



 本文介绍了一个简单的Python爬虫实现过程,该爬虫用于抓取百度百科词条,并详细展示了从URL管理到数据输出的完整代码。适合初学者学习。
本文介绍了一个简单的Python爬虫实现过程,该爬虫用于抓取百度百科词条,并详细展示了从URL管理到数据输出的完整代码。适合初学者学习。
ps:本文代码参照慕课网教学视频《python开发简单爬虫》,网址:https://www.imooc.com/learn/563
个人觉得是个很好的初学爬虫的教程,,它可以让你遇到很多问题。。。
下面是代码部分。
1.spider-main.py
# coding=gbk
from baidu_spider import url_manager, html_downloader, html_parser,\
html_outputer
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
class SpiderMain(object):
def __init__(self): #创建属性 创建四个对象
self.urls = url_manager.UrlManager() #需要引用和创建class
self.downloader = html_downloader.HtmlDownloader()
self.parser = html_parser.HtmlParser()
self.outputer = html_outputer.HtmlOutputer()
def craw(self, root_url): #创建调用方法
count = 1 #记录url的数字
self.urls.add_new_url(root_url) #需要将待爬url添加进url管理器,各个方法还需创建
while self.urls.has_new_url(): #当url管理器中有待爬url时启动循环
try: #可能存在异常,加入try块
new_url = self.urls.get_new_url() #获取一个待爬url
print('craw %d : %s' % (count,new_url))
html_cont=self.downloader.downloader(new_url) # 下载这个url页面
new_urls,new_data = self.parser.parse(new_url,html_cont) #传入解析器
self.urls.add_new_urls(new_urls) #将相关的url传入url管理器
self.outputer.collect_data(new_data) #进行数据收集
if count == 100:
break
count= count + 1
except:
print("craw failed")
self.outputer.output_html()
if __name__=="__main__": #main函数
root_url ="https://baike.baidu.com/item/Python/407313?fr=aladdin" #爬取的入口url
obj_spider = SpiderMain() # 需先创建Spider Main类
obj_spider.craw(root_url) #调用craw方法启功爬虫,就需要先创建craw方法
2.url_manager.py (url管理器)
# coding:utf8
# 写成coding=gbk也可以
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def add_new_url(self,url):
if url is None:
return
if url not in self.new_urls and url not in self.old_urls:
self.new_urls.add(url)
def add_new_urls(self,urls):
if urls is None or len(urls) ==0:
return
for url in urls:
self.add_new_url(url)
def has_new_url(self):
return len(self.new_urls) !=0
def get_new_url(self):
new_url =self.new_urls.pop()
self.old_urls.add(new_url)
return new_url3.html_downloader.py (url下载器)
# coding:utf8
from urllib.request import urlopen # 区分python2.x urllib2 ,python3对urllib,urllib2进行了调整,具体可百度
class HtmlDownloader(object):
def downloader(self,url):
if url is None:
return None
response = urlopen(url) #因为urllib调整了,所有此部分与视频不同
