







 本文介绍了微服务中防止雪崩效应的熔断机制,以Spring Cloud的Hystrix为例,详细讲解了Hystrix的原理、工作模式、服务熔断及其实现方法。Hystrix通过服务隔离、容错管理和回退策略,确保了系统在服务故障时的稳定性和弹性。
本文介绍了微服务中防止雪崩效应的熔断机制,以Spring Cloud的Hystrix为例,详细讲解了Hystrix的原理、工作模式、服务熔断及其实现方法。Hystrix通过服务隔离、容错管理和回退策略,确保了系统在服务故障时的稳定性和弹性。
哈喽大家好我是yangerkong!今天跟大家探讨下微服务中的熔断机制。
本文中部分介绍和部分图片摘自官网,官网地址:Home · Netflix/Hystrix Wiki · GitHub
SpringCloud之服务熔断与降级
熔断器原理介绍
雪崩效应(熔断器背景)
在微服务系统中,一个应用由多个服务组成。相互依赖,依赖关系错综复杂。一个业务操作会由多个不同的服务共同完才。所以这些 依赖服务的稳定性对系统的影响非常大。但是由于系统存在很多不可控问题:网络延时,资源繁忙,服务宕机等。若有一个服务因为故障原因,可能会导致整个服务崩溃。
我们先来看一张图:
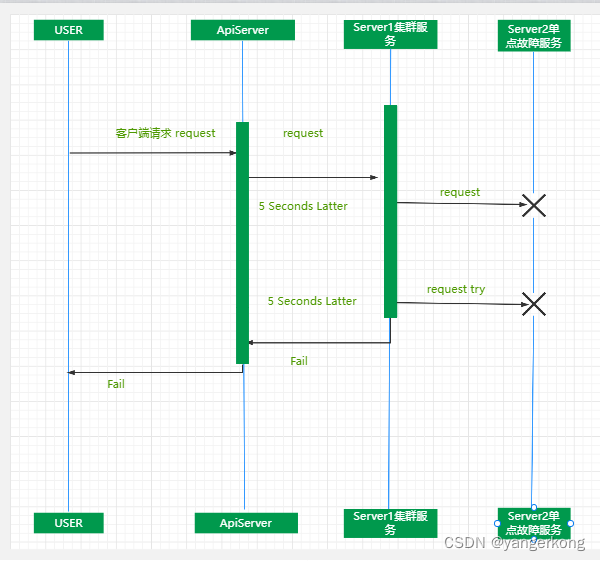
上图所示:举例说明了依赖服务由于支撑服务暂时不可用问题导致的系统问题
用户请求由于server2服务不可用导致请求需要等待10秒才能响应(假设app端请求不超时),那么之后所有请求都会阻塞,堆积直到系统上限直接打死所有服务。
这个过程就称为"雪崩效应",为了防止此类事件发生,微服务架构引入了"熔断器"的一些列的服务容错和保护措施。
Spring Cloud Hystrix
Hystrix简介
Hystrix是Netflix开源的一款分布式容错框架和保护组件,也是Spring Cloud的重要组件之一。
Spring Cloud Hystrix是基于Netfilx公司的开源组件Hystrix实现的。提供熔断器功能,能够有效避免故障在微服务系统中蔓延,导致雪崩效应的产生;以提高微服务系统的弹性。
Hystrix容错
资源隔离:防止单个服务故障耗尽系统中所有的线程资源。
服务降级:当某个服务发生了故障,不让服务调用方一直等待,在可能的情况下进行回退并优雅地降级。提供降级方案在请求失败后,提供一个设计好的降级方案,当请求失败后调用此方法。
