









准备工作
爬取公众号有几种方法?网上很多可能都已经失效了,比如大名鼎鼎的wechat_articles_spider已失效,现在我们再研究现在可以爬取公众号文章的方法。
今天我们使用登录公众号后台,通过自己的cookie和token来抓取任意公众号的方法。
-
F12-网络 准备,打开写图文页面,点击超链接。
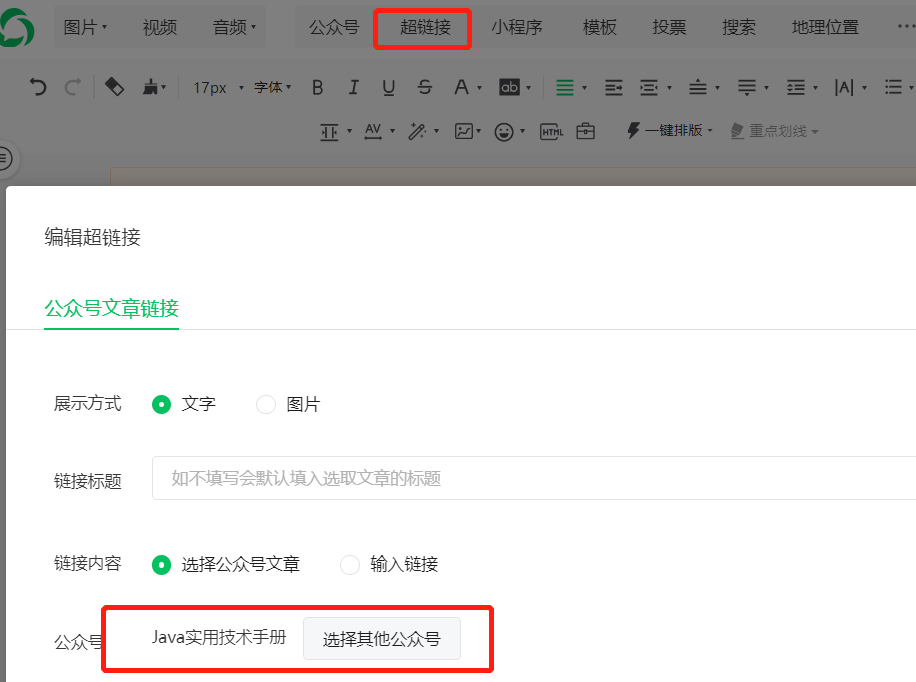
-
这个时候看任意一个链接就能拿到cookie和token。
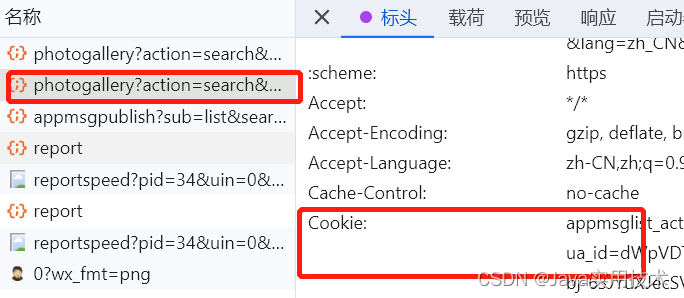
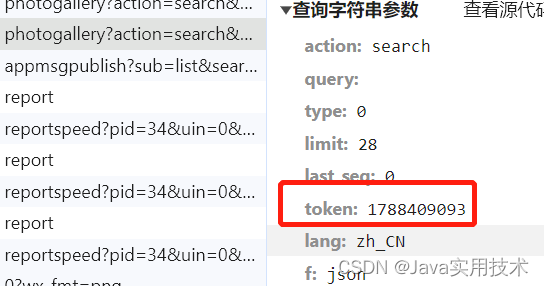
-
选择其他公众号查找,获取它的fakeid,比如"Java实用技术手册",可以看到应该调用了“https://mp.weixin.qq.com/cgi-bin/searchbiz”接口。
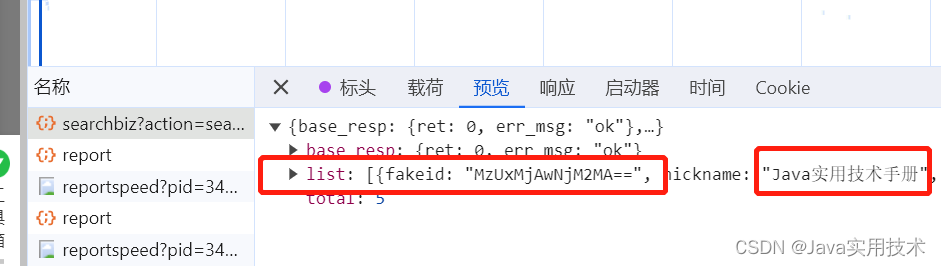
-
当我们选中公众号后,就可以看到文章列表了。这个就是我们要找的爬取接口。
![![[Pasted image 20240122221349.png]]](https://i-blog.csdnimg.cn/blog_migrate/c5315136b63a674f4768416b202bf380.png)
技术实现
技术上分3步,
- 获取目标公众号fakeid。
- 查找目标公众号文章。
- 解析结果输出结果。
代码献上
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import traceback
import requests
from pprint import pprint
'''
日期:2024年2月22日
公众号ID:java-tech
公众号:Java实用技术手册
声明:本文仅供技术研究,请勿用于非法采集,后果自负。
'''
__session = requests.Session()
__headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
}
__params = {
"lang": "zh_CN",
"f": "json",
}
def get_fakeid(nickname, begin=0, count=5):
search_url = "https://mp.weixin.qq.com/cgi-bin/searchbiz"
# 增加/更改请求参数
params = {
"action": "search_biz",
"query": nickname,
"begin": begin,
"count": count,
"ajax": "1",
}
__params.update(params)
try:
search_gzh_rsp = __session.get(search_url, headers=__headers, params=__params)
rsp_list = search_gzh_rsp.json()["list"]
