




yolo12手势识别项目
目的:了解做深度学习项目的流程
yolo官网
首先要了解深度学习是什么?
简单理解:从一堆输入数据中提取特征,然后根据这个特征进行识别处理输出
本文章讲述使用yolo12n模型识别图片+mediapipe识别手的21个关键点+xgboost分类器实现的
把项目代码下载下来看效果更好
第一步:准备数据集
你可以自己制造数据或者找网上的数据集,如Hugging Face上的免费模型和数据集
本项目我用的是hagRIDv2_512手势数据集,主要这个小一点才100G,我用的是一部分数据
使用task.py的方法二下载完整数据(不需要的可以直接用我项目中的)
# 方法二:从缓存的数据集读取数据
# 加载数据集 第一次会下载100G数据到本地
Handdata=DataSet()
imgs,labels=Handdata.get_dataset(show=False)
# # 保存到本地 # for i,img in enumerate(imgs):
# Handdata.save_image_with_label(frame=img,label=labels[i],save_dir="classifierSet")
hands_features=[]
# 识别手的21个关键点
for i,img in enumerate(imgs):
hands_feature = hand_detect(img, show=True, show_hand=True)
if hands_feature != []:
# 目前支持一个手
hands_features.append(hands_feature[0])
else:
hands_features.append([])