服务熔断:使用熔断机制,在复杂的分布式系统中停止级联故障。提供熔断器故障监控组件Hystrix Dashboard,随时监控熔断器的状态。
当服务请求一切正常时,请求流如下所示:
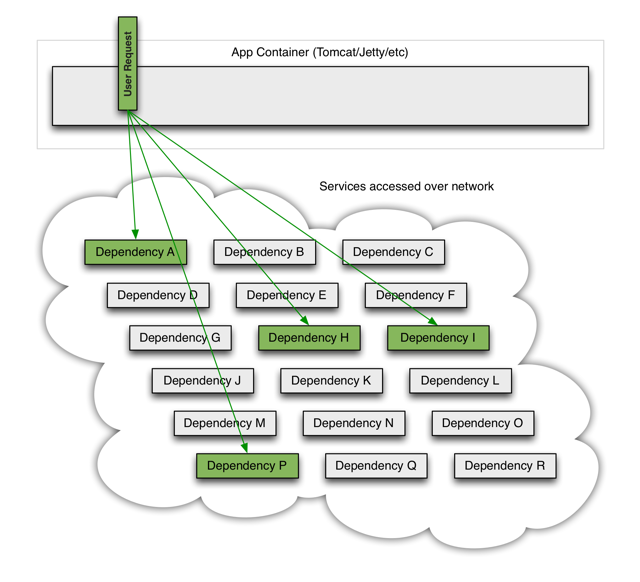
当微服务系统请求故障时,它可以阻塞整个用户请求:
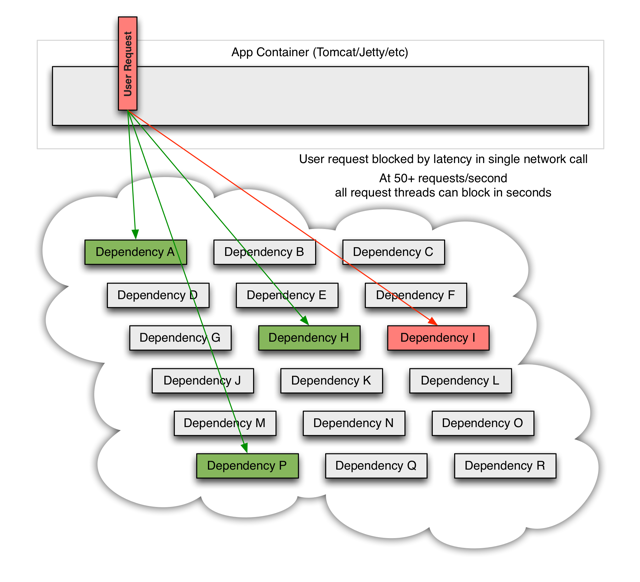
在高流量请求服务的情况下因某服务故障,可能导致所有服务器上的所有资源在几秒钟内饱和。
应用程序中通过网络或进入可能导致网络请求的客户端库的每一点都是潜在故障的来源。比故障更糟糕的是,这些应用程序还会导致服务之间的延迟增加,从而备份队列、线程和其他系统资源,从而导致更多跨系统的级联故障。

Hystrix是这样做的:
将所有对外部系统(或“依赖项”)的调用包装在一个HystrixCommand或HystrixObservableCommand对象中,该对象通常在单独的线程中执行(这是命令模式的一个例子)。
超时调用的时间超过您定义的阈值。有一个默认值,但是对于大多数依赖项,您可以通过“属性”的方式自定义设置这些超时,这样每个依赖项的性能就会略高于99.5%。
为每个依赖项维护一个小的线程池(或信号量);如果该依赖项已满,那么指向该依赖项的请求将立即被拒绝,而不是排队。度量成功、失败(客户端抛出的异常)、超时和线程拒绝。
触发一个断路器,在一段时间内停止对特定服务的所有请求,如果服务的错误百分比超过一个阈值,可以手动停止,也可以自动停止。当请求失败、被拒绝、超时或短路时执行回退逻辑。几乎实时地监控指标和配置更改。
使用Hystrix包装每个底层依赖项时,上面图表中所示的体系结构将更改为类似于下面的图表。每个依赖项都是相互隔离的,在发生延迟时,它所能饱和的资源受到限制,并包含在当依赖项中发生任何类型的故障时决定做出何种响应的回退逻辑中:
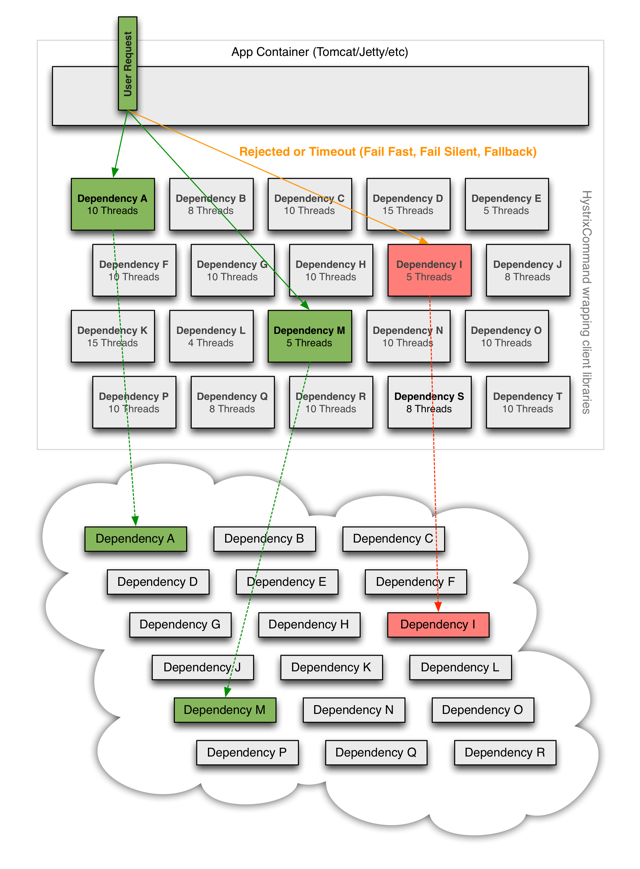
Hystrix工作原理
下面的图显示了当你通过Hystrix向一个服务依赖项发出请求时会发生什么:
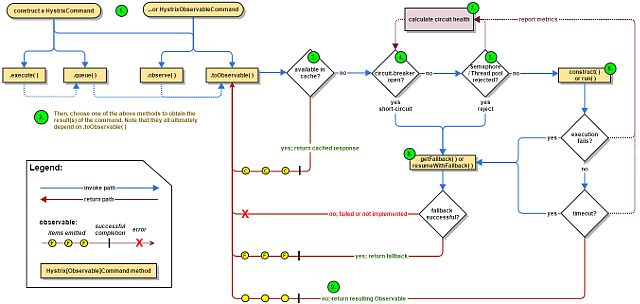
以下部分将更详细地解释这个流程:
- 构造一个HystrixCommand或hystrixobservableccommand对象
- 执行命令
