




在大语言模型的竞争中,数学与代码推理能力已经成为最硬核的“分水岭”。从 OpenAI 最早将 RLHF 引入大模型训练,到 DeepSeek 提出 GRPO 算法,我们见证了强化学习在推理模型领域的巨大潜力。然而,想要复现这些顶尖成果,并不只是“多喂点数据、跑几轮训练”这么简单。现实是,很多中小规模的开源推理模型,在 AIME 这样的高难数学竞赛题、或 LiveCodeBench 这样的复杂代码评测中,依然与闭源 SOTA 存在明显差距。
最近,快手 Klear 语言大模型团队推出了全新的 Klear-Reasoner 模型,基于 Qwen3-8B-Base 打造,在数学与代码的多个权威基准测试中达到同规模模型的 SOTA 水平,并完整公开了训练细节与全流程 pipeline。

-
论文标题:Klear-Reasoner: Advancing Reasoning Capability via Gradient-Preserving Clipping Policy Optimization
-
论文链接:https://arxiv.org/pdf/2508.07629
-
Hugging Face地址:https://huggingface.co/Suu/Klear-Reasoner-8B
-
GitHub地址:https://github.com/suu990901/KlearReasoner/tree/main
Klear-Reasoner 在 AIME2024、AIME2025、LiveCodeBench V5 和 V6 等基准测试中,不仅全面超越同规模的强力开源模型(包括 DeepSeek 蒸馏版 DeepSeek-R1-0528-8B),更是在 AIME2024 上取得了 90.5%、AIME2025 上取得了 83.2% 的惊人成绩,直接登顶 8B 模型榜首。
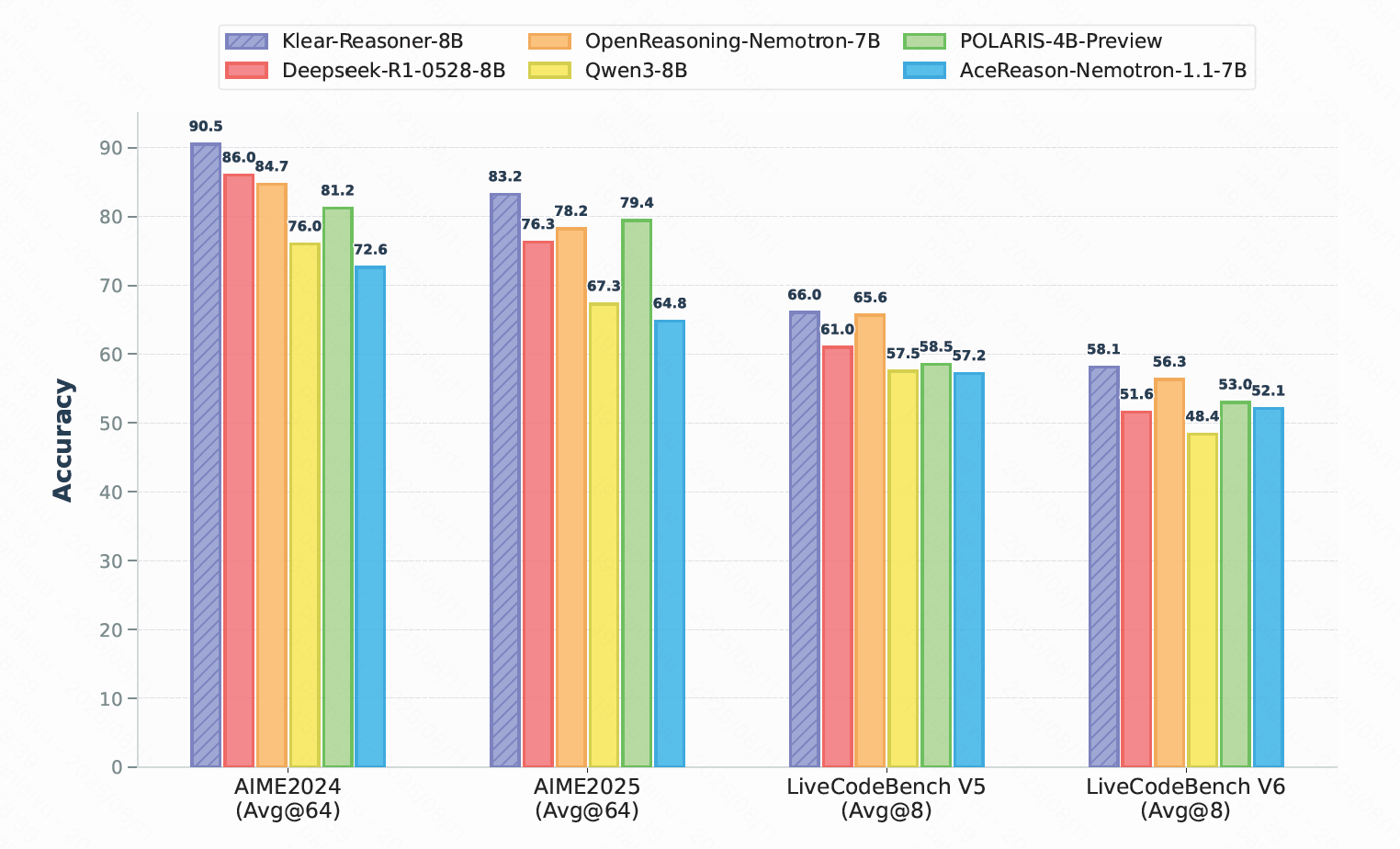
在这些成果的背后,最核心的技术创新是Klear团队提出的 GPPO(Gradient-Preserving Clipping Policy Optimization)算法 ——一种在保留训练稳定性的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4495
4495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