# 使用xgboost分类
train_classifier_complex(hands_features,labels,Handdata.lable_names,random_state=int(time.time()))
第一次把保存这里不注释把数据下载到本地,按文件夹分类,可以置每个类别固定张数,不然100w张保存不下来
# # 保存到本地
# for i,img in enumerate(imgs):
# Handdata.save_image_with_label(frame=img,label=labels[i],save_dir="classifierSet")
第二步:对数据集按比例分配,并数据标注
- 数据集分类
把数据集分成两个或者三份
两份的话是:训练集(80%)和测试集(20%)
三份的话是:训练集(60%)和验证集(20%)和测试集(20%),效果更好- 训练集是用来训练的数据特征
- 测试集是在训练时用正在训练的模型来识别没有训练的数据进行判别效果
- 验证集是用来验证训练的模型在实际效果如何
- 数据标注
我用的是别人制作的数据标识软件需要可以下载
意思:在图片上标注矩形框,然后收集标记矩形框的位置和类型
 如下图所示
如下图所示
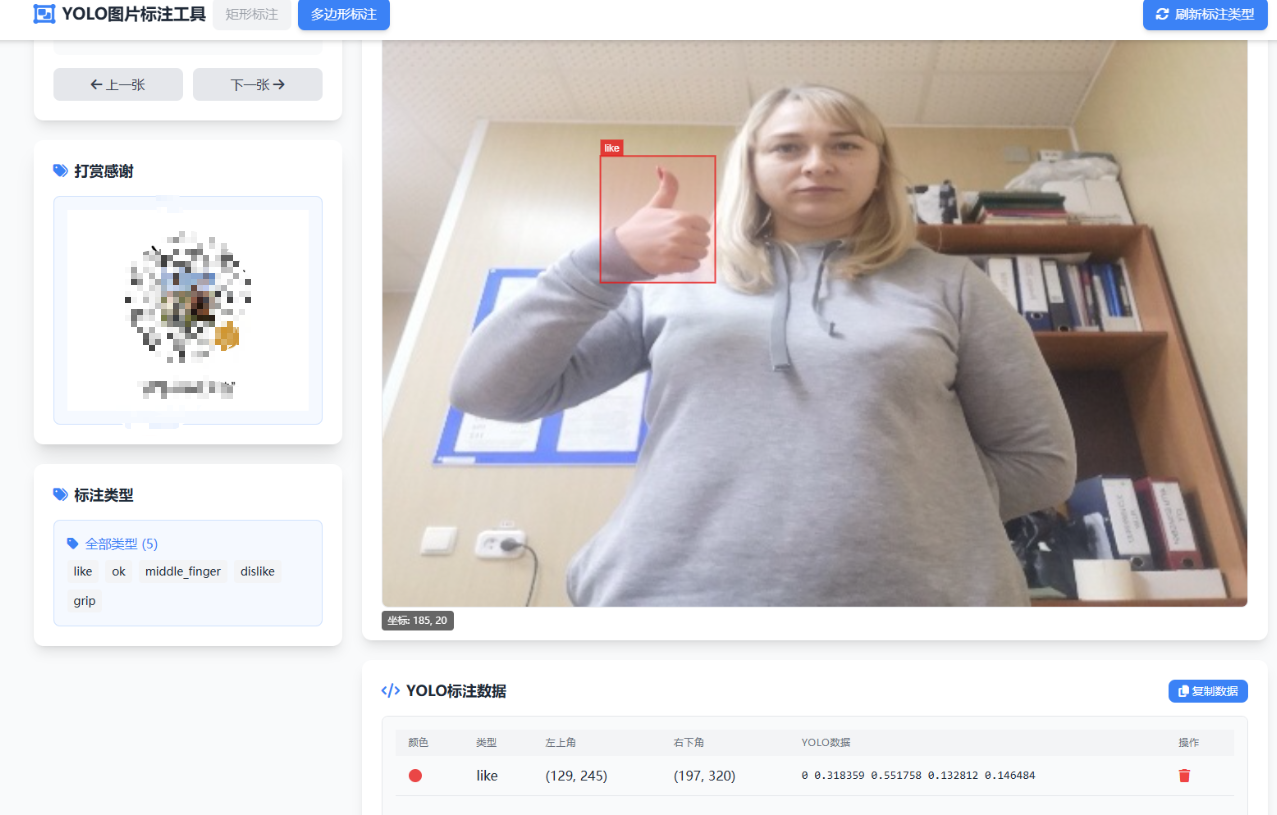
数据标注是个体力活,我这个可以使用模型进行标注,前提你需要先训练一点数据,然后让模型标注,最后自己把标错的纠正一下 - 把标注的数据放到yolo指定文件夹里
trainSet
├── images
│ ├─ train 训练集图片
│ └──val 验证集图片
└── labels
├── train 训练集标识数据(.txt)
└── val 验证集标识数据(.txt)
data.yaml数据配置
# 数据集根目录(改成当前trainSet的路径)
path: E:\hand\test\trainSet
# 训练集图片路径
train: images\train
