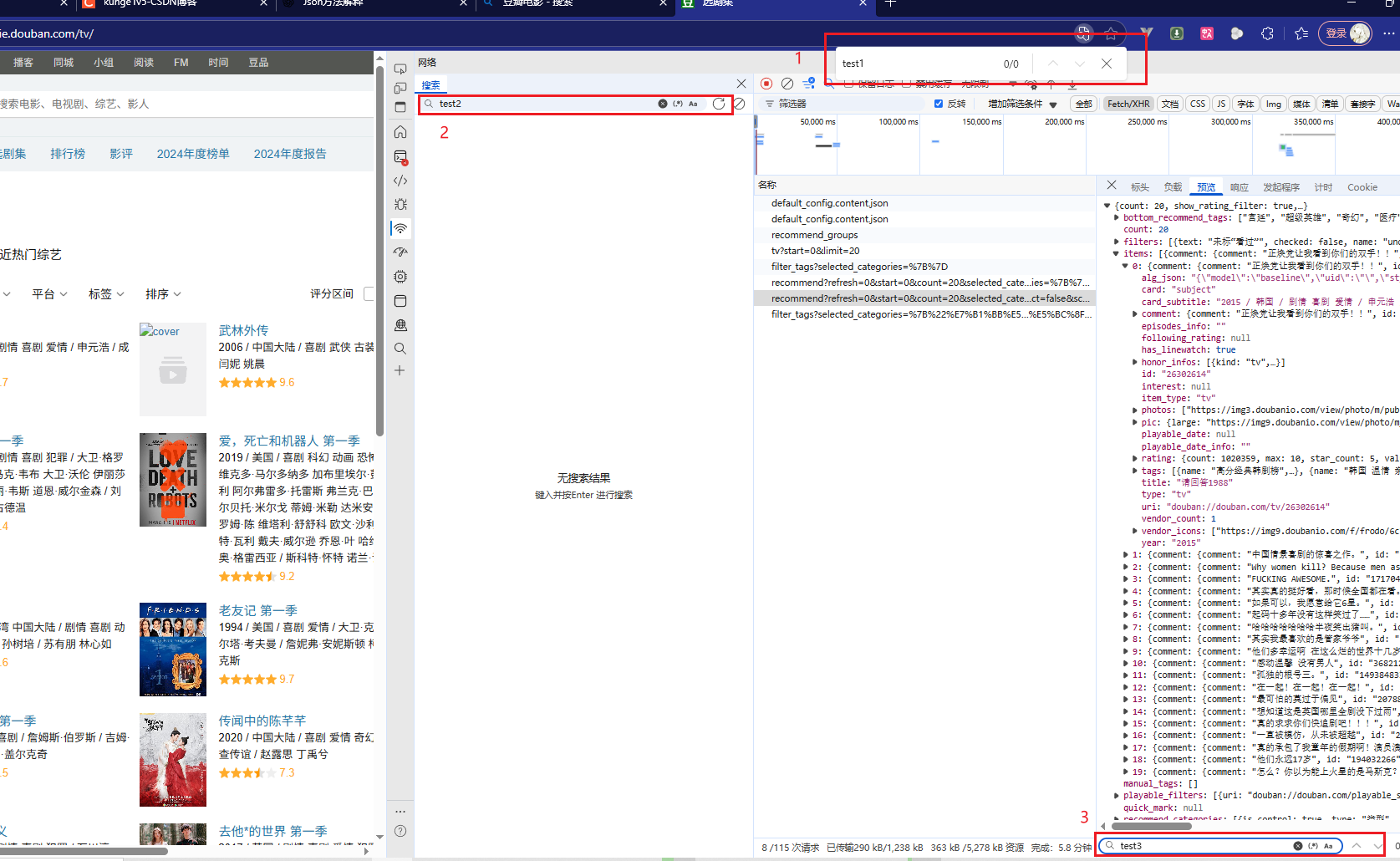
第一个:查询页面显示的数据
第二个:查询请求的url上的数据
第三个:可以查询“响应”和“预览”里的数据

如果在阅读中遇到任何疑问,欢迎在评论区留言或者私信我,我很乐意与你交流!📬

















 122
122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