- 缓存是否响应
- 电路是否开放
- 线程池/队列/信号量是否已满
- HystrixObservableCommand.construct()或HystrixCommand.run ()
- 计算电路健康状态
- 得到回退
- 返回成功响应
如果Hystrix命令成功,它将以Observable的形式返回响应或响应给调用者:
流程1-9详细介绍 官网地址如下:How it Works · Netflix/Hystrix Wiki · GitHub
Hystrix服务熔断
熔断机制是为了应对雪崩效应而出现一种微服务链路保护机制。
熔断器最重要的在于保证服务调用者在调用异常服务时,快速返回结果,避免大量的同步等待。并且在一段时间后熔断器能自动判断服务恢复调用的可能。
Hystrix工作模式
在熔断器中,最重要的一个概念是:服务器的健康情况。熔断器的设计基本上都是围绕该概念进行的。健康情况=请求失败数/请求总数
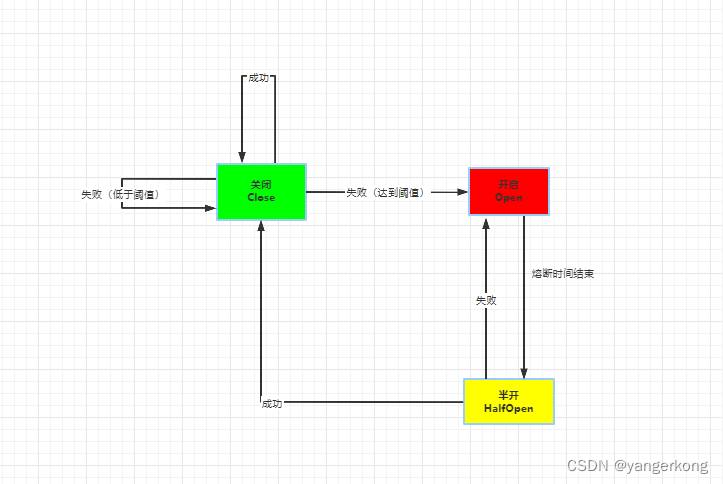
如图所示:定义了熔断器的工作模式和开关相互转换的逻辑。
熔断器定义了三种状态来决定是否允许请求通过:
1.熔断关闭(Close):关闭状态时,允许请求通过,调用服务方可以正常调用服务
2.熔断开启(Open):在固定时间内如果接口调用出错率达到一个阈值,熔断器会将状态设置为开启,在该状态下请求被禁止通过。熔断器会执行降级(FallBack)方法。
3.半熔断(HalfOpen):熔断开启一段时间后,熔断器会进入半开状态,这时会允许部分请求调用服务,并监听是否调用成功,如果成功率达到预期说明服务正常恢复,熔断器恢复到关闭状态( Close),如果成功率很低达不到预期,熔断器重新设置为开启状态(Open)
当微服务系统的某个微服务故障或响应时间太长,为了保护系统的服务整体可用性,熔断器会暂时切断对该服务的请求调用,熔断器及时作出向服务调用方返回一个符合预期的,可处理的降级响应(FallBack),而不是让用户长时间的等待或者抛出用户无法处理的异常。熔断状态是暂时的,在熔断一定时间后,熔断器会再次检测该微服务是否恢复正常,若恢复正常则恢复调用链路。这样保证了服务提供方不会对系统资源长时间的,不必要的占用,避免故障在微服务系统中的蔓延,防止雪崩效应的产生。
Hystrix实现服务熔断机制
Spring Cloud中熔断机制是通过Hystrix实现的,Hystrix监控微服务调用情况,当调用失败率达到一定阈值,熔断机制就会启动。