# 验证集图片路径
val: images\val
# 类别数量
nc: 5
# 类别名称(在数据标注类型中的顺序要和这里相同)
names: ["like","ok","middle_finger","dislike","grip"]
第三步:训练yolo识别手势图像模型
在train.py文件中,把训练参数配置好,就可以训练了
# 训练模型配置
model.train(
data='data.yaml',# 数据集配置路径
epochs=100,# 训练次数
imgsz=512,# 输入图像大小
batch=16,# 训练批次大小
device='cpu',# GPU = 0 ,CPU ='cpu'
patience=10, # 早停机制,10 轮无提升则停止训练
workers=2, # 使用 2 个数据加载线程
lr0=0.001, # 初始学习率,例如 1e-3 lrf=0.01, # 最终 LR ≈ lr0 * lrf = 0.001 * 0.01 = 1e-5 warmup_epochs=3, # 热身阶段几轮
cos_lr=True # 启用余弦学习率调度
)
下图是一部分参数,详细参数看yolo官网训练参数
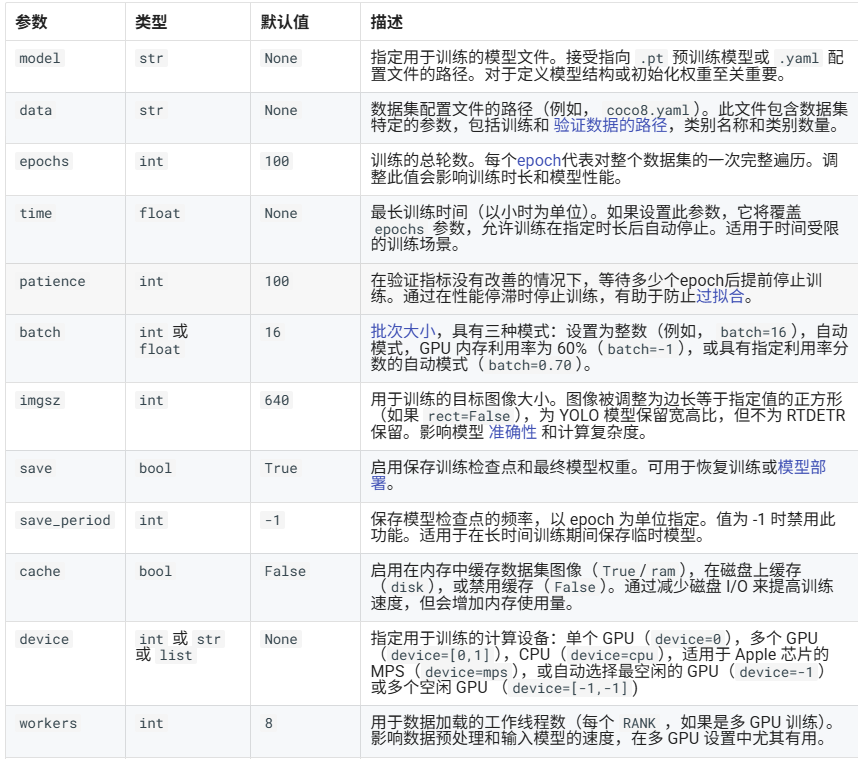
注意:训练模型既可以用 CPU,也可以用 GPU。
- GPU 训练:速度快,适合大规模数据集,但需要额外配置环境。
- CPU 训练:无需复杂配置,适合数据量较小的情况。
跑好的模型在runs目录下的train+最大值文件里
第四步:训练xgboost分类器
“XGBoost” 全称是 eXtreme Gradient Boosting,是一种流行的、效率很高的机器学习算法 / 库,常用于分类、回归、排序等监督学习任务。详细调优请看XGBoost 文档 ,也有XGBoost视频