if response.getcode( ) != 200:
return None
return response.read()import re
import urllib.parse # python2.x 为 urlparse,这部分python3.x也做了修改
from bs4 import BeautifulSoup
class HtmlParser(object):
def _get_new_urls(self,page_url,soup):
new_urls=set()
links=soup.find_all('a',href=re.compile(r"/item/\d+")) #正则表达式,网页做了修改,红字部分现在与视频不同了,具体可以检查元素
for link in links:
new_url=link['href']
new_full_url=urllib.parse.urljoin(page_url, new_url)
new_urls.add(new_full_url)
return new_urls
def _get_new_data(self,page_url,soup):
res_data={}
res_data['url']=page_url
title_node=soup.find('dd',class_='lemmaWgt-lemmaTitle-title').find('h1')
res_data['title']=title_node.get_text()
summary_node=soup.find('div',class_='lemma-summary')
if summary_node is None:
return
res_data['summary']=summary_node.get_text()
return res_data
def parse(self,page_url,html_cont):
if page_url is None or html_cont is None:
return
soup=BeautifulSoup(html_cont,'html.parser')
new_urls=self._get_new_urls(page_url,soup) #需创建方法
new_data=self._get_new_data(page_url,soup)
return new_urls,new_data # coding:utf8
class HtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self,data):
if data is None:
return
self.datas.append(data)
def output_html(self):
fout = open('output4.html','w',encoding = 'utf-8') #创建一个html储存下载的数据,原视频没有红色部分
fout.write("<html>")
fout.write("<body>")
fout.write("<table>")
for data in self.datas:
fout.write("<tr>")
fout.write("<td>%s</td>" % data['url'])
fout.write("<td>%s</td>" % data['title']) #原视频这两句后有encide(utf-8),不会报错,但输出的数据是乱码
fout.write("<td>%s</td>" % data['summary'])
fout.write("</tr>")
fout.write("</table>") #输出为表格形式
fout.write("</body>")
fout.write("</html>")
fout.close()下面是运行结果: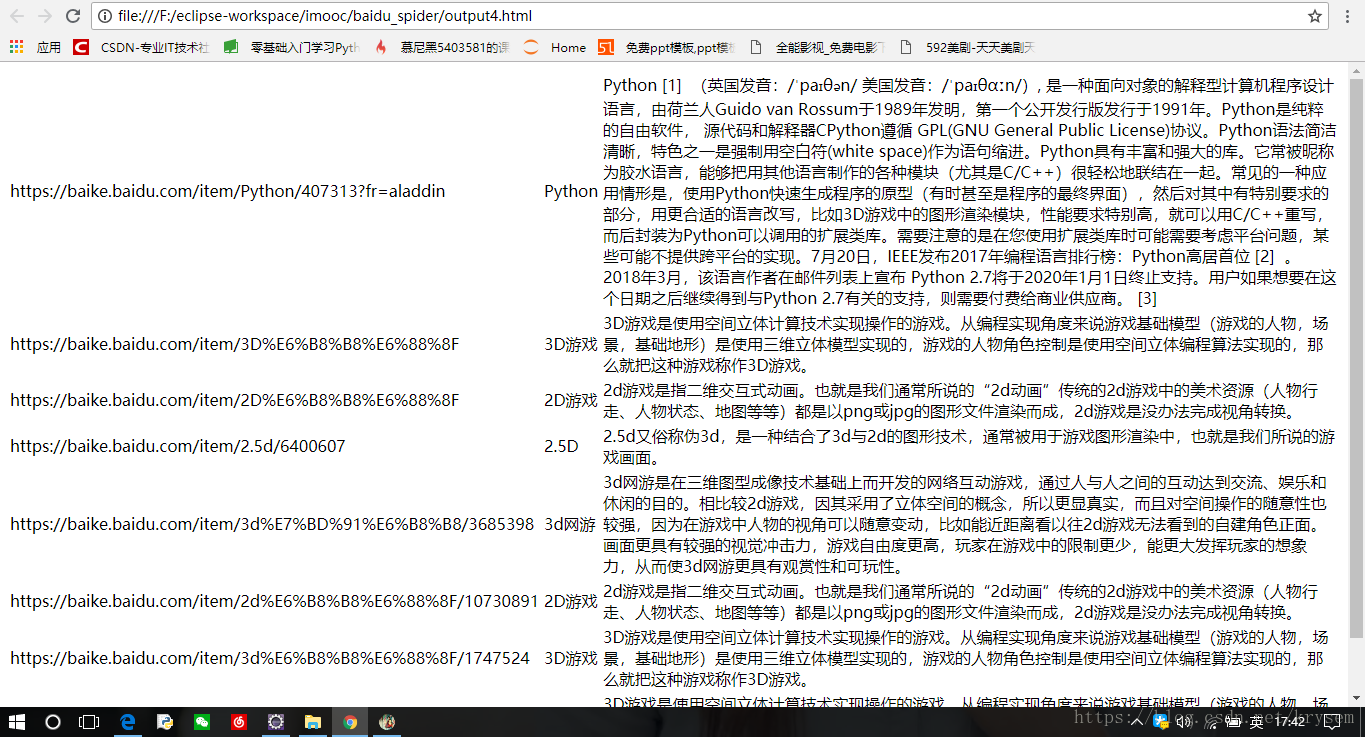 博主完全属于python小白,更是爬虫小白,这只是模仿视频做的东西都错误百出,花了很久才完成,很希望能遇到和我一样犯错的初学者啊,找到共同学习的小伙伴,一起学习,一起进步,一起开车。。。嘀嘀嘀~也希望若有大神们看到了小弟的文章,,可以不嫌弃,带带我,因为真的有很多东西不懂,比如那编码什么的为什么有时候需要utf-8,有时候又不要,对正则表,达式也好像似懂非懂,诚心求教,随意批评。
博主完全属于python小白,更是爬虫小白,这只是模仿视频做的东西都错误百出,花了很久才完成,很希望能遇到和我一样犯错的初学者啊,找到共同学习的小伙伴,一起学习,一起进步,一起开车。。。嘀嘀嘀~也希望若有大神们看到了小弟的文章,,可以不嫌弃,带带我,因为真的有很多东西不懂,比如那编码什么的为什么有时候需要utf-8,有时候又不要,对正则表,达式也好像似懂非懂,诚心求教,随意批评。

















 1941
1941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









