







 本文详细介绍了Java类加载机制,包括加载、验证、准备、解析、初始化等阶段,以及类加载器的双亲委派模型。此外还深入探讨了JVM运行时数据区和垃圾回收机制,包括各种引用类型、垃圾回收算法和常见的JVM配置。
本文详细介绍了Java类加载机制,包括加载、验证、准备、解析、初始化等阶段,以及类加载器的双亲委派模型。此外还深入探讨了JVM运行时数据区和垃圾回收机制,包括各种引用类型、垃圾回收算法和常见的JVM配置。
一、Java类加载机制
类从被加载到虚拟机内存中开始,到卸载出内存,它的整个生命周期包括:加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initiallization)、使用(Using)和卸载(Unloading)这7个阶段。其中验证、准备、解析3个部分统称为连接(Linking),这七个阶段的发生顺序如下图
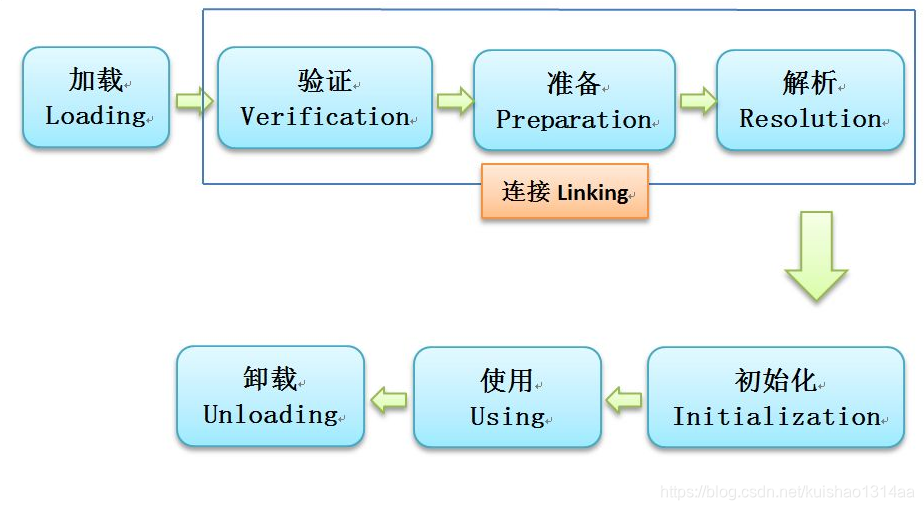
1.加载Loading:
1)通过一个类的全限定名来获取定义此类的二进制字节流。
2)将这个字节流所代表的静态变量、类信息、常量等内容放入到方法区。
3)在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问入口。
2.验证Verification:
目的是确保class文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身安全,
验证阶段主要包括四个检验过程:文件格式验证、元数据验证、字节码验证和符号引用验证
3.准备Preparation
静态成员的初始化。准备阶段是正式为类变量分配内存并设置其初始值的阶段,这些变量所使用的内存都将在方法区中分配。关于这点,有两个地方注意一下:
1)这时候进行内存分配的仅仅是类变量(被static修饰的变量),而不是实例变量,实例变量将会在对象实例化的时候随着对象一起分配在Java堆中
2)这个阶段赋初始值的变量指的是那些不被final修饰的static变量,比如"public static int value = 123;",value在准备阶段过后是0而不是123,给value赋值为123的动作将在初始化阶段才进行
4.解析Resolution
解析阶段是虚拟机常量池内的符号引用替换为直接引用的过程。 Java在编译阶段,会将.java文件编译成.class文件,在生成的.class文件中,static修饰的静态变量就是我们常说的符号引用,但是在编译阶段该符号引用并不知道引用类的实际内存地址(虚拟机还没运行)。直到解析阶段,虚拟机加载了该类才能真正解析到具体的内存地址。
5.初始化Initialization
初始化阶段做的事就是给static变量赋予用户指定的值以及执行静态代码块
二、双亲委派加载
1.类加载器介绍:
从Java开发人员的角度来看,大部分Java程序一般会使用到以下三种系统提供的类加载器:
1)启动类加载器(Bootstrap ClassLoader):负责加载JAVA_HOME\lib目录中并且能被虚拟机识别的类库到JVM内存中,如果名称不符合的类库即使放在lib目录中也不会被加载。该类加载器无法被Java程序直接引用。
2)扩展类加载器(Extension ClassLoader):该加载器主要是负责加载JAVA_HOME\lib\,该加载器可以被开发者直接使用。
3)应用程序类加载器(Application ClassLoader):该类加载器也称为系统类加载器,它负责加载用户类路径(Classpath)上所指定的类库,开发者可以直接使用该类加载器,如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
4)自定义类加载器(必须继承 ClassLoader)。
这些类加载器之间的关系如下图所示:
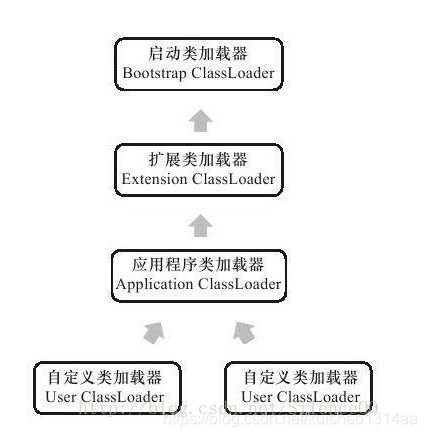
如上图所示的类加载器之间的这种层次关系,就称为类加载器的双亲委派模型(Parent Delegation Model)。该模型要求除了顶层的启动类加载器外,其余的类加载器都应当有自己的父类加载器。子类加载器和父类加载器不是以继承(Inheritance)的关系来实现,而是通过组合(Composition)关系来复用父加载器的代码。
2.双亲委派模型的工作过程为:
如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的加载器都是如此,因此所有的类加载请求都会传给顶层的启动类加载器,只有当父加载器反馈自己无法完成该加载请求(该加载器的搜索范围中没有找到对应的类)时,子加载器才会尝试自己去加载
3.双亲委派模型 的好处:
使用这种模型来组织类加载器之间的关系的好处是Java类随着它的类加载器一起具备了一种带有优先级的层次关系。例如java.lang.Object类,无论哪个类加载器去加载该类,最终都是由启动类加载器进行加载,因此Object类在程序的各种类加载器环境中都是同一个类。否则的话,如果不使用该模型的话,如果用户自定义一个java.lang.Object类且存放在classpath中,那么系统中将会出现多个Object类,应用程序也会变得很混乱。如果我们自定义一个rt.jar中已有类的同名Java类,会发现JVM可以正常编译,但该类永远无法被加载运行
三、JVM运行时数据区
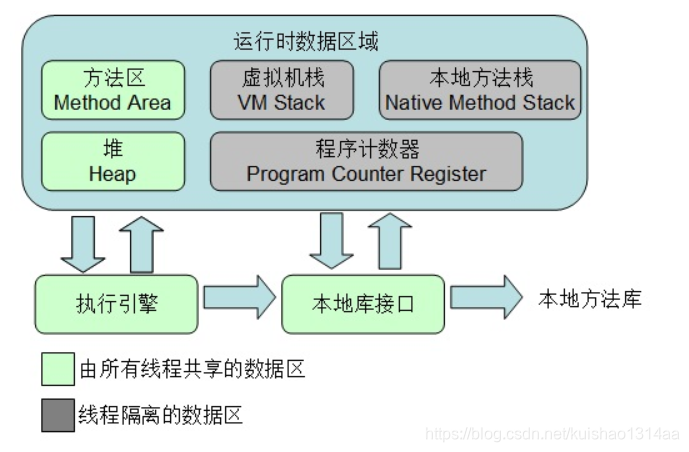
1.堆(Heap)
1)被所有线程共享的一块内存区域,在虚拟机启动时创建;
2)用来存储对象实例;
3)可以通过-Xmx和-Xms控制堆的大小
4) java堆是垃圾收集器管理的主要区域。java堆还可以细分为:新生代(New/Young)、旧生代/年老代(Old/Tenured)
2.方法区(Method Area)
1)被所有线程共享的一块内存区域
2)用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据
3.虚拟机栈(VM Stack)
1)线程私有,生命周期与线程相同
2) 存储方法的局部变量表(基本类型、对象引用)、操作数栈、动态链接、方法出口等信息
4.本地方法栈(Native Method Stack)
与虚拟机栈相似,主要为虚拟机使用到的Native方法服务,在HotSpot虚拟机中直接把本地方法栈与虚拟机栈二合一
5.程序计数器(Program Counter Register)
1)当前线程所执行的字节码的行号指示器
2)当前线程私有
四、JVM常见配置
-Xss:每个线程的java虚拟机内存大小
1.堆设置
-Xms:初始堆大小
-Xmx:最大堆大小
-XX:NewSize=n:设置年轻代大小
-XX:NewRatio=n:设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4
-XX:SurvivorRatio=n:年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5
-XX:MaxPermSize=n:设置持久代大小
2.收集器设置
-XX:+UseSerialGC:设置串行收集器
-XX:+UseParallelGC:设置并行收集器
-XX:+UseParalledlOldGC:设置并行年老代收集器
-XX:+UseConcMarkSweepGC:设置并发收集器
3.垃圾回收统计信息
-XX:+PrintGC
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-Xloggc:filename
4.并行收集器设置
-XX:ParallelGCThreads=n:设置并行收集器收集时使用的CPU数。并行收集线程数。
-XX:MaxGCPauseMillis=n:设置并行收集最大暂停时间
-XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)
5.并发收集器设置
-XX:+CMSIncrementalMode:设置为增量模式。适用于单CPU情况。
-XX:ParallelGCThreads=n:设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数
五、JVM垃圾回收机制
1.Java中的四种引用类型
1)强引用. 这里的o就是一个强引用,也是我们用得最多的引用,在实例化类的时候经常会用到。遇到这类引用,GC(垃圾回收器)是绝对不会回收它的。当遇到内存不足的情况,JVM会抛出OOM异常。所以,在不使用这类对象的时候要注意释放它,以便让系统回收
Object o = new Object();
2)软引用. 这里的s就是一个软引用,它是用来描述一些有用但非必需的对象。如果一个对象只具有软引用,则内存空间足够,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存
SoftReference<String> s = new SoftReference<>(new String("Hello"));
System.out.println(s.get());
3)弱引用。只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存
WeakReference<String> w = new WeakReference<>(new String("Hello"));
System.out.println(w.get());