运行task.py,跑方法一
# 方法一: 从本地读取数据
# 本地数据读取
hands_features, labels=process_files_in_directory(r"classifierSet",Typenum=85,label_names=["like","ok","middle_finger","dislike","grip"])
# 训练分类器
train_classifier_complex(hands_features, labels,label_names=["like","ok","middle_finger","dislike","grip"],n_trials=100,random_state=int(time.time()))
训练出来的分类器在classifierResult文件夹下hand_gesture_xgb_model_complex_+最大值
第五步:测试模型
在训练了yolo图像识别模型和xgboost分类模型后,选择yolo图像识别最好的模型和xgboost分类效率高的模型
在utils.py中跑下面代码
# 自己训练手势识别的模型 yolo11n识别类别 +mediapipe识别21个关键点 +xgb分类 支持 like 、dislike、 middle_finger、 ok、 grip五个手势
# camera_my_model(r'runs/detect/train/weights/best.pt',r'classifierResult/hand_gesture_xgb_model_complex_15.pkl',conf=0.6)
能正常识别手势播放相应的音乐,你可以优化模型让模型识别正确同时速度快(作者入门优化什么不会😅)
自己训练的的模型:camera_my_model()识别的手势(作者水平有限😅)

别人训练的模型:camera_use_model()识别的手势

训练文件含义解释
run(训练好之后的结果)
train(训练结果目录)
weight 权重目录
weights
├── best.pt # 训练过程中表现最好的模型,可直接用于推理或部署
└── last.pt # 最后一次保存的模型权重,用于中断后继续训练
args.yaml(训练模型配置的参数)
task: detect
mode: train
model: yolo12n.pt
data: data.yaml
epochs: 100
time: null
patience: 10
batch: 16
imgsz: 512
save: true
save_period: -1
cache: false
device: cpu
workers: 2
project: null
name: train
exist_ok: false
pretrained: true
optimizer: auto
verbose: true
seed: 0
deterministic: true
single_cls: false
rect: false
cos_lr: false
close_mosaic: 10
resume: false
amp: true
fraction: 1.0
profile: false
freeze: null
multi_scale: false
compile: false
overlap_mask: true
mask_ratio: 4
dropout: 0.0
val: true
split: val
save_json: false
conf: null
iou: 0.7
max_det: 300
half: false
dnn: false
plots: true
source: null