# print(rsp_list)
if rsp_list:
return rsp_list[0].get('fakeid')
return None
except Exception as e:
raise Exception(f'获取公众号{nickname}的fakeid失败,e={traceback.format_exc()}')
def get_articles(nickname, fakeid, begin=0, count=5):
art_url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
art_params = {
"query": '',
"begin": begin,
"count": count,
"type": 9,
"action": 'list_ex',
"fakeid": fakeid,
}
__params.update(art_params)
try:
rsp_data = __session.get(art_url, headers=__headers, params=__params)
if rsp_data:
msg_json = rsp_data.json()
# pprint(msg_json)
if 'app_msg_list' in msg_json.keys():
result = [item.get('title') + ': ' + item.get('link') for item in msg_json.get('app_msg_list') ]
# return msg_json.get('app_msg_list')
return result
else:
return []
except Exception as e:
raise Exception(f'获取公众号{nickname}的文章失败,e={traceback.format_exc()}')
def main():
# 登录微信公众号平台,获取微信文章的cookie/token
cookie = ""
nickname = "Java实用技术手册"
__headers["Cookie"] = cookie
__params["token"] = token
fakeid = get_fakeid(nickname)
print(fakeid)
article_data = get_articles(nickname, fakeid)
pprint(article_data)
if __name__ == '__main__':
main()
最后结果
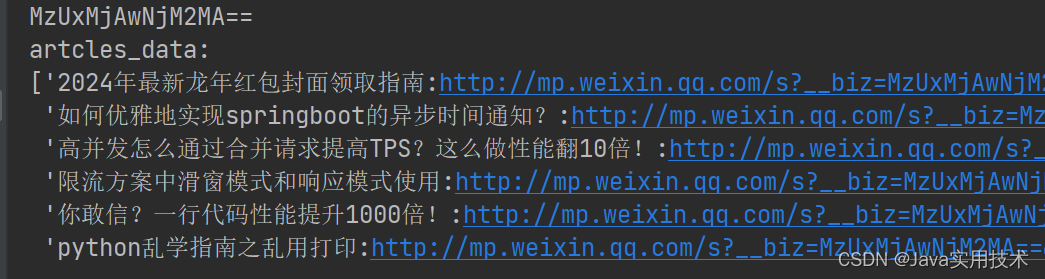
声明:本文仅供技术研究,请勿用于非法采集,后果自负。
技术研究时间:2024年4月3日
感谢@HerrSure 对代码勘误。

















 966
966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









