



1.MapReduce的原理
把要执行的功能通过jar包的形式发布到各节点,由各个节点来执行jar包的功能
传统分布式计算是把其他节点的数据集中在计算节点,由计算节点统一执行
2. MapReduce设计构思
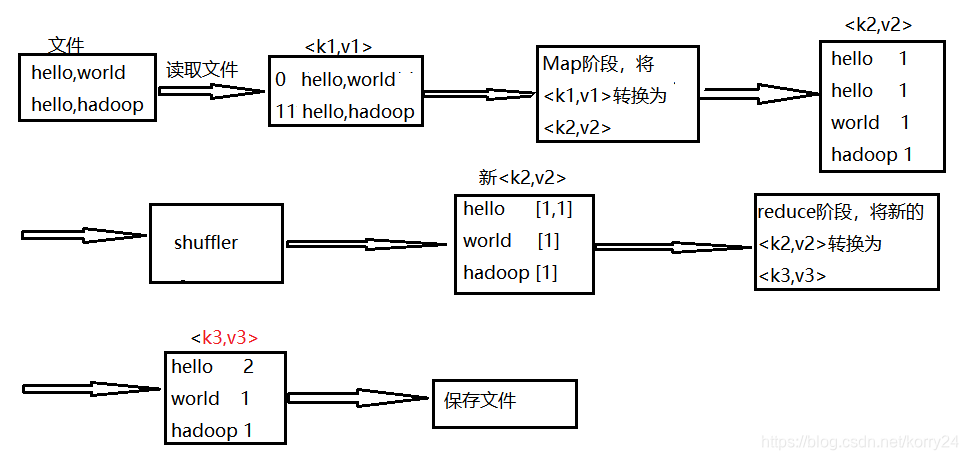
3. MapReduce编程规范
- Map阶段两个步骤
1).设置InputFormat类,将数据切分为key-value(k1和v1)对,输入到第二步
2).自定义Map逻辑,将第一步的结果转换为另外的key-value(k2和v2)对,输出结果 - Shuffle阶段的四个步骤
3).对输出的key-value进行分区
4).对不同分区的数据按照相同的key排序
5).(可选)对分组过的数据进行初步规约,降低数据的网络拷贝
6).对数据进行分组,相同key的value放在同一个集合中 - Reduce阶段两个步骤
7).对多个Map任务的结果进行排序以及合并,编写Reduce函数实现自己的逻辑,对输入的key-value进行处理,转换为新的key-value(k3和v3)输出
8).设置OutputFormat处理并保存Reduce输出的key-value数据
4. Shuffle
- 分区:partitioner
MapTask后的数据,即<k2,v2>,进行分区标记,后面会根据不同的标记进入不同的ReduceTask(默认是根据hashcode取余来分组,取余的结果作为分区编号,也是reducer的编号)
分区步骤:mapper → partitioner → reduce → 主类 - 排序:WritableComparable
mapTask完成后,经过分区从环形缓冲区溢出的小文件进行排序