vid_stride: 1
stream_buffer: false
visualize: false
augment: false
agnostic_nms: false
classes: null
retina_masks: false
embed: null
show: false
save_frames: false
save_txt: false
save_conf: false
save_crop: false
show_labels: true
show_conf: true
show_boxes: true
line_width: null
format: torchscript
keras: false
optimize: false
int8: false
dynamic: false
simplify: true
opset: null
workspace: null
nms: false
lr0: 0.01
lrf: 0.01
momentum: 0.937
weight_decay: 0.0005
warmup_epochs: 3.0
warmup_momentum: 0.8
warmup_bias_lr: 0.1
box: 7.5
cls: 0.5
dfl: 1.5
pose: 12.0
kobj: 1.0
nbs: 64
hsv_h: 0.015
hsv_s: 0.7
hsv_v: 0.4
degrees: 0.0
translate: 0.1
scale: 0.5
shear: 0.0
perspective: 0.0
flipud: 0.0
fliplr: 0.5
bgr: 0.0
mosaic: 1.0
mixup: 0.0
cutmix: 0.0
copy_paste: 0.0
copy_paste_mode: flip
auto_augment: randaugment
erasing: 0.4
cfg: null
tracker: botsort.yaml
save_dir: E:\hand\test\runs\detect\train
curve(曲线)结尾的图片
置信度 (Confidence):模型单次预测的为该类型的概率
精度 (Precision):在所有 被模型预测为某类别 的样本中,有多少是真的。
召回率 (Recall ):在所有 真实属于某类别 的样本中,有多少被模型识别对的。
F1 是一种 综合指标,用来平衡 精度(Precision) 和 召回率(Recall)
F1 = (2 × Precision × Recall) / (Precision + Recall)
以下图中红色箭头为最佳路线
F1-Confidence Curve(F1-置信度曲线)
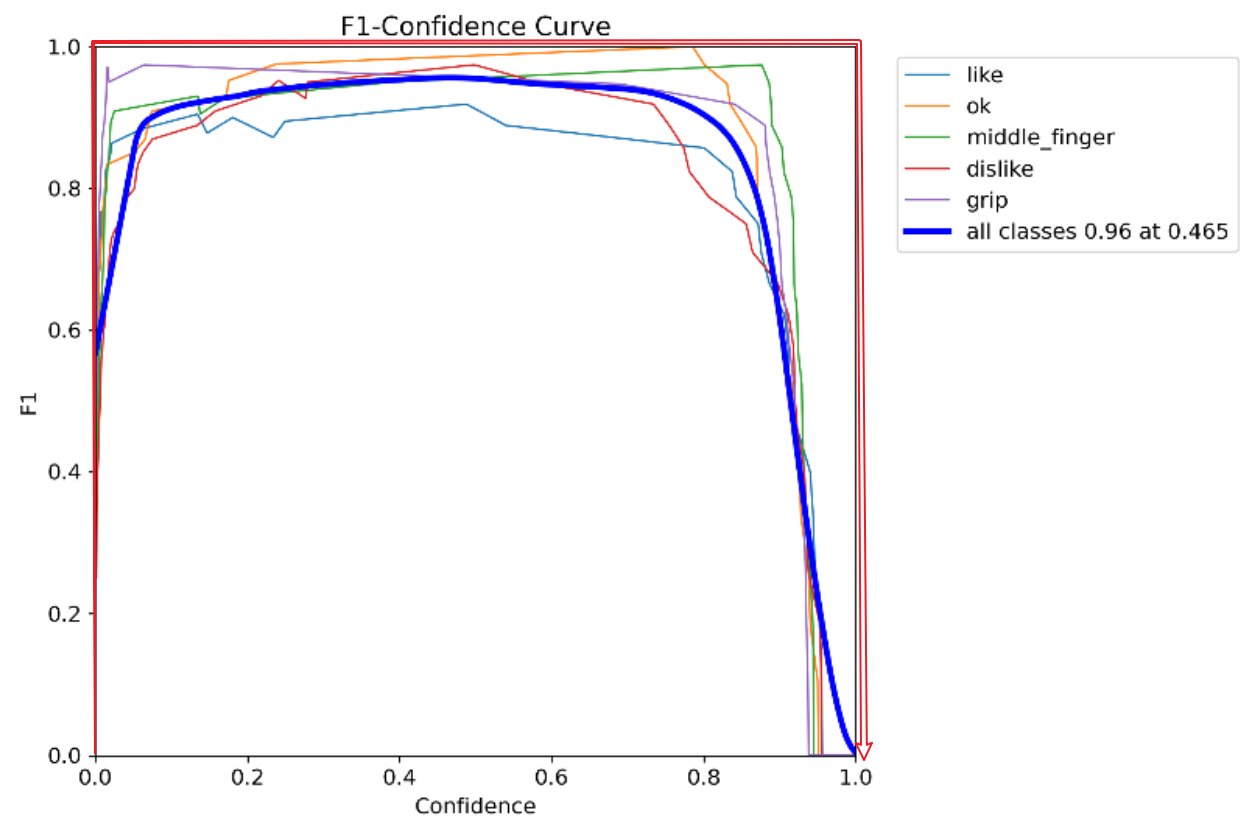
上述图:置信度为0.96时,F1综合指标为0.465最好
Precision-Confidence(精度-置信度曲线)
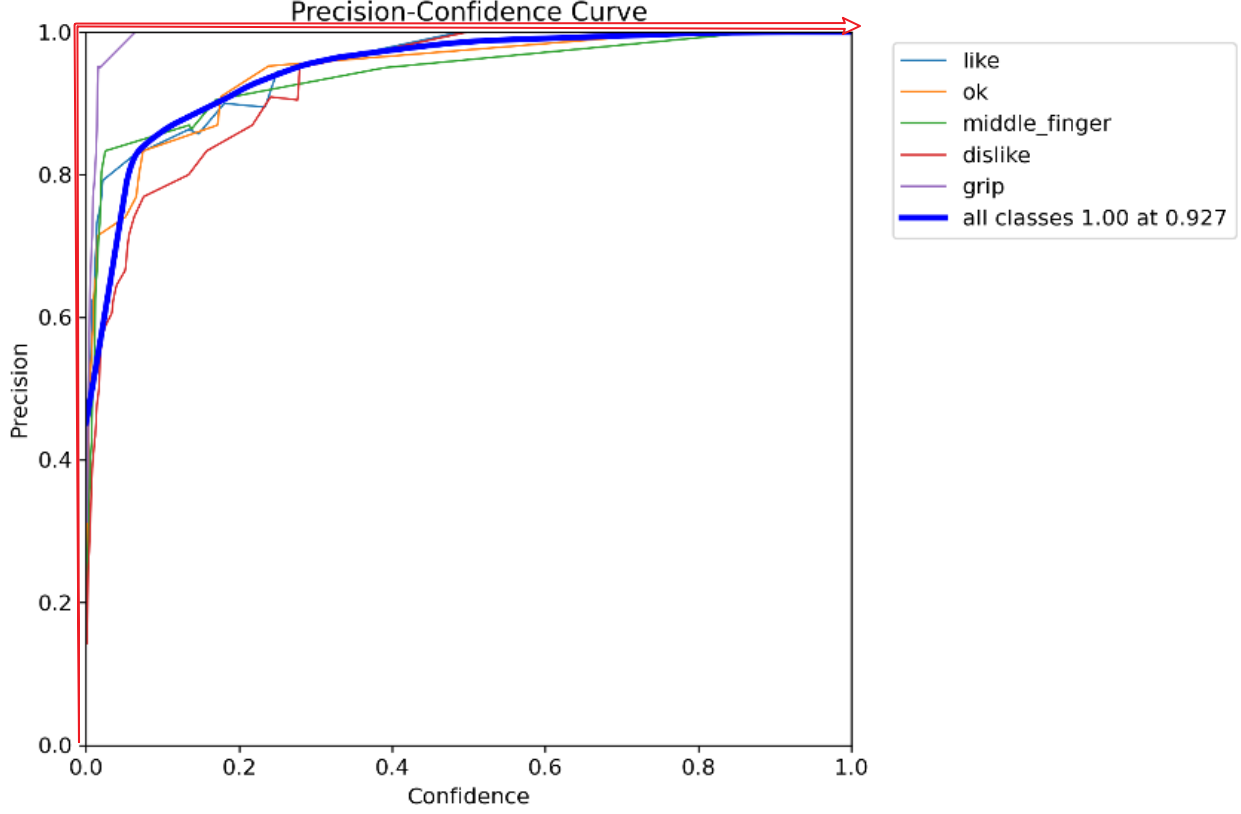
比如图中置信度在0.927时,识别所有类别其中一个都能识别对该类别
Precision–Recall 曲线(精度-召回曲线)
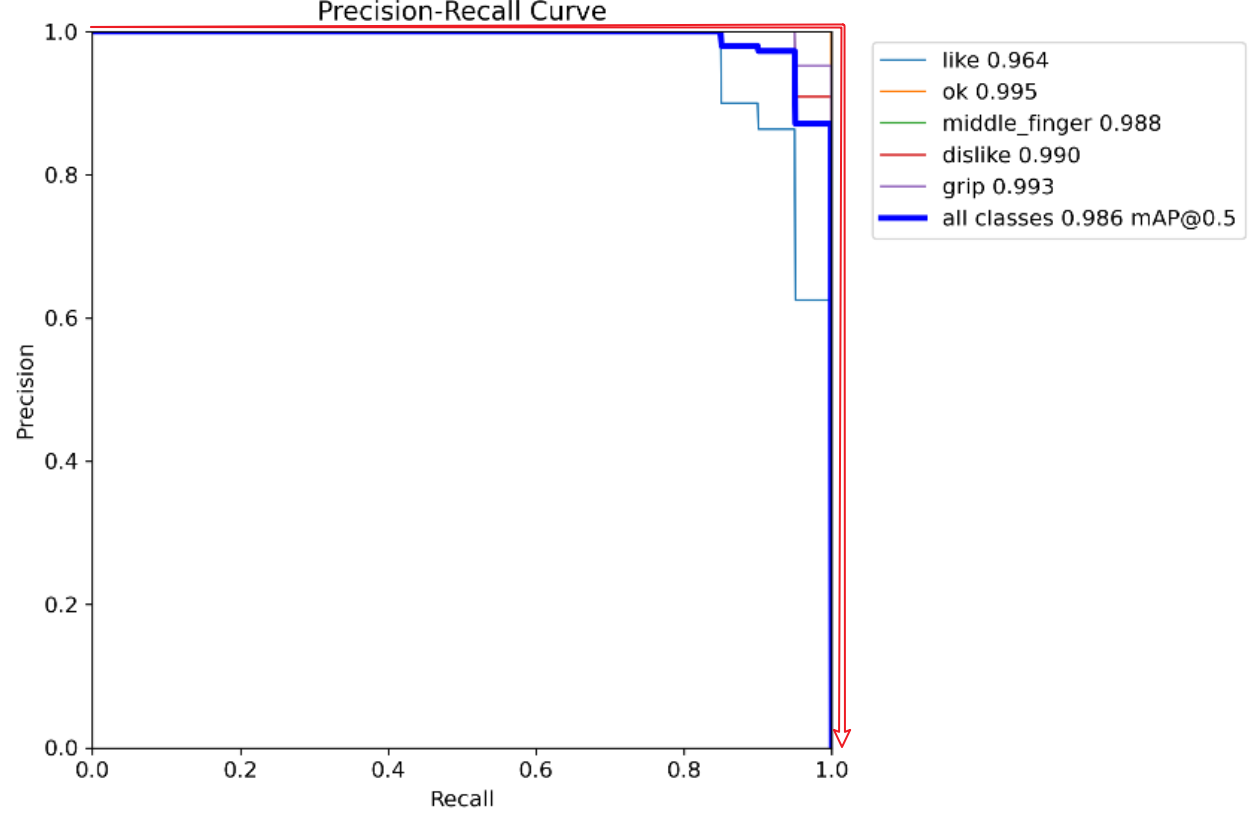
曲线越接近 右上角 (Recall=1, Precision=1),说明模型越好
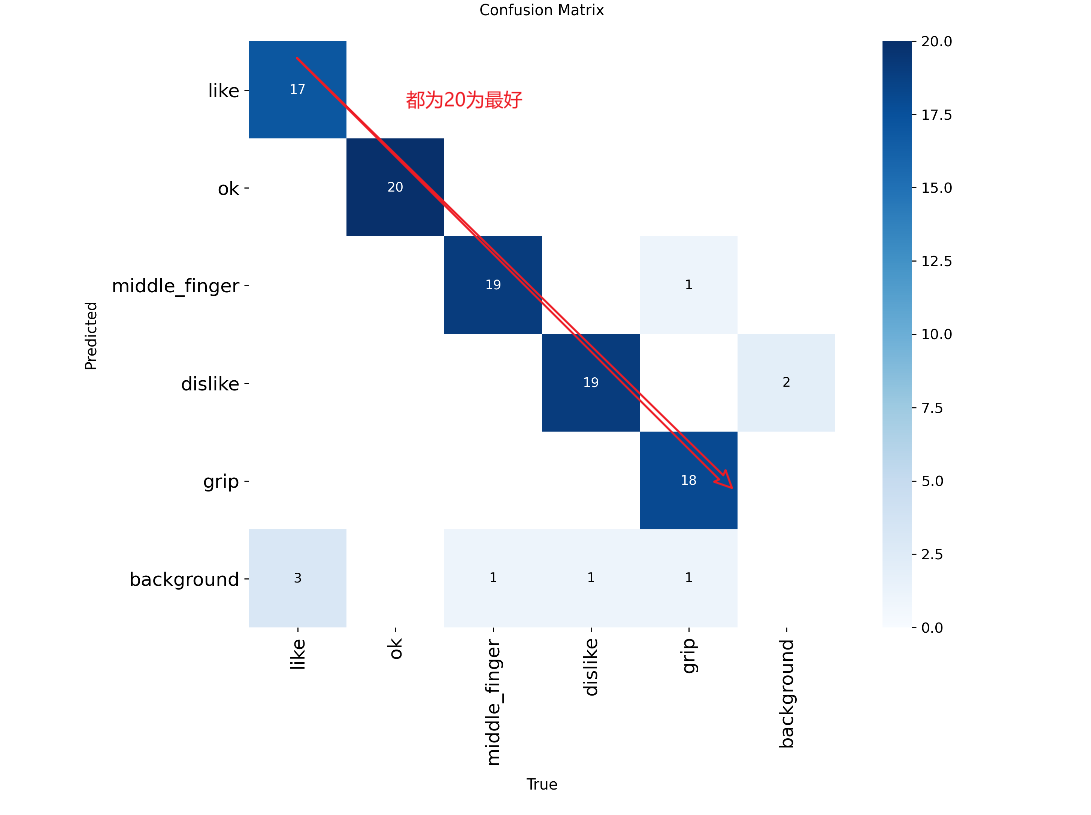
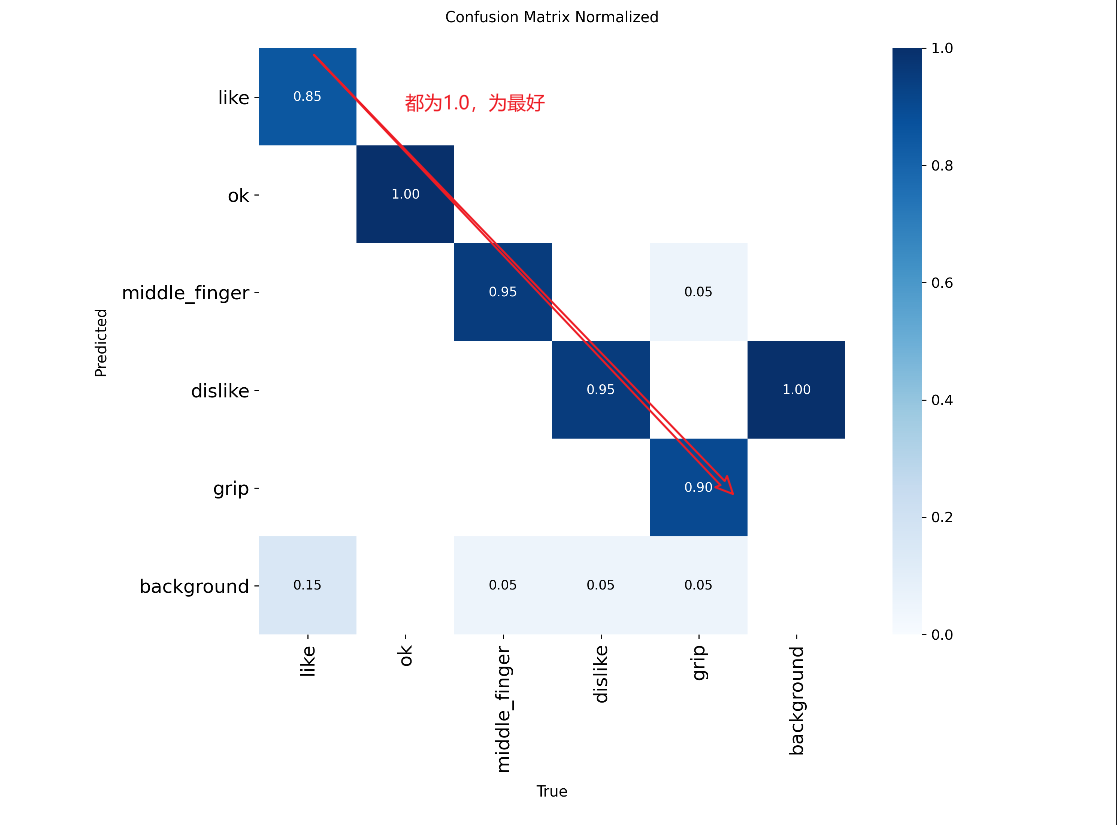
confusion_matrix(混淆矩阵)和confusion_matrix_normalized(归一化混淆矩阵)