System.gc();
System.out.println(w.get());
4)虚引用。与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用,一样,在任何时候都可能被垃圾回收器回收。 它唯一的作用就是就是用于追踪,让我们能够在这个对象被回收的时候收到一个通知。
ReferenceQueue<String> queue = new ReferenceQueue<>();
PhantomReference<String> pr = new PhantomReference<>(new String("Hello"), queue);
System.out.println(pr.get());
2.如何判断对象需要被回收
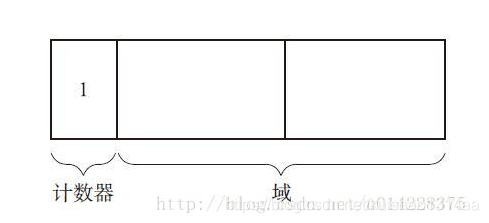
1)引用计数法。 在对象内部会有一个引用计数器,一旦某个地方引用它时,计数器就加1。 计数器表示的是对象的人气指数,也就是有多少程序引用了这个对象(被引用数)。下图是引用计数法中的对象。
、
2)可达性分析法。 所谓可达性分析就是通过一系列被称为“GC Roots”的点作为起始点,从这些节点开始向下搜索,搜索的路径称为引用链,当一个对象到GC Roots不可达的时候,则证明此对象是可回收的
3.垃圾回收算法
回收机制——隔代收集法
新生代:
复制法:新生代活跃对象多,先将内存分为两个部分,From区和To区,两部分大小相等。对象分配时,只会在From区进行分配。复制算法可以分两步,第一步为类似标记清除算法的标记,在From区中,找出所有活动的对象。区别在于第二步。复制算法会把这些活动的对象,复制到To区中,再将原有的From区全部清空,并交换两部分内存的职责,即一次GC后,原有的From区会成为To区,To区相反
优点:效率高 、高速分配、不会发生碎片化;GC后的内存空间是连续的。
缺点:堆使用效率低下,把堆二等分, 真正存放新对象的内存区域会变少,只有一半堆能够存放对象
老年代(永久代):
标记-整理法:分为标记和整理两个阶段: 标记所有从根节点开始的遍历到的存活对象,让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存
标记—清除法:分为标记和清除两个阶段: 标记所有从根节点开始的遍历到的存活对象,在标记完成后,清除所有未被标记的对象
优点:有效利用堆,能够在整个堆中进行操作
缺点:压缩花费时间,清楚和压缩都会搜索堆,浪费时间,没有压缩的话会产生碎片化问题,对象存储不连续。
4.垃圾收集器
|
名称 |
工作区域 |
单线程/多线程 |
垃圾收集算法 |
描述 |
|
Serial收集器 |
新生代 |
单线程 |
复制算法 |
进行垃圾收集时,必须暂停其他所有的工作线程,直到它收集结束 |
|
ParNew收集器 (Serial收集器的多线程版本) |
新生代 |
多线程 |
复制算法 |
并行:指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态; 并发:指用户线程与垃圾收集线程同时执行 |
|
Parallel Scavenge收集器 |
新生代 |
多线程 |
复制算法 |
吞吐量优先收集器 目标:控制吞吐量 |
|
Serial Old收集器 |
老年代 |
单线程 |
标记整理算法 |
主要意义也是在于给Client模式下的虚拟机使用 |
|
Parallel Old收集器 |
老年代 |
多线程 |
标记整理算法 |
Parallel Old 是Parallel Scavenge收集器的老年代版本 1.6之后,“吞吐量优先“收集器组合:Parallel Scavenge + Parallel Old |
|
CMS收集器 |
老年代 |
多线程 |
标记-清除算法 |
目标:最短回收停顿时间 优点:并发收集,低停顿 缺点:CPU资源敏感;无法处理浮动垃圾;内存碎片问题 |
5.内存分配策略
Minor GC 和 Full GC
- Minor GC:回收新生代,因为新生代对象存活时间很短,因此 Minor GC 会频繁执行,执行的速度一般也会比较快。
- Full GC:回收老年代和新生代,老年代对象其存活时间长,因此 Full GC 很少执行,执行速度会比 Minor GC 慢很多
1)对象优先在Eden上分配,当Eden上内存不够时,发起Minor GC
2)大对象和长期存活的对象进入老年代
3) 长期存活的对象将进入老年代
3)调用System.gc()时,建议虚拟机执行Full GC,老年代空间不足也会执行Full GC

















 86万+
86万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