序列化:write
反序列化:readFields
排序:compareTo - 规约:combiner
对map端每一个MapTask的输出先做一次合并,再传递给Reducer,以减少map和reducer节点之间的数据传输量
combiner的父类是Reducer,在每一个maptask所在的节点运行,其实等同于将reducer放在map的节点使用 - 分组:在reduce前,将相同key的数据组在一起,跟规约的作用相同。可以减少map到reduce之间数据的传输量,增加传输效率
5. MapReduce的整个流程
-
client将数据切片(分block) 输出<k1,v1>
-
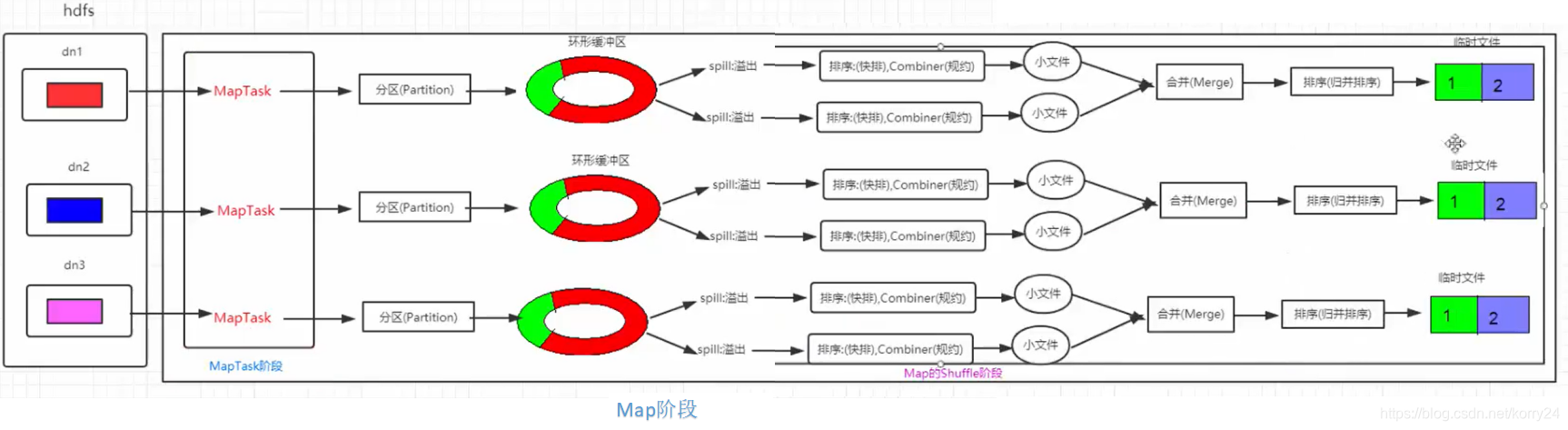
Map阶段
→ 每个block的数据进入map的一个MapTask 输出<k2,v2> → 数据分区(Partitioner)做出分区标记 → 数据进入环形缓冲区(默认100M,80%溢出)
→ 数据溢出形成小文件(小文件存储时会进行排序(快排)和规约) → 小文件合并成一个临时文件(进行排序(归并))
-
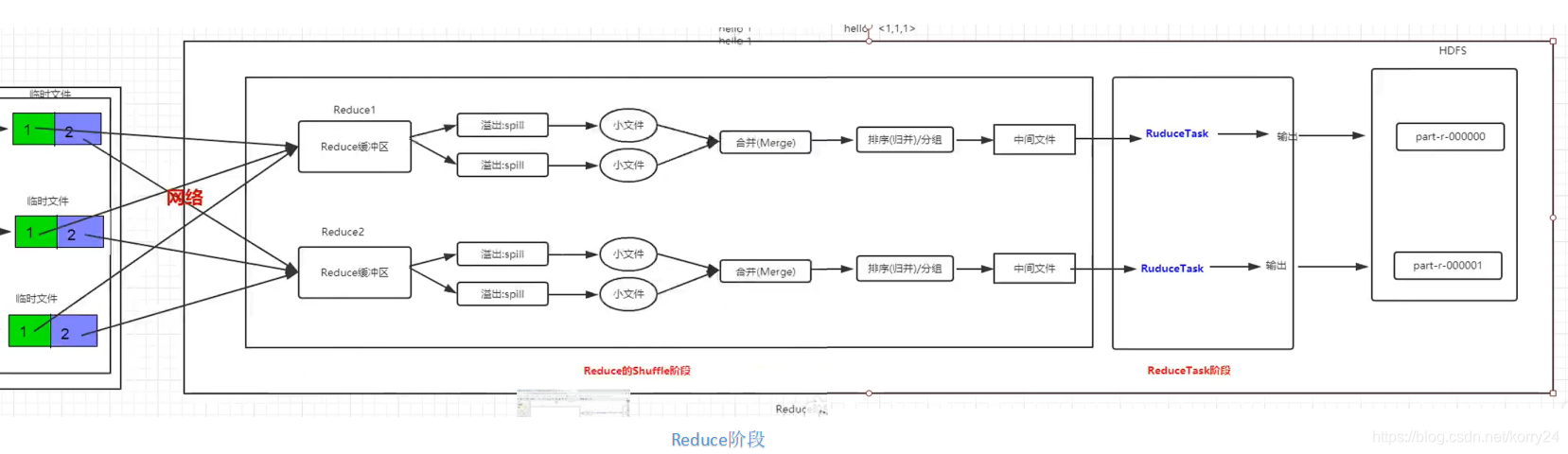
Reduce阶段
→ 数据根据之前的分区进入不同的Reduce缓冲区 → 溢出成小文件 → 小文件合并成中间文件(排序(归并),分组) 输出新的<k2,v2>
→ 数据进入不同的ReduceTask 输出<k3,v3> → 根据分组不同生成不同的目标文件

















 2230
2230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