- 当服务的调用出错率超过Hystirx规定的出错比率(默认为50%),熔断器状态进入开启状态。
- 熔断器进入开启状态后,Hystrix会启动一个休眠时间窗,在这个时间窗内,该服务的提前设定好的降级逻辑会临时充当业务主逻辑,而原来的业务主逻辑不可用。
- 当有请求再次调用该服务时,会直接调用降级逻辑快速返回失败响应,以避免系统雪崩。
- 当休眠时间窗到期后,熔断器会进入半开状态,允许部分请求进行对该服务调用,并监控其成功率。
- 如果调用成功率达到预期,则服务恢复正常,熔断器进入关闭状态,服务链路恢复。否则肉熔断器将进入开启状态,休眠时间窗口重新计时。
Hystrix熔断实现
如何集成Hystrix:在网关项目中集成Hystrix
1.pom.xml配置maven依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>2. application.yml配置
server:
port: 8082
spring:
application:
name: msa-eureka-gateway
# 注册服务到eureka
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
# 配置eureka上服务的默认描述信息
instance:
instance-id: springcloud-provider-hystrix
# 显示访问路径的ip地址
prefer-ip-address: true3.创建测试controller
@RestController
public class TestController {
@GetMapping("/testHystrix")
@HystrixCommand(fallbackMethod = "getHystrix")
public User user(String id){
if(StringUtils.isBlank(id))
{
throw new RuntimeException(" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2237
2237

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