confusion_matrix(混淆矩阵):预测类型成功和失败的数量,background是没有类别的数量
confusion_matrix_normalized(归一化混淆矩阵):预测类型识别的成功的概率,background是没有类别的数量
labels(类别)
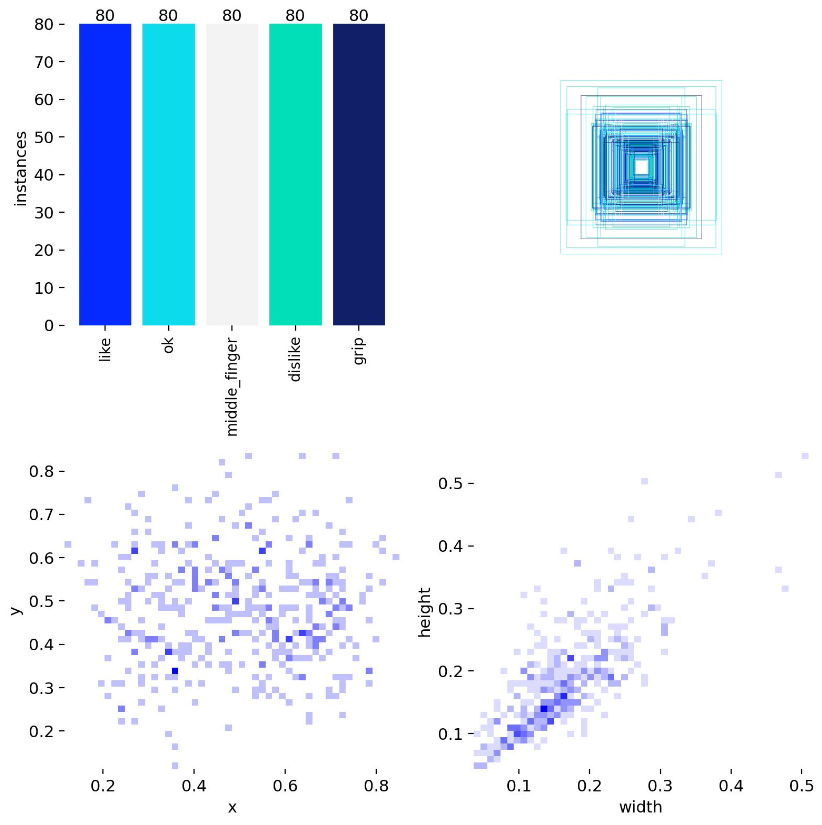
- 左上角是图片中识别到类型画框的数量,最佳是所有类型数量相同
- 左下角画框左上角/框的中心点位置的分布,最佳是所有地方都分布
- 右上角是所有画框的重叠起来的分布
- 右下角是画框的宽和高分布
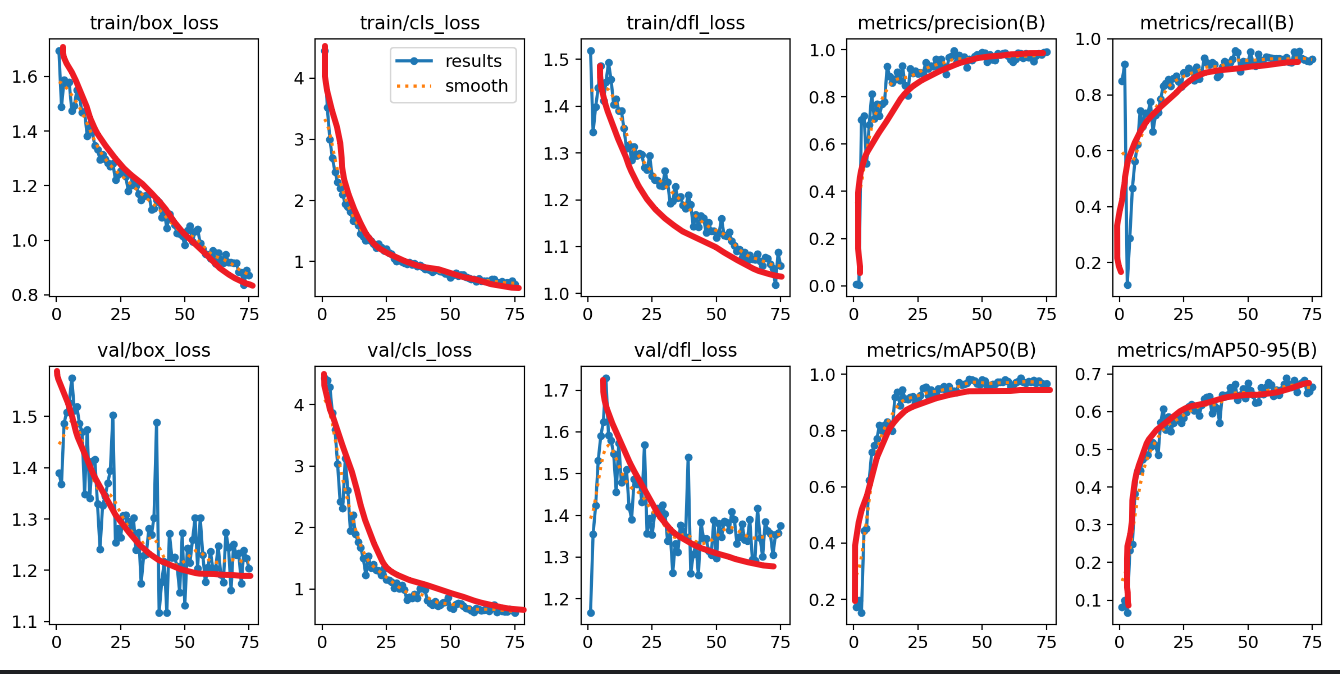
results(模型训练结果)
resultsd.csv (存储模型每轮训练的结果)
results.png (储模型每轮训练的图像走势)
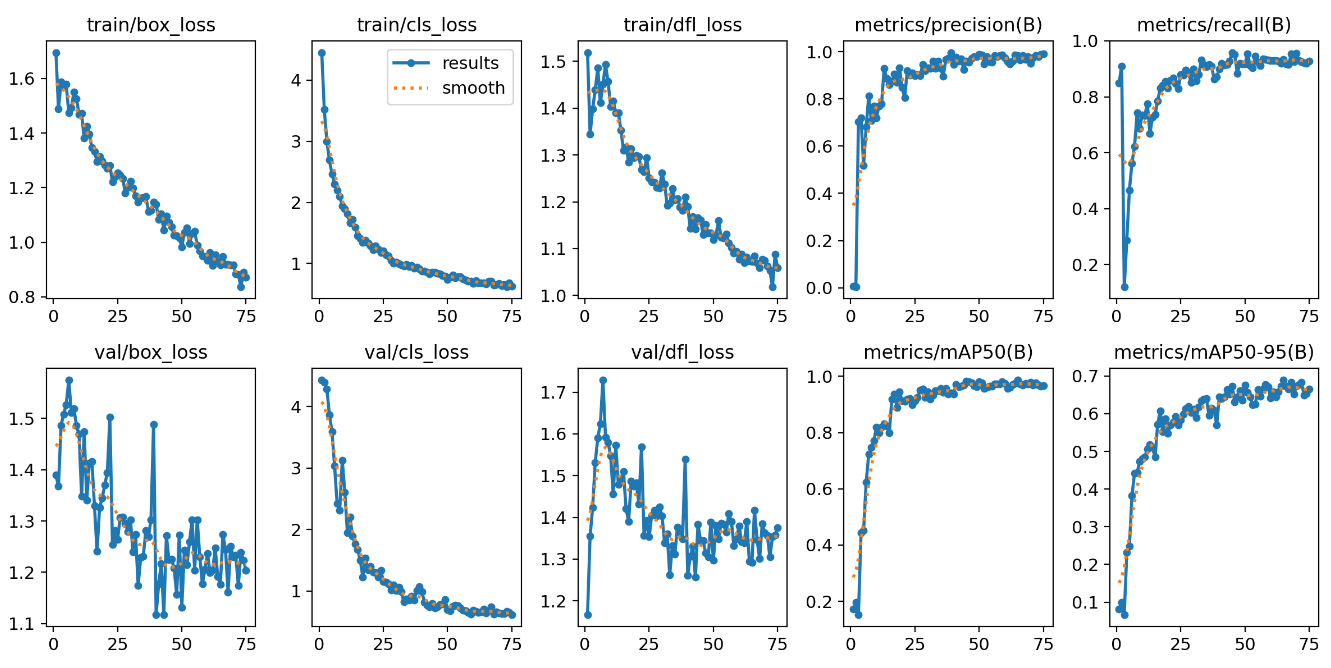
最佳效果(左边三列下降,右边两列上升)
train_batch+数字是训练集部分训练结果(类别用数字标识)
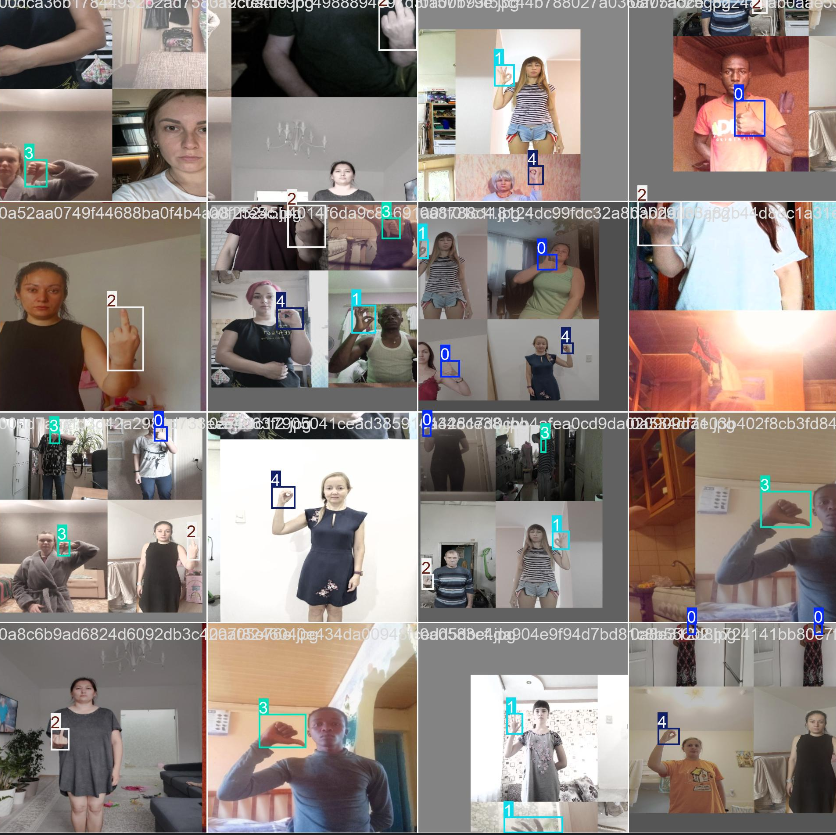
val_batch+数字的是验证集的部分结果
val_batch+数字+_LABELS

val_batch+数字+_PRED 类别标签+类别置信度


如果你在阅读过程中也有新的见解,或者遇到类似问题,🥰不妨留言分享你的经验,让大家一起学习。
喜欢本篇内容的朋友,记得点个 👍点赞,收藏 并 关注我,这样你就不会错过后续的更多实用技巧和深度干货了!
期待在评论区看到你的声音,我们一起成长、共同进步!😊


















 1618
1618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









